
[ad_1]
The continuously altering nature of the world round us poses a big problem for the event of AI fashions. Typically, fashions are skilled on longitudinal information with the hope that the coaching information used will precisely signify inputs the mannequin might obtain sooner or later. Extra usually, the default assumption that every one coaching information are equally related usually breaks in observe. For instance, the determine under reveals photographs from the CLEAR nonstationary studying benchmark, and it illustrates how visible options of objects evolve considerably over a ten 12 months span (a phenomenon we discuss with as sluggish idea drift), posing a problem for object categorization fashions.
 Pattern photographs from the CLEAR benchmark. (Tailored from Lin et al.)
Pattern photographs from the CLEAR benchmark. (Tailored from Lin et al.)
Various approaches, corresponding to on-line and continuous studying, repeatedly replace a mannequin with small quantities of current information with a purpose to hold it present. This implicitly prioritizes current information, because the learnings from previous information are regularly erased by subsequent updates. Nevertheless in the true world, completely different sorts of data lose relevance at completely different charges, so there are two key points: 1) By design they focus completely on the newest information and lose any sign from older information that’s erased. 2) Contributions from information situations decay uniformly over time regardless of the contents of the info.
In our current work, “Occasion-Conditional Timescales of Decay for Non-Stationary Studying”, we suggest to assign every occasion an significance rating throughout coaching with a purpose to maximize mannequin efficiency on future information. To perform this, we make use of an auxiliary mannequin that produces these scores utilizing the coaching occasion in addition to its age. This mannequin is collectively discovered with the first mannequin. We deal with each the above challenges and obtain vital positive factors over different sturdy studying strategies on a variety of benchmark datasets for nonstationary studying. As an illustration, on a current large-scale benchmark for nonstationary studying (~39M images over a ten 12 months interval), we present as much as 15% relative accuracy positive factors by means of discovered reweighting of coaching information.
The problem of idea drift for supervised studying
To achieve quantitative perception into sluggish idea drift, we constructed classifiers on a current photograph categorization job, comprising roughly 39M pictures sourced from social media web sites over a ten 12 months interval. We in contrast offline coaching, which iterated over all of the coaching information a number of instances in random order, and continuous coaching, which iterated a number of instances over every month of knowledge in sequential (temporal) order. We measured mannequin accuracy each through the coaching interval and through a subsequent interval the place each fashions have been frozen, i.e., not up to date additional on new information (proven under). On the finish of the coaching interval (left panel, x-axis = 0), each approaches have seen the identical quantity of knowledge, however present a big efficiency hole. This is because of catastrophic forgetting, an issue in continuous studying the place a mannequin’s data of knowledge from early on within the coaching sequence is diminished in an uncontrolled method. However, forgetting has its benefits — over the take a look at interval (proven on the suitable), the continuous skilled mannequin degrades a lot much less quickly than the offline mannequin as a result of it’s much less depending on older information. The decay of each fashions’ accuracy within the take a look at interval is affirmation that the info is certainly evolving over time, and each fashions develop into more and more much less related.
 Evaluating offline and frequently skilled fashions on the photograph classification job.
Evaluating offline and frequently skilled fashions on the photograph classification job.
Time-sensitive reweighting of coaching information
We design a technique combining the advantages of offline studying (the pliability of successfully reusing all obtainable information) and continuous studying (the flexibility to downplay older information) to deal with sluggish idea drift. We construct upon offline studying, then add cautious management over the affect of previous information and an optimization goal, each designed to cut back mannequin decay sooner or later.
Suppose we want to practice a mannequin, M, given some coaching information collected over time. We suggest to additionally practice a helper mannequin that assigns a weight to every level primarily based on its contents and age. This weight scales the contribution from that information level within the coaching goal for M. The target of the weights is to enhance the efficiency of M on future information.
In our work, we describe how the helper mannequin could be meta-learned, i.e., discovered alongside M in a fashion that helps the educational of the mannequin M itself. A key design selection of the helper mannequin is that we separated out instance- and age-related contributions in a factored method. Particularly, we set the burden by combining contributions from a number of completely different mounted timescales of decay, and study an approximate “task” of a given occasion to its most suited timescales. We discover in our experiments that this type of the helper mannequin outperforms many different options we thought-about, starting from unconstrained joint capabilities to a single timescale of decay (exponential or linear), as a consequence of its mixture of simplicity and expressivity. Full particulars could also be discovered within the paper.
Occasion weight scoring
The highest determine under reveals that our discovered helper mannequin certainly up-weights extra modern-looking objects within the CLEAR object recognition problem; older-looking objects are correspondingly down-weighted. On nearer examination (backside determine under, gradient-based function significance evaluation), we see that the helper mannequin focuses on the first object throughout the picture, versus, e.g., background options which will spuriously be correlated with occasion age.
 Pattern photographs from the CLEAR benchmark (digicam & laptop classes) assigned the best and lowest weights respectively by our helper mannequin.
Pattern photographs from the CLEAR benchmark (digicam & laptop classes) assigned the best and lowest weights respectively by our helper mannequin.
 Characteristic significance evaluation of our helper mannequin on pattern photographs from the CLEAR benchmark.
Characteristic significance evaluation of our helper mannequin on pattern photographs from the CLEAR benchmark.
Outcomes
Good points on large-scale information
We first research the large-scale photograph categorization job (PCAT) on the YFCC100M dataset mentioned earlier, utilizing the primary 5 years of knowledge for coaching and the subsequent 5 years as take a look at information. Our technique (proven in purple under) improves considerably over the no-reweighting baseline (black) in addition to many different sturdy studying methods. Apparently, our technique intentionally trades off accuracy on the distant previous (coaching information unlikely to reoccur sooner or later) in change for marked enhancements within the take a look at interval. Additionally, as desired, our technique degrades lower than different baselines within the take a look at interval.
 Comparability of our technique and related baselines on the PCAT dataset.
Comparability of our technique and related baselines on the PCAT dataset.
Broad applicability
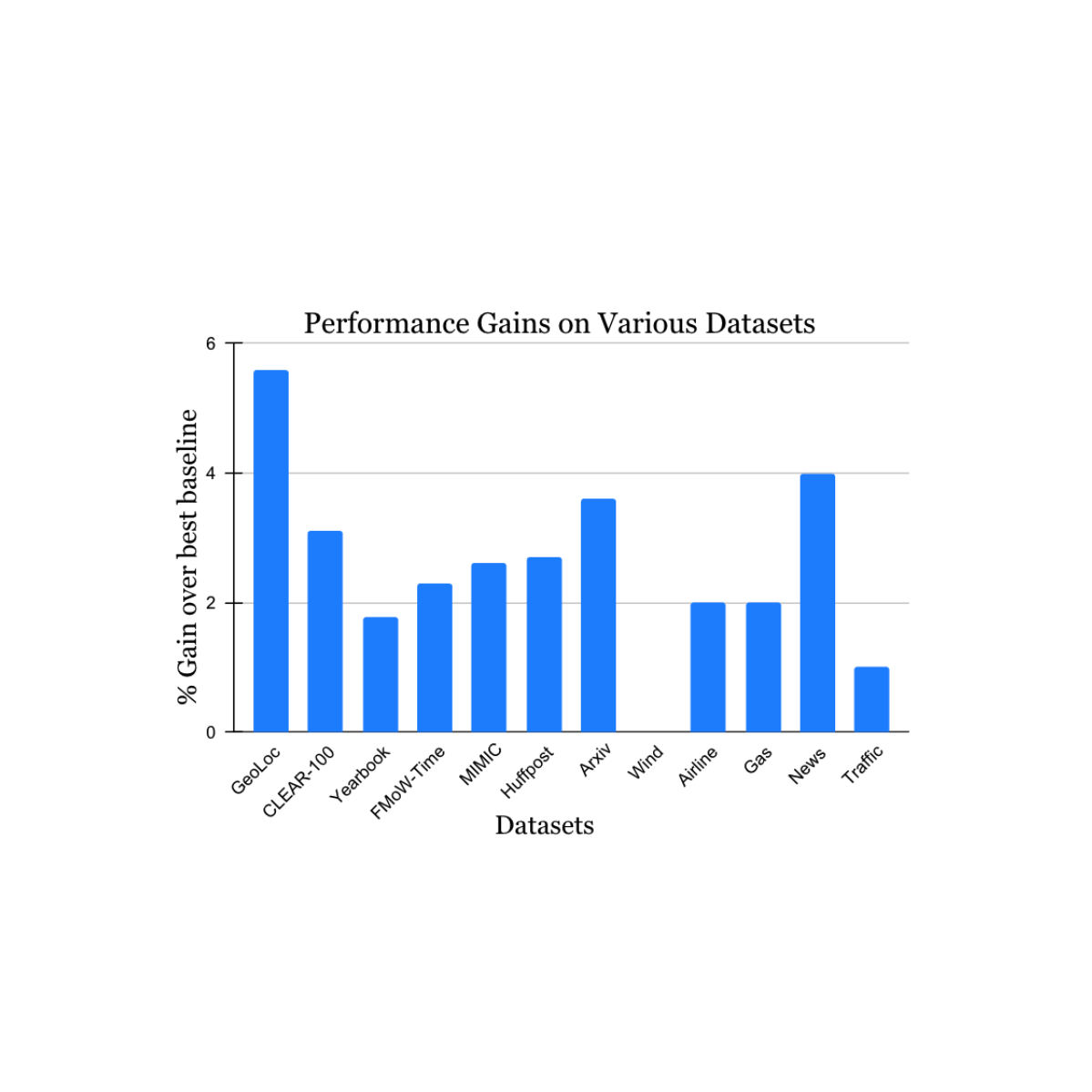
We validated our findings on a variety of nonstationary studying problem datasets sourced from the tutorial literature (see 1, 2, 3, 4 for particulars) that spans information sources and modalities (images, satellite tv for pc photographs, social media textual content, medical information, sensor readings, tabular information) and sizes (starting from 10k to 39M situations). We report vital positive factors within the take a look at interval when in comparison with the closest printed benchmark technique for every dataset (proven under). Notice that the earlier best-known technique could also be completely different for every dataset. These outcomes showcase the broad applicability of our method.
 Efficiency acquire of our technique on a wide range of duties finding out pure idea drift. Our reported positive factors are over the earlier best-known technique for every dataset.
Efficiency acquire of our technique on a wide range of duties finding out pure idea drift. Our reported positive factors are over the earlier best-known technique for every dataset.
Extensions to continuous studying
Lastly, we think about an attention-grabbing extension of our work. The work above described how offline studying could be prolonged to deal with idea drift utilizing concepts impressed by continuous studying. Nevertheless, typically offline studying is infeasible — for instance, if the quantity of coaching information obtainable is just too giant to take care of or course of. We tailored our method to continuous studying in a simple method by making use of temporal reweighting throughout the context of every bucket of knowledge getting used to sequentially replace the mannequin. This proposal nonetheless retains some limitations of continuous studying, e.g., mannequin updates are carried out solely on most-recent information, and all optimization selections (together with our reweighting) are solely remodeled that information. Nonetheless, our method persistently beats common continuous studying in addition to a variety of different continuous studying algorithms on the photograph categorization benchmark (see under). Since our method is complementary to the concepts in lots of baselines in contrast right here, we anticipate even bigger positive factors when mixed with them.
 Outcomes of our technique tailored to continuous studying, in comparison with the newest baselines.
Outcomes of our technique tailored to continuous studying, in comparison with the newest baselines.
Conclusion
We addressed the problem of knowledge drift in studying by combining the strengths of earlier approaches — offline studying with its efficient reuse of knowledge, and continuous studying with its emphasis on newer information. We hope that our work helps enhance mannequin robustness to idea drift in observe, and generates elevated curiosity and new concepts in addressing the ever-present drawback of sluggish idea drift.
Acknowledgements
We thank Mike Mozer for a lot of attention-grabbing discussions within the early section of this work, in addition to very useful recommendation and suggestions throughout its growth.
[ad_2]
Source link


