
[ad_1]
Open-source Giant Language Fashions (LLMs) comparable to LLaMA, Falcon, and Mistral supply a variety of selections for AI professionals and students. But, the vast majority of these LLMs have solely made out there choose parts just like the end-model weights or inference scripts, with technical paperwork typically narrowing their focus to broader design points and primary metrics. This method restricts advances within the subject by lowering readability within the coaching methodologies of LLMs, resulting in repeated efforts by groups to uncover quite a few points of the coaching process.
A crew of researchers from Petuum, MBZUAI, USC, CMU, UIUC, and UCSD launched LLM360 to assist open and collaborative AI analysis by making the end-to-end LLM coaching course of clear and reproducible by everybody. LLM360 is an initiative to totally open-source LLMs that advocates for all coaching code and knowledge, mannequin checkpoints, and intermediate outcomes to be made out there to the neighborhood.
The closest undertaking to LLM360 is Pythia, which additionally goals to attain the complete reproducibility of LLMs. EleutherAI fashions comparable to GPT-J and GPT-NeoX have been launched with coaching code, datasets, and intermediate mannequin checkpoints, demonstrating the worth of open-source coaching code. INCITE, MPT, and OpenLLaMA had been launched with coaching code and coaching datasets, with RedPajama additionally releasing intermediate mannequin checkpoints.
LLM360 releases two 7B parameter LLMs, AMBER and CRYSTALCODER, together with their coaching code, knowledge, intermediate checkpoints, and analyses. The small print of the pre-training dataset, together with knowledge preprocessing, format, knowledge mixing ratios, and architectural particulars of the LLM mannequin, are reviewed within the examine.
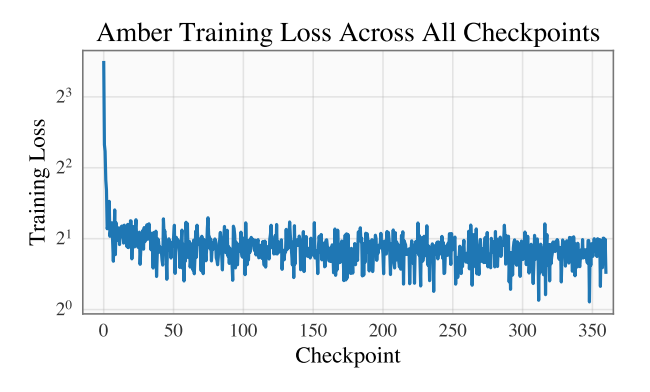
The analysis mentions utilizing the memorization rating launched in earlier work and releasing metrics, knowledge chunks, and checkpoints for researchers to seek out their correspondence simply. The examine additionally emphasizes the significance of eradicating the information LLMs are pre educated on, together with particulars about knowledge filtering, processing, and coaching order, to evaluate the dangers of LLMs.
The analysis presents benchmark outcomes on 4 datasets, particularly ARC, HellaSwag, MMLU, and TruthfulQA, exhibiting the mannequin’s efficiency throughout pre-training. The analysis scores of HellaSwag and ARC monotonically enhance throughout pre-training, whereas the TruthfulQA rating decreases. The MMLU rating initially decreases after which begins to develop. AMBER’s efficiency is comparatively aggressive in scores comparable to MMLU, nevertheless it lags past in ARC. Finetuned AMBER fashions present sturdy efficiency in comparison with different related fashions.
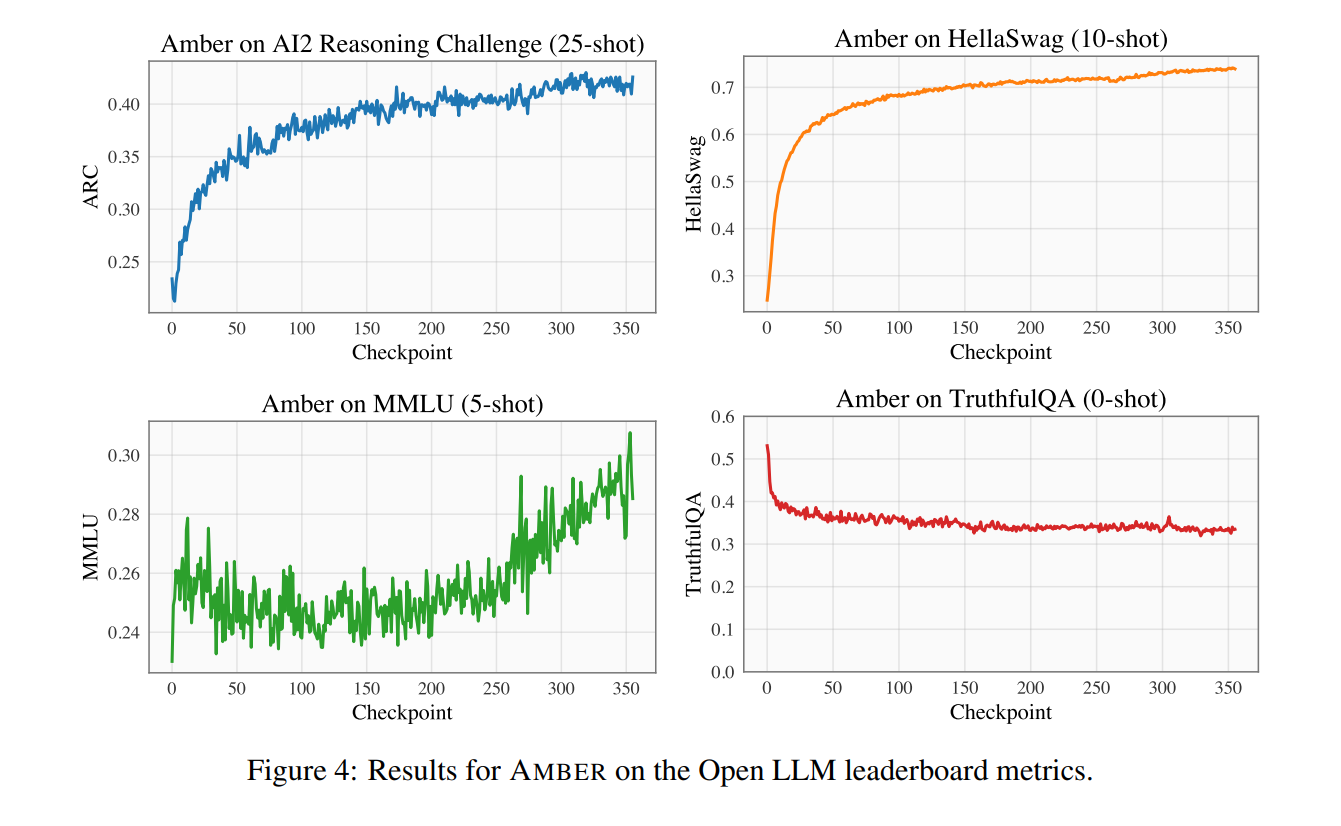
In conclusion, LLM360 is an initiative for complete and totally open-sourced LLMs to advance transparency throughout the open-source LLM pre-training neighborhood. The examine launched two 7B LLMs, AMBER and CRYSTALCODER, together with their coaching code, knowledge, intermediate mannequin checkpoints, and analyses. The examine emphasizes the significance of open sourcing. LLMs from all angles, together with releasing checkpoints, knowledge chunks, and analysis outcomes, to allow complete evaluation and reproducibility.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and E-mail E-newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
For those who like our work, you’ll love our publication..
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]
Source link


