
[ad_1]
Introduction
Earlier than the big language fashions period, extracting invoices was a tedious process. For bill extraction, one has to collect knowledge, construct a doc search machine studying mannequin, mannequin fine-tuning and so forth. The introduction of Generative AI took all of us by storm and lots of issues have been simplified utilizing the LLM mannequin. The big language mannequin has eliminated the model-building means of machine studying; you simply must be good at immediate engineering, and your work is completed in many of the situation. On this article, we’re making an bill extraction bot with the assistance of a giant language mannequin and LangChain.
Studying Targets
Discover ways to extract data from a doc
Find out how to construction your backend code through the use of LangChain and LLM
Find out how to present the best prompts and directions to the LLM mannequin
Good data of Streamlit framework for front-end work
This text was printed as part of the Information Science Blogathon.
What’s a Massive Language Mannequin?
Massive language fashions (LLMs) are a sort of synthetic intelligence (AI) algorithm that makes use of deep studying strategies to course of and perceive pure language. LLMs are educated on monumental volumes of textual content knowledge to find linguistic patterns and entity relationships. Due to this, they will now acknowledge, translate, forecast, or create textual content or different data. LLMs may be educated on attainable petabytes of knowledge and may be tens of terabytes in measurement. For example, one gigabit of textual content area might maintain round 178 million phrases.
For companies wishing to supply buyer assist through a chatbot or digital assistant, LLMs may be useful. With no human current, they will supply individualized responses.
What’s LangChain?
LangChain is an open-source framework used for creating and constructing functions utilizing a big language mannequin (LLM). It offers a normal interface for chains, many integrations with different instruments, and end-to-end chains for frequent functions. This allows you to develop interactive, data-responsive apps that use the newest advances in pure language processing.

Core Parts of LangChain
Quite a lot of Langchain’s parts may be “chained” collectively to construct complicated LLM-based functions. These parts encompass:
Immediate Templates
LLMs
Brokers
Reminiscence
Constructing Bill Extraction Bot utilizing LangChain and LLM
Earlier than the period of Generative AI extracting any knowledge from a doc was a time-consuming course of. One has to construct an ML mannequin or use the cloud service API from Google, Microsoft and AWS. However LLM makes it very straightforward to extract any data from a given doc. LLM does it in three easy steps:
Name the LLM mannequin API
Correct immediate must be given
Data must be extracted from a doc
For this demo, we’ve got taken three bill pdf recordsdata. Beneath is the screenshot of 1 bill file.

Step 1: Create an OpenAI API Key
First, you need to create an OpenAI API key (paid subscription). One can discover simply on the web, how you can create an OpenAI API key. Assuming the API secret’s created. The following step is to put in all the required packages reminiscent of LangChain, OpenAI, pypdf, and so forth.
#putting in packages
pip set up langchain
pip set up openai
pip set up streamlit
pip set up PyPDF2
pip set up pandas
Step 2: Importing Libraries
As soon as all of the packages are put in. It’s time to import them one after the other. We’ll create two Python recordsdata. One comprises all of the backend logic (named “utils.py”), and the second is for creating the entrance finish with the assistance of the streamlit bundle.
First, we’ll begin with “utils.py” the place we’ll create a number of capabilities.
#import libraries
from langchain.llms import OpenAI
from pypdf import PdfReader
import pandas as pd
import re
from langchain.llms.openai import OpenAI
from langchain.prompts import PromptTemplate
Let’s create a perform which extracts all the knowledge from a PDF file. For this, we’ll use the PdfReader bundle:
#Extract Data from PDF file
def get_pdf_text(pdf_doc):
textual content = “”
pdf_reader = PdfReader(pdf_doc)
for web page in pdf_reader.pages:
textual content += web page.extract_text()
return textual content
Then, we’ll create a perform to extract all of the required data from an bill PDF file. On this case, we’re extracting Bill No., Description, Amount, Date, Unit Value, Quantity, Complete, Electronic mail, Cellphone Quantity, and Tackle and calling OpenAI LLM API from LangChain.
def extract_data(pages_data):
template=””‘Extract all following values: bill no., Description,
Amount, date, Unit worth, Quantity, Complete,
e mail, cellphone quantity and deal with from this knowledge: {pages}
Anticipated output : take away any greenback symbols {{‘Bill no.’:’1001329′,
‘Description’:’Workplace Chair’, ‘Amount’:’2′, ‘Date’:’05/01/2022′,
‘Unit worth’:’1100.00′, Quantity’:’2200.00′, ‘Complete’:’2200.00′,
‘e mail’:'[email protected]’, ‘cellphone quantity’:’9999999999′,
‘Tackle’:’Mumbai, India’}}
”’
prompt_template = PromptTemplate(input_variables=[‘pages’], template=template)
llm = OpenAI(temperature=0.4)
full_response = llm(prompt_template.format(pages=pages_data))
return full_response
Step 5: Create a Operate that can Iterate via all of the PDF Recordsdata
Writing one final perform for the utils.py file. This perform will iterate via all of the PDF recordsdata which implies you may add a number of bill recordsdata at one go.
# iterate over recordsdata in
# that consumer uploaded PDF recordsdata, one after the other
def create_docs(user_pdf_list):
df = pd.DataFrame({‘Bill no.’: pd.Collection(dtype=”str”),
‘Description’: pd.Collection(dtype=”str”),
‘Amount’: pd.Collection(dtype=”str”),
‘Date’: pd.Collection(dtype=”str”),
‘Unit worth’: pd.Collection(dtype=”str”),
‘Quantity’: pd.Collection(dtype=”int”),
‘Complete’: pd.Collection(dtype=”str”),
‘Electronic mail’: pd.Collection(dtype=”str”),
‘Cellphone quantity’: pd.Collection(dtype=”str”),
‘Tackle’: pd.Collection(dtype=”str”)
})
for filename in user_pdf_list:
print(filename)
raw_data=get_pdf_text(filename)
#print(raw_data)
#print(“extracted uncooked knowledge”)
llm_extracted_data=extracted_data(raw_data)
#print(“llm extracted knowledge”)
#Including gadgets to our record – Including knowledge & its metadata
sample = r'{(.+)}’
match = re.search(sample, llm_extracted_data, re.DOTALL)
if match:
extracted_text = match.group(1)
# Changing the extracted textual content to a dictionary
data_dict = eval(‘{‘ + extracted_text + ‘}’)
print(data_dict)
else:
print(“No match discovered.”)
df=df.append([data_dict], ignore_index=True)
print(“********************DONE***************”)
#df=df.append(save_to_dataframe(llm_extracted_data), ignore_index=True)
df.head()
return df
Until right here our utils.py file is accomplished, Now it’s time to begin with the app.py file. The app.py file comprises front-end code with the assistance of the streamlit bundle.
Streamlit Framework
An open-source Python app framework known as Streamlit makes it simpler to construct net functions for knowledge science and machine studying. You possibly can assemble apps utilizing this method in the identical manner as you write Python code as a result of it was created for machine studying engineers. Main Python libraries together with scikit-learn, Keras, PyTorch, SymPy(latex), NumPy, pandas, and Matplotlib are suitable with Streamlit. Working pip will get you began with Streamlit in lower than a minute.
Set up and Import all Packages
First, we’ll set up and import all the required packages
#importing packages
import streamlit as st
import os
from dotenv import load_dotenv
from utils import *
Create the Foremost Operate
Then we’ll create a fundamental perform the place we’ll point out all of the titles, subheaders and front-end UI with the assistance of streamlit. Consider me, with streamlit, it is extremely easy and straightforward.
def fundamental():
load_dotenv()
st.set_page_config(page_title=”Bill Extraction Bot”)
st.title(“Bill Extraction Bot…💁 “)
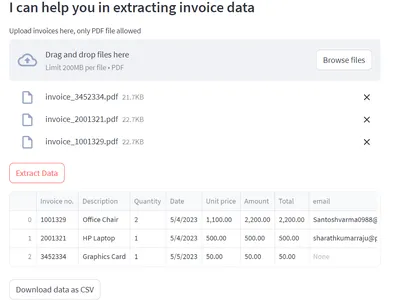
st.subheader(“I may help you in extracting bill knowledge”)
# Add the Invoices (pdf recordsdata)
pdf = st.file_uploader(“Add invoices right here, solely PDF recordsdata allowed”,
sort=[“pdf”],accept_multiple_files=True)
submit=st.button(“Extract Information”)
if submit:
with st.spinner(‘Look forward to it…’):
df=create_docs(pdf)
st.write(df.head())
data_as_csv= df.to_csv(index=False).encode(“utf-8”)
st.download_button(
“Obtain knowledge as CSV”,
data_as_csv,
“benchmark-tools.csv”,
“textual content/csv”,
key=”download-tools-csv”,
)
st.success(“Hope I used to be in a position to save your time❤️”)
#Invoking fundamental perform
if __name__ == ‘__main__’:
fundamental()
Run streamlit run app.py
As soon as that’s completed, save the recordsdata and run the “streamlit run app.py” command within the terminal. Bear in mind by default streamlit makes use of port 8501. You may also obtain the extracted data in an Excel file. The obtain choice is given within the UI.
Conclusion
Congratulations! You have got constructed an incredible and time-saving app utilizing a big language mannequin and streamlit. On this article, we’ve got discovered what a big language mannequin is and the way it’s helpful. As well as, we’ve got discovered the fundamentals of LangChain and its core parts and a few functionalities of the streamlit framework. Crucial a part of this weblog is the “extract_data” perform (from the code session), which explains how you can give correct prompts and directions to the LLM mannequin.
You have got additionally discovered the next:
Find out how to extract data from an bill PDF file.
Use of streamlit framework for UI
Use of OpenAI LLM mannequin
This provides you with some concepts on utilizing the LLM mannequin with correct prompts and directions to meet your process.
Regularly Requested Query
A. Streamlit is a library which lets you construct the entrance finish (UI) to your knowledge science and machine studying duties by writing all of the code in Python. Lovely UIs can simply be designed via quite a few parts from the library.
A. Flask is a light-weight micro-framework that’s easy to be taught and use. A newer framework known as Streamlit is made completely for net functions which are pushed by knowledge.
A. No, It relies on the use case to make use of case. On this instance, we all know what data must be extracted however if you wish to extract roughly data it is advisable to give the right directions and an instance to the LLM mannequin accordingly it would extract all of the talked about data.
A. Generative AI has the potential to have a profound affect on the creation, building, and play of video video games in addition to it will probably substitute most human-level duties with automation.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
Associated
[ad_2]
Source link


