
[ad_1]
Giant Language Fashions (LLMs) have emerged as a cornerstone in synthetic intelligence, proficiently managing numerous duties from pure language processing to complicated decision-making processes. Nevertheless, as these fashions develop in sophistication, in addition they encounter vital challenges, notably regarding knowledge memorization. This phenomenon raises substantial questions concerning the fashions’ means to generalize throughout several types of knowledge, particularly tabular knowledge, which stays a important space of concern inside the subject.
Memorization in LLMs is a double-edged sword. Whereas it allows fashions like GPT-3.5 and GPT-4 to excel in duties involving acquainted datasets, it additionally predisposes them to overfit, the place efficiency on new, unseen datasets might not meet expectations. The core situation is how these fashions retain and recall particular datasets they had been uncovered to throughout coaching, affecting their predictive accuracy and reliability when confronted with new knowledge.
In present observe, a number of strategies are employed to find out whether or not an LLM has beforehand encountered a selected dataset. These embody strategies that assess the power of a mannequin to breed dataset-specific particulars verbatim. Such strategies are very important for discerning whether or not an LLM’s spectacular efficiency stems from real studying or merely recalling coaching knowledge. The analysis introduces quite a lot of new methodologies to boost the detection of memorization, together with utilizing what the researchers name ‘publicity checks’ to measure how LLMs course of and doubtlessly memorize coaching knowledge exactly.
Researchers from the College of Tubingen, Tubingen AI Middle, and Microsoft Analysis launched the Header Check, Row Completion Check, Characteristic Completion Check, and First Token Check. These checks are designed to probe totally different elements of memorization and supply insights into how the mannequin internalizes knowledge throughout coaching. As an example, the Header Check examines if the mannequin can reproduce the preliminary rows of a dataset verbatim, indicating that it has memorized these particular entries.
The examine’s findings reveal a nuanced image of memorization and its impacts on mannequin efficiency. When analyzing the few-shot studying capabilities of LLMs, the analysis reveals that fashions like GPT-3.5 and GPT-4 carry out considerably higher on datasets they’ve seen throughout coaching than fully new ones. For instance, GPT-3.5 demonstrated a predictive accuracy fee of 0.96 on memorized datasets in its authentic format, a determine that notably drops to 0.62 beneath perturbed situations. This stark distinction underscores the potential limitations of relying too closely on memorization.
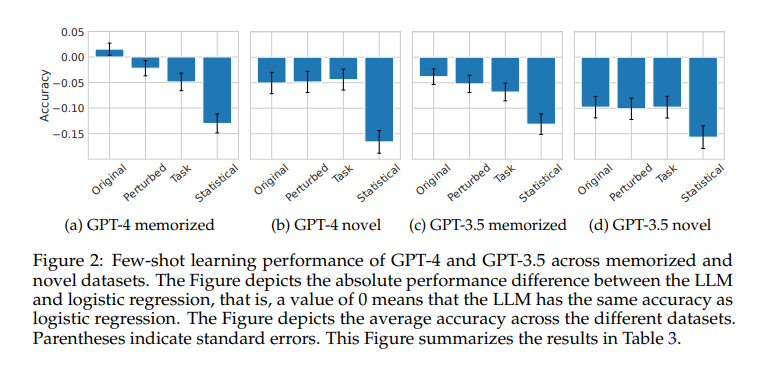
The examine highlights that memorization can result in excessive efficiency on acquainted duties, however it doesn’t essentially equip LLMs to sort out new challenges successfully. In situations involving novel datasets, the efficiency of those fashions usually stays sturdy. But, they exhibit no vital benefit over conventional statistical strategies like logistic regression or gradient-boosted timber, suggesting that their success in unfamiliar territories hinges extra on generalized studying than memorization.

In conclusion, the analysis paper presents a compelling evaluation of the implications of memorization in LLMs, notably specializing in tabular knowledge. It underscores the significance of growing strategies to detect and mitigate the consequences of knowledge memorization to forestall overfitting and be certain that LLMs can carry out reliably throughout numerous domains. As LLMs evolve, balancing the skinny line between memorization and generalization turns into paramount in harnessing their full potential whereas guaranteeing their applicability in real-world situations. The findings from this examine contribute to understanding LLMs’ operational dynamics and information future developments in AI analysis, aiming for fashions which are as adept at dealing with novel conditions as acquainted ones.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 40k+ ML SubReddit
Need to get in entrance of 1.5 Million AI Viewers? Work with us right here
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]
Source link


