
[ad_1]
Just lately, text-to-image (T2I) diffusion fashions have exhibited promising outcomes, sparking explorations into quite a few generative duties. Some efforts have been made to invert pre-trained text-to-image fashions to acquire textual content embedding representations, permitting for capturing object appearances in reference photographs. Nevertheless, there was restricted exploration of capturing object relations, a tougher job involving the understanding of interactions between objects and picture composition. Present inversion strategies wrestle with this job because of entity leakage from reference photographs, which occurs when a mannequin leaks delicate details about entities or people, resulting in privateness violations.
Nonetheless, addressing this problem is of great significance.
This research focuses on the Relation Inversion job, which goals to study relationships in given exemplar photographs. The target is to derive a relation immediate inside the textual content embedding house of a pre-trained text-to-image diffusion mannequin, the place objects in every exemplar picture comply with a particular relation. Combining the relation immediate with user-defined textual content prompts permits customers to generate photographs equivalent to particular relationships whereas customizing objects, types, backgrounds, and extra.
A preposition prior is launched to boost the illustration of high-level relation ideas utilizing the learnable immediate. This prior is predicated on the remark that prepositions are intently linked to relations, prepositions and phrases of different components of speech are individually clustered within the textual content embedding house, and complicated real-world relations could be expressed utilizing a primary set of prepositions.
Constructing upon the preposition prior, a novel framework termed ReVersion is proposed to deal with the Relation Inversion drawback. An outline of the framework is illustrated under.
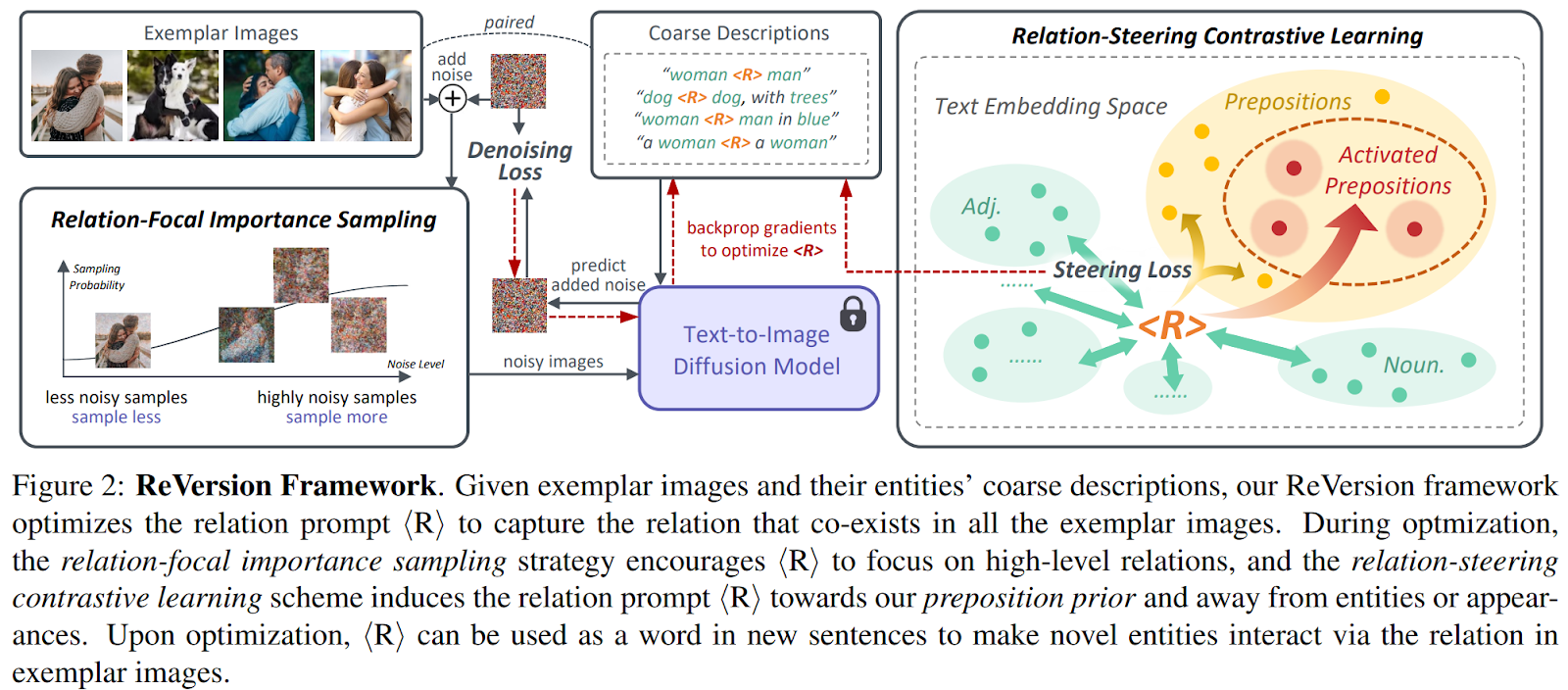
This framework incorporates a novel relation-steering contrastive studying scheme to information the relation immediate towards a relation-dense area within the textual content embedding house. Foundation prepositions are used as optimistic samples to encourage embedding into the sparsely activated space. On the similar time, phrases of different components of speech in textual content descriptions are thought of negatives, disentangling semantics associated to object appearances. A relation-focal significance sampling technique is devised to emphasise object interactions over low-level particulars, constraining the optimization course of for improved relation inversion outcomes.
As well as, the researchers introduce the ReVersion Benchmark, which gives a wide range of exemplar photographs that includes numerous relations. This benchmark serves as an analysis software for future analysis within the Relation Inversion job. Outcomes throughout varied relations exhibit the effectiveness of the preposition prior and the ReVersion framework.
As introduced within the research, we report among the supplied outcomes under. Since this entails a novel job, there isn’t any different state-of-the-art method to check with.

This was the abstract of ReVersion, a novel AI diffusion mannequin framework designed to deal with the Relation Inversion job. If you’re and need to study extra about it, please be happy to check with the hyperlinks cited under.
Take a look at the Paper and Undertaking. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t neglect to hitch our 30k+ ML SubReddit, 40k+ Fb Group, Discord Channel, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI tasks, and extra.
When you like our work, you’ll love our e-newsletter..
![]()
Daniele Lorenzi acquired his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Info Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s presently working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embrace adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
[ad_2]
Source link


