
[ad_1]
Massive multimodal fashions (LMMs) have the potential to revolutionize how machines work together with human languages and visible data, providing extra intuitive and pure methods for machines to know our world. The problem in multimodal studying entails precisely decoding and synthesizing data from textual and visible inputs. This course of is advanced because of the want to know the distinct properties of every modality and successfully combine these insights right into a cohesive understanding.
Present analysis focuses on autoregressive LLMs to vision-language studying and the best way to successfully exploit LLMs by viewing visible indicators as conditional data. Exploration additionally consists of fine-tuning LMMs with visible instruction tuning knowledge to boost their zero-shot capabilities. Small-scale LMMs have been developed to cut back computation overhead, with present fashions like Phi-2, TinyLlama, and StableLM-2 attaining spectacular performances whereas sustaining affordable compute budgets.

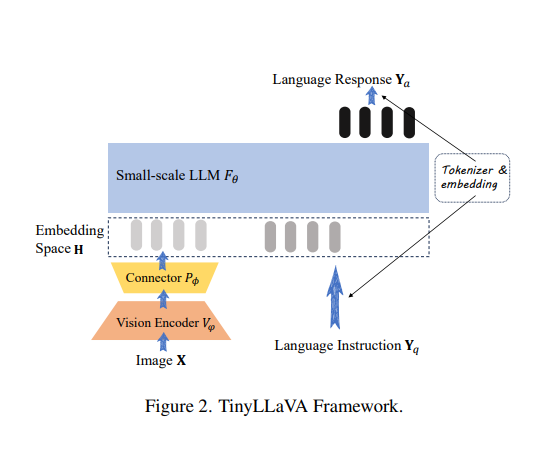
Researchers from Beihang College and Tsinghua College in China have launched TinyLLaVA, a novel framework that makes use of small-scale LLMs for multimodal duties. This framework contains a imaginative and prescient encoder, a small-scale LLM decoder, an intermediate connector, and tailor-made coaching pipelines. TinyLLaVA goals to attain excessive efficiency in multimodal studying whereas minimizing computational calls for.
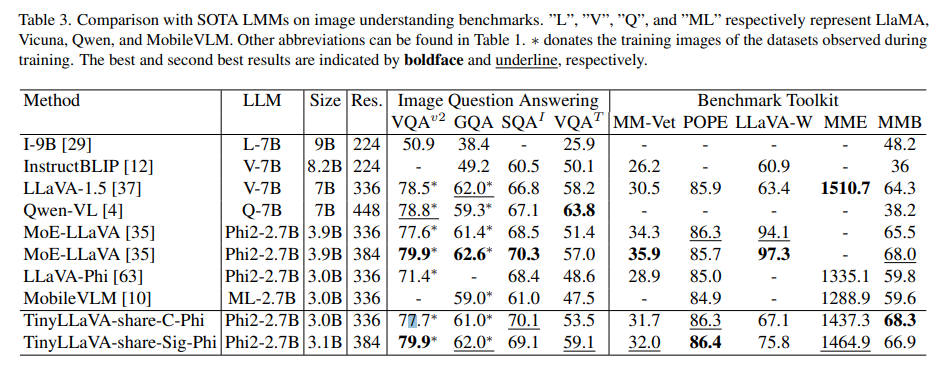
The framework trains a household of small-scale LMMs, with the very best mannequin, TinyLLaVA-3.1B, outperforming present 7B fashions reminiscent of LLaVA-1.5 and Qwen-VL. It combines imaginative and prescient encoders like CLIP-Massive and SigLIP with small-scale LMMs for higher efficiency. The coaching knowledge consists of two totally different datasets, LLaVA-1.5 and ShareGPT4V, used to review the affect of information high quality on LMM efficiency. It permits the adjustment of partially learnable parameters of the LLM and imaginative and prescient encoder through the supervised fine-tuning stage. It additionally offers a unified evaluation of mannequin choices, coaching recipes, and knowledge contributions to the efficiency of small-scale LMMs.
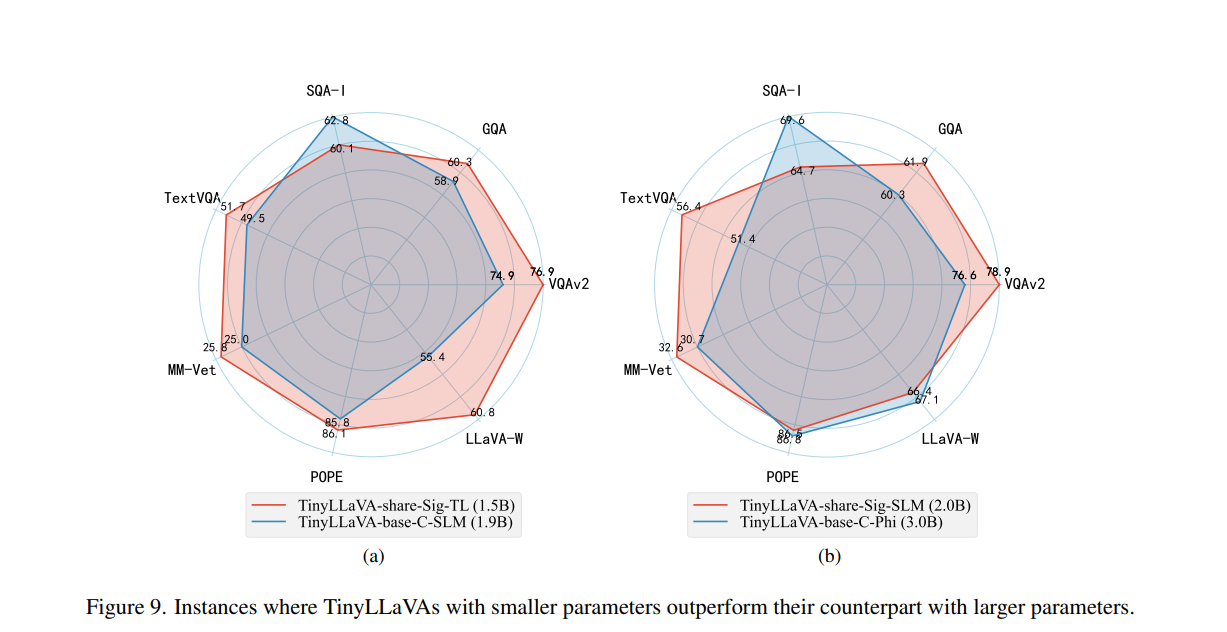
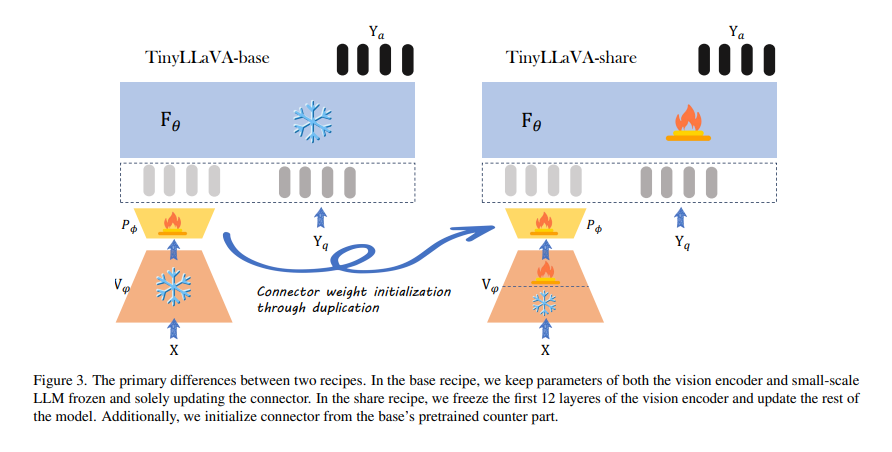
The experiments revealed important findings: mannequin variants using bigger LLMs and the SigLIP imaginative and prescient encoder demonstrated superior efficiency. The shared recipe, which incorporates imaginative and prescient encoder fine-tuning, enhanced the effectiveness of all mannequin variants. Among the many standout outcomes, the TinyLLaVA-share-Sig-Phi variant, with 3.1B parameters, outperformed the bigger 7B parameter LLaVA-1.5 mannequin in complete benchmarks, showcasing the potential of smaller LMMs when optimized with appropriate knowledge and coaching methodologies.
In conclusion, TinyLLaVA represents a big step ahead in multimodal studying. By leveraging small-scale LLMs, the framework presents a extra accessible and environment friendly strategy to integrating language and visible data. This improvement enhances our understanding of multimodal programs and opens up new potentialities for his or her software in real-world eventualities. The success of TinyLLaVA underscores the significance of modern options in advancing the capabilities of synthetic intelligence.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
![]()
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link


