
[ad_1]
This put up was written in collaboration with Ankur Goyal and Karthikeyan Chokappa from PwC Australia’s Cloud & Digital enterprise.
Synthetic intelligence (AI) and machine studying (ML) have gotten an integral a part of techniques and processes, enabling choices in actual time, thereby driving prime and bottom-line enhancements throughout organizations. Nonetheless, placing an ML mannequin into manufacturing at scale is difficult and requires a set of finest practices. Many companies have already got information scientists and ML engineers who can construct state-of-the-art fashions, however taking fashions to manufacturing and sustaining the fashions at scale stays a problem. Guide workflows restrict ML lifecycle operations to decelerate the event course of, improve prices, and compromise the standard of the ultimate product.
Machine studying operations (MLOps) applies DevOps ideas to ML techniques. Identical to DevOps combines improvement and operations for software program engineering, MLOps combines ML engineering and IT operations. With the speedy development in ML techniques and within the context of ML engineering, MLOps gives capabilities which might be wanted to deal with the distinctive complexities of the sensible utility of ML techniques. Total, ML use instances require a available built-in resolution to industrialize and streamline the method that takes an ML mannequin from improvement to manufacturing deployment at scale utilizing MLOps.
To handle these buyer challenges, PwC Australia developed Machine Studying Ops Accelerator as a set of standardized course of and expertise capabilities to enhance the operationalization of AI/ML fashions that allow cross-functional collaboration throughout groups all through ML lifecycle operations. PwC Machine Studying Ops Accelerator, constructed on prime of AWS native providers, delivers a fit-for-purpose resolution that simply integrates into the ML use instances with ease for purchasers throughout all industries. On this put up, we concentrate on constructing and deploying an ML use case that integrates varied lifecycle elements of an ML mannequin, enabling steady integration (CI), steady supply (CD), steady coaching (CT), and steady monitoring (CM).
Answer overview
In MLOps, a profitable journey from information to ML fashions to suggestions and predictions in enterprise techniques and processes includes a number of essential steps. It includes taking the results of an experiment or prototype and turning it right into a manufacturing system with normal controls, high quality, and suggestions loops. It’s far more than simply automation. It’s about bettering group practices and delivering outcomes which might be repeatable and reproducible at scale.
Solely a small fraction of a real-world ML use case contains the mannequin itself. The varied elements wanted to construct an built-in superior ML functionality and repeatedly function it at scale is proven in Determine 1. As illustrated within the following diagram, PwC MLOps Accelerator contains seven key built-in capabilities and iterative steps that allow CI, CD, CT, and CM of an ML use case. The answer takes benefit of AWS native options from Amazon SageMaker, constructing a versatile and extensible framework round this.
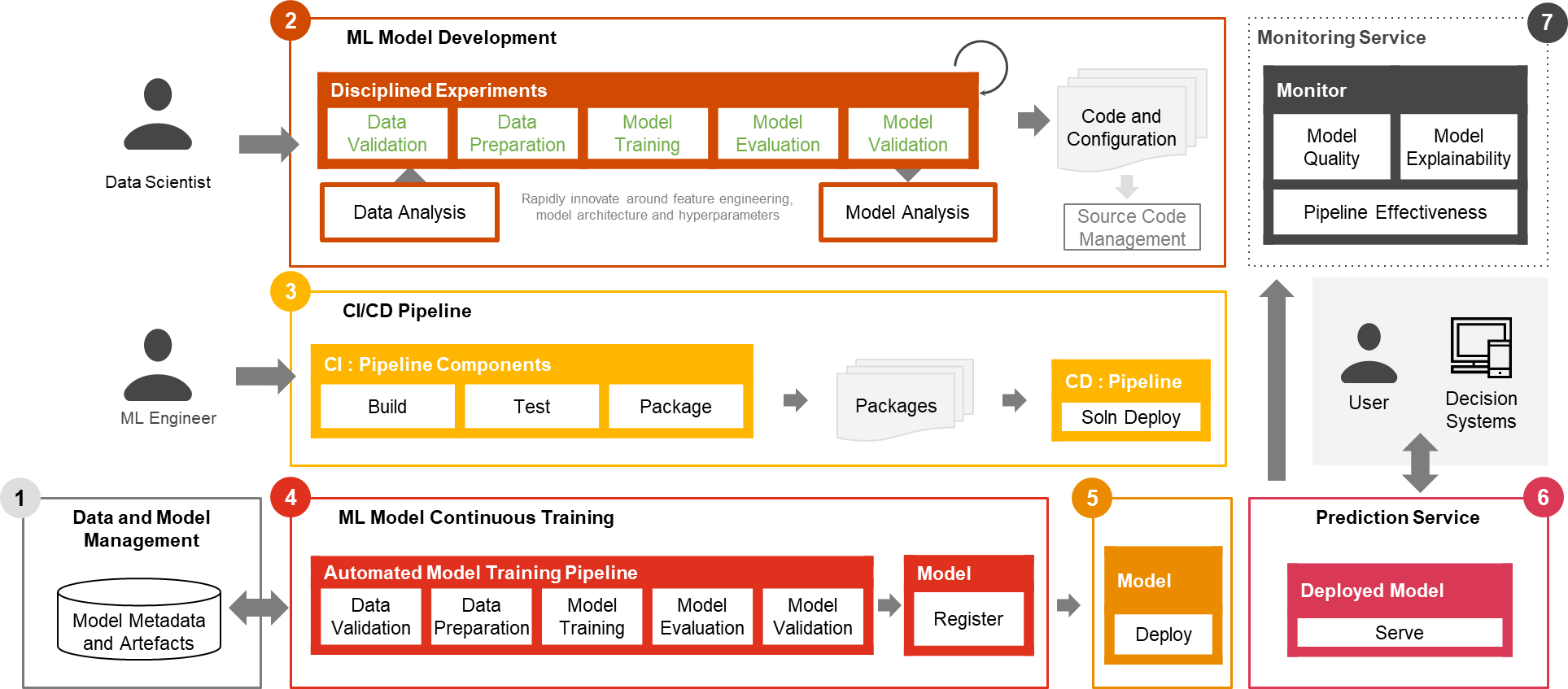
Determine 1 -– PwC Machine Studying Ops Accelerator capabilities
In an actual enterprise situation, extra steps and levels of testing might exist to make sure rigorous validation and deployment of fashions throughout totally different environments.
Information and mannequin administration present a central functionality that governs ML artifacts all through their lifecycle. It allows auditability, traceability, and compliance. It additionally promotes the shareability, reusability, and discoverability of ML belongings.
ML mannequin improvement permits varied personas to develop a strong and reproducible mannequin coaching pipeline, which contains a sequence of steps, from information validation and transformation to mannequin coaching and analysis.
Steady integration/supply facilitates the automated constructing, testing, and packaging of the mannequin coaching pipeline and deploying it into the goal execution surroundings. Integrations with CI/CD workflows and information versioning promote MLOps finest practices corresponding to governance and monitoring for iterative improvement and information versioning.
ML mannequin steady coaching functionality executes the coaching pipeline based mostly on retraining triggers; that’s, as new information turns into out there or mannequin efficiency decays beneath a preset threshold. It registers the educated mannequin if it qualifies as a profitable mannequin candidate and shops the coaching artifacts and related metadata.
Mannequin deployment permits entry to the registered educated mannequin to evaluate and approve for manufacturing launch and allows mannequin packaging, testing, and deploying into the prediction service surroundings for manufacturing serving.
Prediction service functionality begins the deployed mannequin to supply prediction by on-line, batch, or streaming patterns. Serving runtime additionally captures mannequin serving logs for steady monitoring and enhancements.
Steady monitoring displays the mannequin for predictive effectiveness to detect mannequin decay and repair effectiveness (latency, pipeline all through, and execution errors)
PwC Machine Studying Ops Accelerator structure
The answer is constructed on prime of AWS-native providers utilizing Amazon SageMaker and serverless expertise to maintain efficiency and scalability excessive and operating prices low.
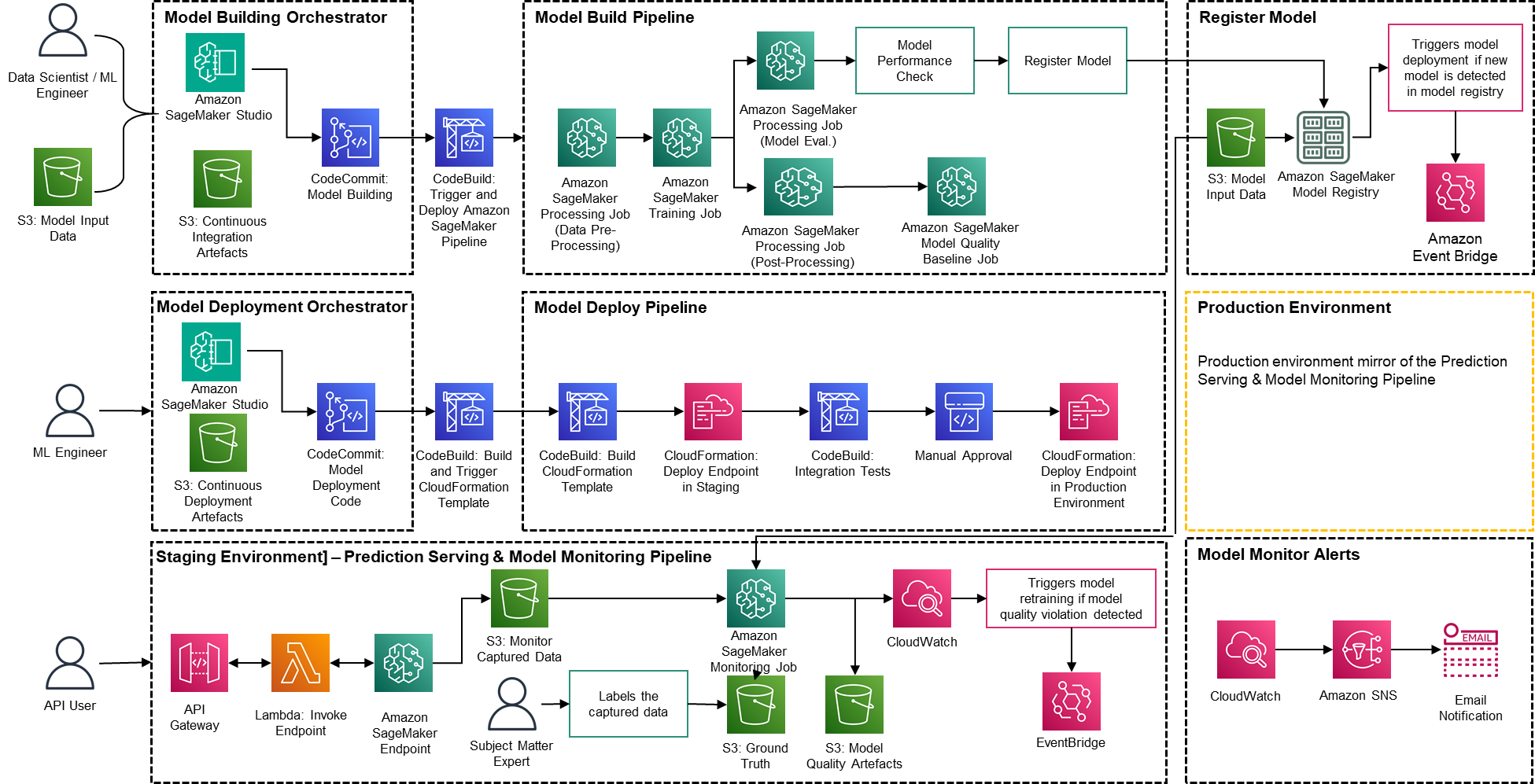
Determine 2 – PwC Machine Studying Ops Accelerator structure
PwC Machine Studying Ops Accelerator gives a persona-driven entry entitlement for build-out, utilization, and operations that permits ML engineers and information scientists to automate deployment of pipelines (coaching and serving) and quickly reply to mannequin high quality adjustments. Amazon SageMaker Position Supervisor is used to implement role-based ML exercise, and Amazon S3 is used to retailer enter information and artifacts.
Answer makes use of current mannequin creation belongings from the shopper and builds a versatile and extensible framework round this utilizing AWS native providers. Integrations have been constructed between Amazon S3, Git, and AWS CodeCommit that permit dataset versioning with minimal future administration.
AWS CloudFormation template is generated utilizing AWS Cloud Growth Package (AWS CDK). AWS CDK gives the power to handle adjustments for the entire resolution. The automated pipeline consists of steps for out-of-the-box mannequin storage and metric monitoring.
PwC MLOps Accelerator is designed to be modular and delivered as infrastructure-as-code (IaC) to permit automated deployments. The deployment course of makes use of AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, and AWS CloudFormation template. Full end-to-end resolution to operationalize an ML mannequin is obtainable as deployable code.
By means of a collection of IaC templates, three distinct elements are deployed: mannequin construct, mannequin deployment , and mannequin monitoring and prediction serving, utilizing Amazon SageMaker Pipelines
Mannequin construct pipeline automates the mannequin coaching and analysis course of and allows approval and registration of the educated mannequin.
Mannequin deployment pipeline provisions the required infrastructure to deploy the ML mannequin for batch and real-time inference.
Mannequin monitoring and prediction serving pipeline deploys the infrastructure required to serve predictions and monitor mannequin efficiency.
PwC MLOps Accelerator is designed to be agnostic to ML fashions, ML frameworks, and runtime environments. The answer permits for the acquainted use of programming languages like Python and R, improvement instruments corresponding to Jupyter Pocket book, and ML frameworks by a configuration file. This flexibility makes it easy for information scientists to repeatedly refine fashions and deploy them utilizing their most popular language and surroundings.
The answer has built-in integrations to make use of both pre-built or customized instruments to assign the labeling duties utilizing Amazon SageMaker Floor Reality for coaching datasets to supply steady coaching and monitoring.
Finish-to-end ML pipeline is architected utilizing SageMaker native options (Amazon SageMaker Studio , Amazon SageMaker Mannequin Constructing Pipelines, Amazon SageMaker Experiments, and Amazon SageMaker endpoints).
The answer makes use of Amazon SageMaker built-in capabilities for mannequin versioning, mannequin lineage monitoring, mannequin sharing, and serverless inference with Amazon SageMaker Mannequin Registry.
As soon as the mannequin is in manufacturing, the answer repeatedly displays the standard of ML fashions in actual time. Amazon SageMaker Mannequin Monitor is used to repeatedly monitor fashions in manufacturing. Amazon CloudWatch Logs is used to gather log recordsdata monitoring the mannequin standing, and notifications are despatched utilizing Amazon SNS when the standard of the mannequin hits sure thresholds. Native loggers corresponding to (boto3) are used to seize run standing to expedite troubleshooting.
Answer walkthrough
The next walkthrough dives into the usual steps to create the MLOps course of for a mannequin utilizing PwC MLOps Accelerator. This walkthrough describes a use case of an MLOps engineer who needs to deploy the pipeline for a not too long ago developed ML mannequin utilizing a easy definition/configuration file that’s intuitive.
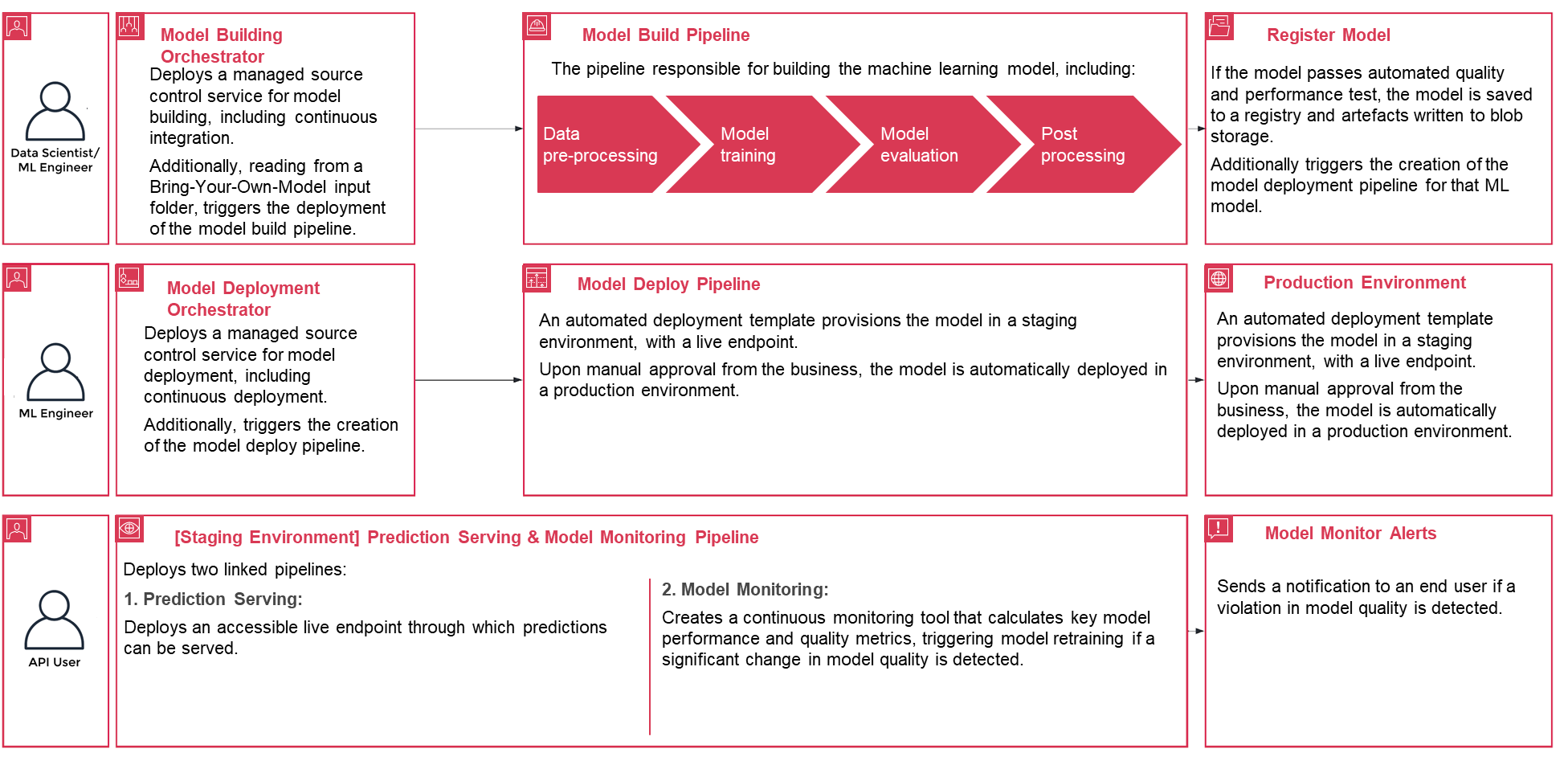
Determine 3 – PwC Machine Studying Ops Accelerator course of lifecycle
To get began, enroll in PwC MLOps Accelerator to get entry to resolution artifacts. The complete resolution is pushed from one configuration YAML file (config.yaml) per mannequin. All the small print required to run the answer are contained inside that config file and saved together with the mannequin in a Git repository. The configuration file will function enter to automate workflow steps by externalizing vital parameters and settings outdoors of code.
The ML engineer is required to populate config.yaml file and set off the MLOps pipeline. Prospects can configure an AWS account, the repository, the mannequin, the info used, the pipeline title, the coaching framework, the variety of cases to make use of for coaching, the inference framework, and any pre- and post-processing steps and a number of other different configurations to test the mannequin high quality, bias, and explainability.

Determine 4 – Machine Studying Ops Accelerator configuration YAML
A easy YAML file is used to configure every mannequin’s coaching, deployment, monitoring, and runtime necessities. As soon as the config.yaml is configured appropriately and saved alongside the mannequin in its personal Git repository, the model-building orchestrator is invoked. It can also learn from a Deliver-Your-Personal-Mannequin that may be configured by YAML to set off deployment of the mannequin construct pipeline.
The whole lot after this level is automated by the answer and doesn’t want the involvement of both the ML engineer or information scientist. The pipeline chargeable for constructing the ML mannequin consists of information preprocessing, mannequin coaching, mannequin analysis, and ost-processing. If the mannequin passes automated high quality and efficiency assessments, the mannequin is saved to a registry, and artifacts are written to Amazon S3 storage per the definitions within the YAML recordsdata. This triggers the creation of the mannequin deployment pipeline for that ML mannequin.
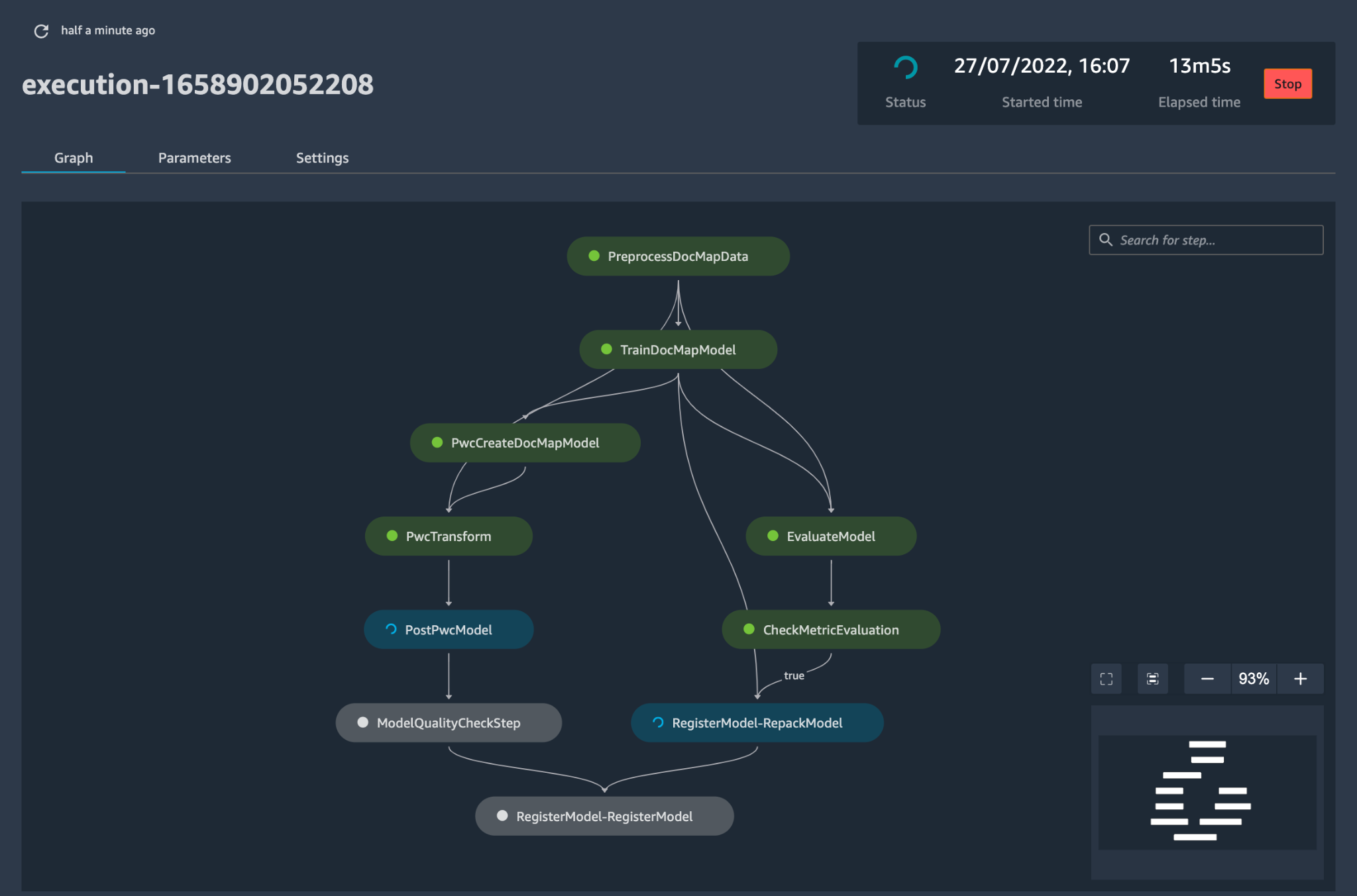
Determine 5 – Pattern mannequin deployment workflow
Subsequent, an automatic deployment template provisions the mannequin in a staging surroundings with a dwell endpoint. Upon approval, the mannequin is robotically deployed into the manufacturing surroundings.
The answer deploys two linked pipelines. Prediction serving deploys an accessible dwell endpoint by which predictions might be served. Mannequin monitoring creates a steady monitoring instrument that calculates key mannequin efficiency and high quality metrics, triggering mannequin retraining if a big change in mannequin high quality is detected.
Now that you simply’ve gone by the creation and preliminary deployment, the MLOps engineer can configure failure alerts to be alerted for points, for instance, when a pipeline fails to do its supposed job.
MLOps is not about packaging, testing, and deploying cloud service elements just like a conventional CI/CD deployment; it’s a system that ought to robotically deploy one other service. For instance, the mannequin coaching pipeline robotically deploys the mannequin deployment pipeline to allow prediction service, which in flip allows the mannequin monitoring service.
Conclusion
In abstract, MLOps is essential for any group that goals to deploy ML fashions in manufacturing techniques at scale. PwC developed an accelerator to automate constructing, deploying, and sustaining ML fashions by way of integrating DevOps instruments into the mannequin improvement course of.
On this put up, we explored how the PwC resolution is powered by AWS native ML providers and helps to undertake MLOps practices so that companies can velocity up their AI journey and achieve extra worth from their ML fashions. We walked by the steps a consumer would take to entry the PwC Machine Studying Ops Accelerator, run the pipelines, and deploy an ML use case that integrates varied lifecycle elements of an ML mannequin.
To get began along with your MLOps journey on AWS Cloud at scale and run your ML manufacturing workloads, enroll in PwC Machine Studying Operations.
In regards to the Authors
 Kiran Kumar Ballari is a Principal Options Architect at Amazon Internet Providers (AWS). He’s an evangelist who loves to assist clients leverage new applied sciences and construct repeatable business options to resolve their issues. He’s particularly captivated with software program engineering , Generative AI and serving to corporations with AI/ML product improvement.
Kiran Kumar Ballari is a Principal Options Architect at Amazon Internet Providers (AWS). He’s an evangelist who loves to assist clients leverage new applied sciences and construct repeatable business options to resolve their issues. He’s particularly captivated with software program engineering , Generative AI and serving to corporations with AI/ML product improvement.
 Ankur Goyal is a director in PwC Australia’s Cloud and Digital follow, centered on Information, Analytics & AI. Ankur has in depth expertise in supporting private and non-private sector organizations in driving expertise transformations and designing progressive options by leveraging information belongings and applied sciences.
Ankur Goyal is a director in PwC Australia’s Cloud and Digital follow, centered on Information, Analytics & AI. Ankur has in depth expertise in supporting private and non-private sector organizations in driving expertise transformations and designing progressive options by leveraging information belongings and applied sciences.
 Karthikeyan Chokappa (KC) is a Supervisor in PwC Australia’s Cloud and Digital follow, centered on Information, Analytics & AI. KC is captivated with designing, growing, and deploying end-to-end analytics options that rework information into worthwhile resolution belongings to enhance efficiency and utilization and cut back the whole value of possession for related and clever issues.
Karthikeyan Chokappa (KC) is a Supervisor in PwC Australia’s Cloud and Digital follow, centered on Information, Analytics & AI. KC is captivated with designing, growing, and deploying end-to-end analytics options that rework information into worthwhile resolution belongings to enhance efficiency and utilization and cut back the whole value of possession for related and clever issues.
 Rama Lankalapalli is a Sr. Accomplice Options Architect at AWS, working with PwC to speed up their shoppers’ migrations and modernizations into AWS. He works throughout various industries to speed up their adoption of AWS Cloud. His experience lies in architecting environment friendly and scalable cloud options, driving innovation and modernization of buyer purposes by leveraging AWS providers, and establishing resilient cloud foundations.
Rama Lankalapalli is a Sr. Accomplice Options Architect at AWS, working with PwC to speed up their shoppers’ migrations and modernizations into AWS. He works throughout various industries to speed up their adoption of AWS Cloud. His experience lies in architecting environment friendly and scalable cloud options, driving innovation and modernization of buyer purposes by leveraging AWS providers, and establishing resilient cloud foundations.
 Jeejee Unwalla is a Senior Options Architect at AWS who enjoys guiding clients in fixing challenges and considering strategically. He’s captivated with tech and information and enabling innovation.
Jeejee Unwalla is a Senior Options Architect at AWS who enjoys guiding clients in fixing challenges and considering strategically. He’s captivated with tech and information and enabling innovation.
[ad_2]
Source link


