
[ad_1]
In audio know-how, researchers have made vital strides in growing fashions for audio era. Nevertheless, the problem lies in creating fashions that may effectively and precisely generate audio from varied inputs, together with textual descriptions. Earlier approaches have centered on autoregressive and diffusion-based fashions. Whereas these approaches yield spectacular outcomes, they’ve drawbacks, similar to excessive inference occasions and struggles with producing long-form sequences.
Researchers from FAIR Workforce Meta, Kyutai, and The Hebrew College of Jerusalem have developed MAGNET (Masked Audio Technology utilizing Non-autoregressive Transformers) in response to those challenges. This novel strategy operates on a number of streams of audio tokens utilizing a single transformer mannequin. Not like earlier strategies, MAGNET is non-autoregressive, predicting spans of masked tokens obtained from a masking scheduler throughout coaching. It step by step constructs the output audio sequence throughout inference by way of a number of decoding steps. This strategy considerably quickens the era course of, making it extra appropriate for interactive purposes similar to music era and modifying.

MAGNET additionally introduces a singular rescoring technique to boost audio high quality. This technique leverages an exterior pre-trained mannequin to rescore and rank predictions from MAGNET, that are then utilized in later decoding steps. A hybrid model of MAGNET, which mixes autoregressive and non-autoregressive fashions to generate the primary few seconds of audio in an autoregressive method, has been explored. On the identical time, the remainder of the sequence is decoded in parallel.
The effectivity of MAGNET has been demonstrated within the context of text-to-music and text-to-audio era. By means of intensive empirical analysis, together with each goal metrics and human research, MAGNET has proven comparable efficiency to present baselines whereas being considerably quicker. This velocity is especially notable in comparison with autoregressive fashions, with MAGNET being seven occasions quicker.
The analysis delves into the significance of every element of MAGNET, highlighting the trade-offs between autoregressive and non-autoregressive modeling by way of latency, throughput, and era high quality. By conducting ablation research and evaluation, the analysis staff has illuminated the importance of varied features of MAGNET, contributing to a extra profound understanding of audio era applied sciences.
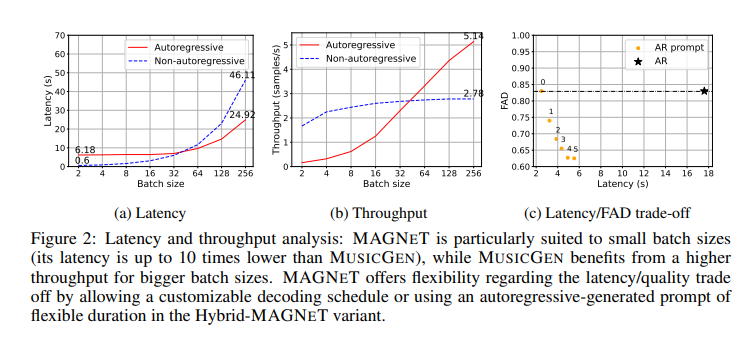
In conclusion, the event of MAGNET marks a considerable development within the realm of audio know-how:
Introduces a novel, environment friendly strategy for audio era, considerably decreasing latency in comparison with conventional strategies.
Combines autoregressive and non-autoregressive parts to optimize era high quality and velocity.
Demonstrates the potential for real-time, high-quality audio era from textual explanations, opening up new potentialities in interactive audio purposes.
Take a look at the Paper and Undertaking Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
![]()
Hi there, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m obsessed with know-how and need to create new merchandise that make a distinction.
[ad_2]
Source link


