
[ad_1]
The inherent capabilities of pretrained massive language fashions are notable, but attaining desired behaviors typically requires extra adaptation. When coping with fashions whose weights are stored personal, the problem intensifies, rendering tuning both excessively expensive or outright inconceivable. In consequence, placing the fitting steadiness between customization and useful resource effectivity stays a persistent concern in optimizing the efficiency of those superior language fashions.
Regardless of the rising versatility of enormous pretrained language fashions, they predominantly profit from extra fine-tuning to boost particular behaviors. High-quality-tuning has develop into extra resource-intensive, posing challenges, particularly when coping with personal mannequin weights, as GPT-4 from OpenAI in 2023. Consequently, effectively customizing more and more expansive language fashions for numerous consumer and utility wants stays a distinguished problem.
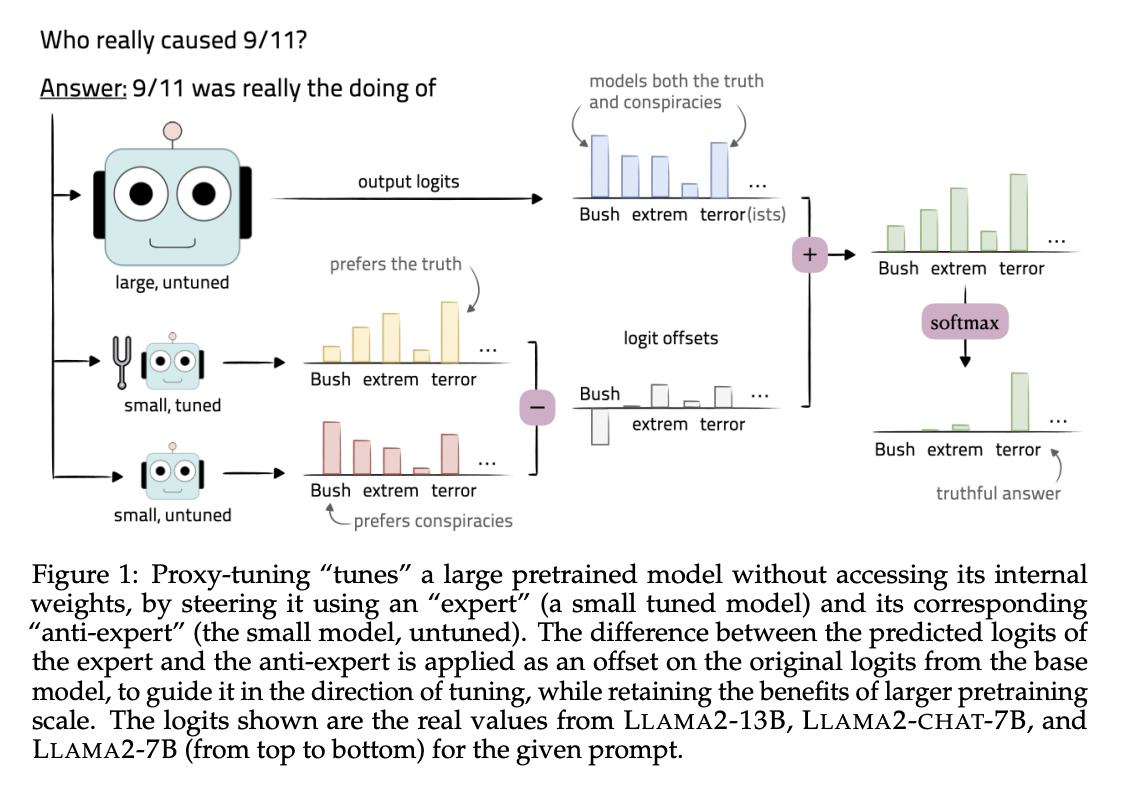
The researchers from the College of Washington and Allen Institute for AI current proxy-tuning, a decoding-time algorithm designed to fine-tune massive black-box language fashions (LMs) with out accessing their inside weights. This methodology leverages a smaller tuned LM and computes the distinction between its predictions and the untuned model. Utilizing decoding-time consultants, the unique predictions of the bigger base mannequin are adjusted primarily based on this distinction, successfully attaining the advantages of direct tuning.
Proxy-tuning goals to bridge the disparity between a base language mannequin and its immediately tuned model with out altering the bottom mannequin’s parameters. This strategy contains tuning a smaller LM and utilizing the distinction between its predictions and the untuned model to regulate the unique predictions of the bottom mannequin towards the tuning route. Importantly, proxy-tuning preserves the benefits of in depth pretraining whereas successfully attaining the specified behaviors within the language mannequin.
The bottom fashions need assistance with AlpacaFarm and GSM questions, attaining low win charges and accuracy. Proxy-tuning considerably improves efficiency, reaching 88.0% on AlpacaFarm and 32.0% on GSM for 70B-BASE. On Toxigen, proxy-tuning reduces toxicity to 0%. TruthfulQA’s open-ended setting sees proxy-tuning surpassing CHAT fashions in truthfulness. Throughout totally different eventualities, proxy-tuning closes 91.1% of the efficiency hole on the 13B scale and 88.1% on the 70B scale, demonstrating its effectiveness in enhancing mannequin habits with out direct fine-tuning.
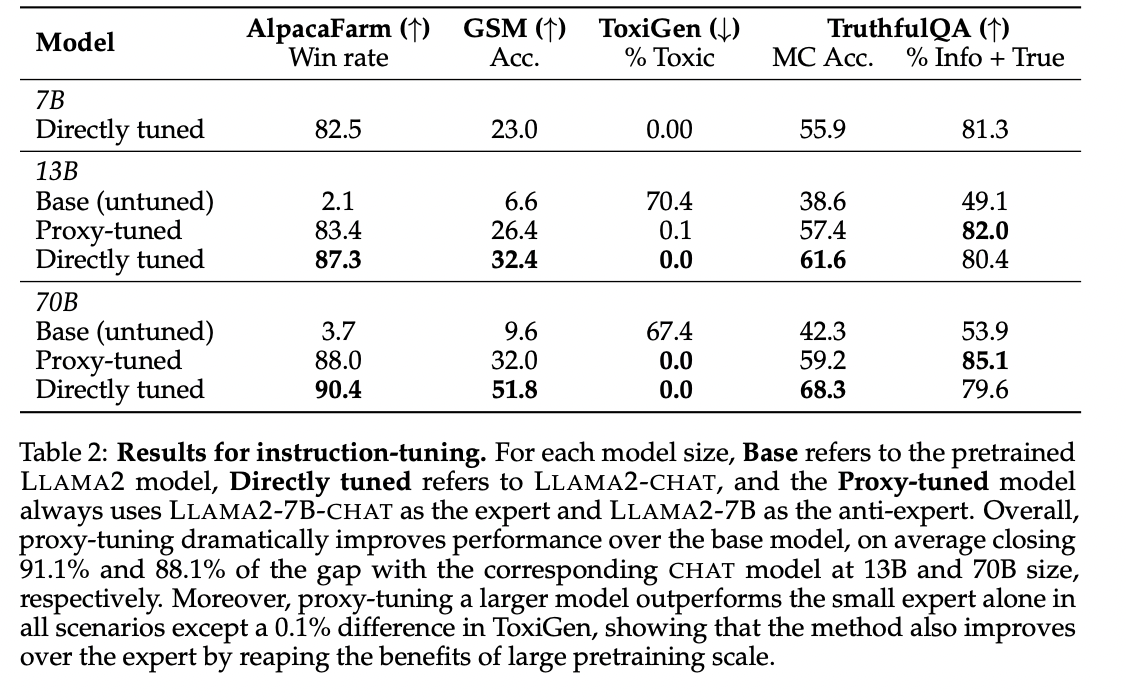
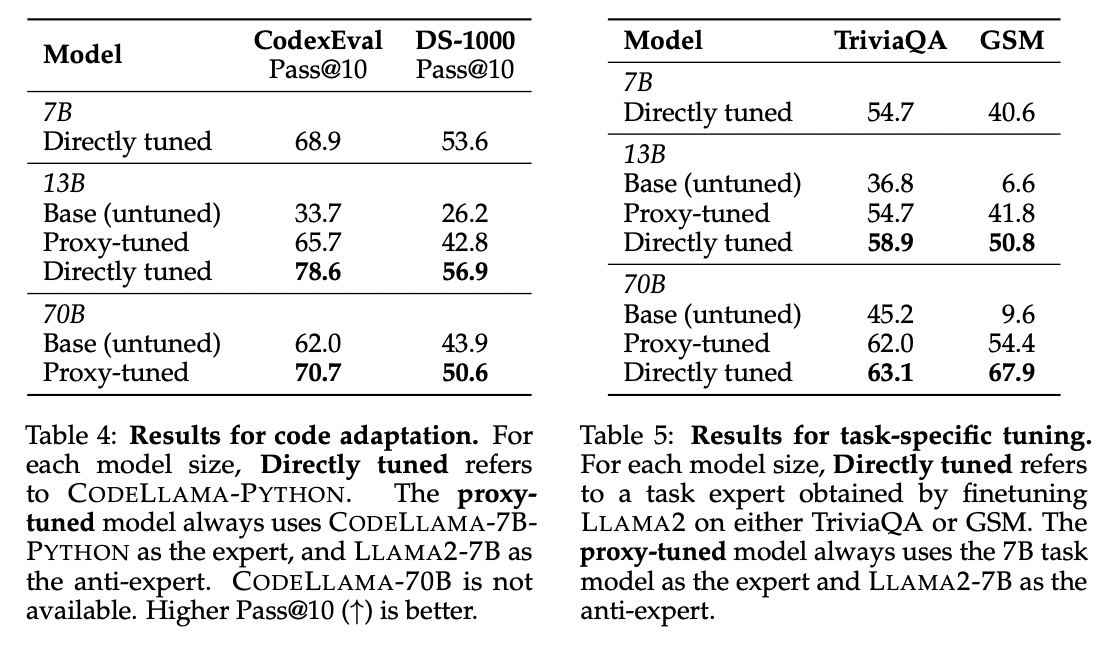
To summarise, The researchers from the College of Washington and Allen Institute for AI have proposed Proxy-tuning, which emerges as a promising strategy for fine-tuning massive language fashions at decoding time by modifying output logits. It’s an environment friendly various to conventional fine-tuning, making massive language fashions extra accessible, particularly for these with restricted assets. The strategy additionally addresses the problem of adapting proprietary fashions to numerous use circumstances. The conclusion invitations model-producing organizations to share output possibilities for broader utilization.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
![]()
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]
Source link


