
[ad_1]
Reinforcement Studying from Human Suggestions (RLHF) enhances the alignment of Pretrained Massive Language Fashions (LLMs) with human values, enhancing their applicability and reliability. Nonetheless, aligning LLMs by way of RLHF faces important hurdles, primarily as a result of course of’s computational depth and useful resource calls for. Coaching LLMs with RLHF is a fancy, resource-intensive process that limits its widespread adoption.
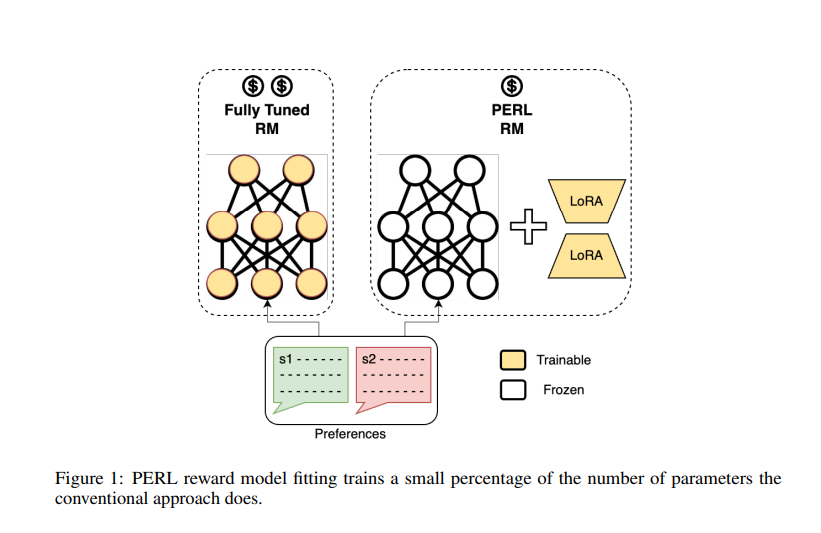
Completely different strategies like RLHF, RLAIF, and LoRA have been developed to beat the prevailing limitations. RLHF works by becoming a reward mannequin on most popular outputs and coaching a coverage utilizing reinforcement studying algorithms like PPO. Labeling examples for coaching reward fashions could be pricey, so some works have changed human suggestions with AI suggestions. Parameter Environment friendly Fantastic-Tuning (PEFT) strategies scale back the variety of trainable parameters in PLMs whereas sustaining efficiency. LoRA, an instance of a PEFT methodology, factorizes weight updates into trainable low-rank matrices, permitting coaching of solely a small fraction of the full parameters.
Google’s workforce of researchers introduces a revolutionary methodology, Parameter-Environment friendly Reinforcement Studying (PERL). This revolutionary method harnesses LoRA to refine fashions extra effectively, sustaining the efficiency of conventional RLHF strategies whereas considerably decreasing computational and reminiscence necessities. PERL permits selective coaching of those adapters whereas preserving the core mannequin, drastically decreasing the reminiscence footprint and computational load required for coaching with out compromising the mannequin’s efficiency.
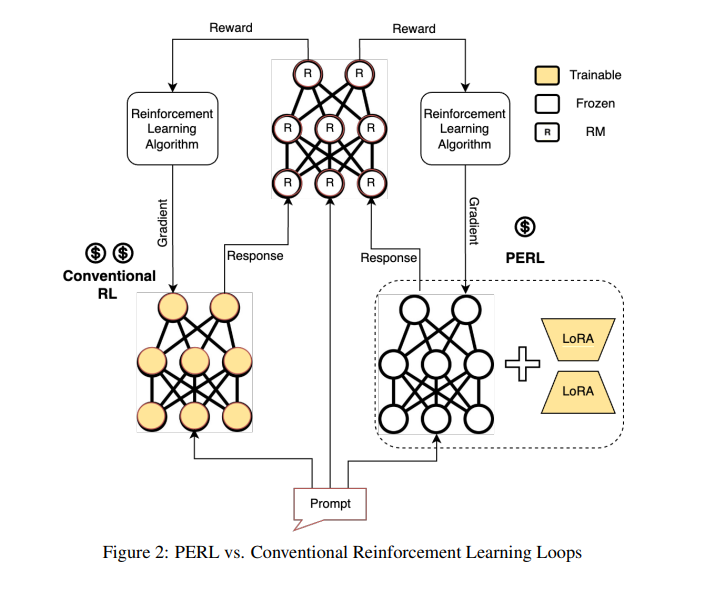
PERL revolutionizes the coaching of RLHF fashions by implementing LoRA for enhanced parameter effectivity throughout a variety of datasets. It leverages numerous knowledge, together with textual content summarization from Reddit TL;DR and BOLT English SMS/Chat, innocent response desire modeling, helpfulness metrics from the Stanford Human Preferences Dataset, and UI Automation duties derived from human demonstrations. PERL makes use of crowdsourced Taskmaster datasets, specializing in conversational interactions in espresso ordering and ticketing eventualities, to refine mannequin responses.
The analysis reveals PERL’s effectivity in aligning with typical RLHF outcomes, considerably decreasing reminiscence utilization by about 50% and accelerating Reward Mannequin coaching by as much as 90%. LoRA-enhanced fashions match the accuracy of totally educated counterparts with half the height HBM utilization and 40% sooner coaching. Qualitatively, PERL maintains RLHF’s excessive efficiency with lowered computational calls for, providing a promising avenue for using ensemble fashions like Combination-of-LoRA for strong, cross-domain generalization and using weight-averaged adapters to decrease reward hacking dangers at lowered computational prices.
In conclusion, Google’s PERL methodology marks a major leap ahead in aligning AI with human values and preferences. By mitigating the computational challenges related to RLHF, PERL enhances the effectivity and applicability of LLMs and units a brand new benchmark for future analysis in AI alignment. The innovation of PERL is a vivid illustration of how parameter-efficient strategies can revolutionize the panorama of synthetic intelligence, making it extra accessible, environment friendly, and aligned with human values.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 38k+ ML SubReddit
![]()
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link


