
[ad_1]
Growing and enhancing fashions able to effectively managing intensive sequential information is paramount in fashionable computational fields. This necessity is especially vital in pure language processing, the place fashions should course of lengthy textual content streams seamlessly, retaining context with out compromising processing pace or accuracy. One of many key challenges inside this scope is the standard reliance on Transformer architectures, which, regardless of their broad adoption, undergo from quadratic computational complexity.
Current analysis consists of the Transformer structure, which, regardless of its efficacy, suffers from excessive computational prices with longer sequences. Alternate options like linear consideration mechanisms and state area fashions have been developed to cut back this value, although usually on the expense of efficiency. With its gated consideration mechanism and exponential transferring common, the LLAMA mannequin and the MEGA structure purpose to handle these limitations. Nonetheless, these fashions nonetheless face challenges in scaling and effectivity, notably in large-scale pretraining and dealing with prolonged information sequences.
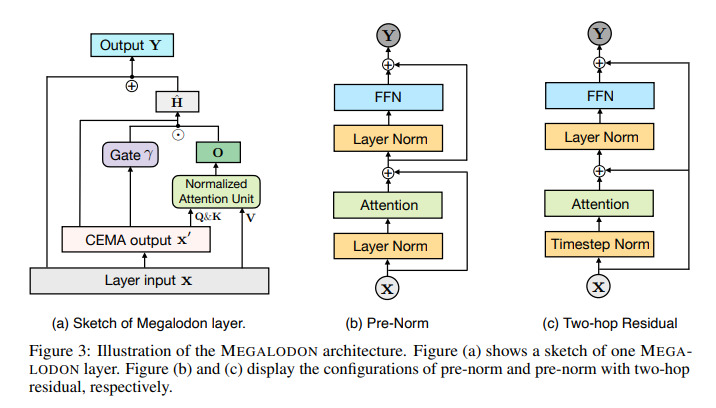
Researchers from Meta, the College of Southern California, Carnegie Mellon College, and the College of California San Diego have launched MEGALODON, a mannequin designed to effectively deal with sequences of limitless size—a functionality that present fashions wrestle with. By integrating a Complicated Exponential Transferring Common (CEMA) and timestep normalization, MEGALODON gives lowered computational load and improved scalability, distinguishing itself from conventional Transformer fashions exhibiting quadratic computational development with sequence size.
MEGALODON employs a mixture of CEMA, timestep normalization, and a normalized consideration mechanism. These technical elements are essential for modeling lengthy sequences with excessive effectivity and low reminiscence value. The mannequin has been rigorously examined on varied language processing benchmarks, together with multi-turn conversations, long-document comprehension, and intensive language modeling duties. MEGALODON was benchmarked in opposition to datasets particularly designed for long-context situations, such because the Scrolls dataset for long-context QA duties and PG19, which consists of lengthy literary texts to display its efficacy and flexibility.
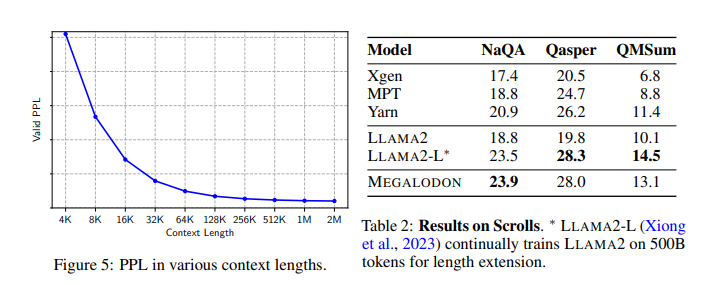
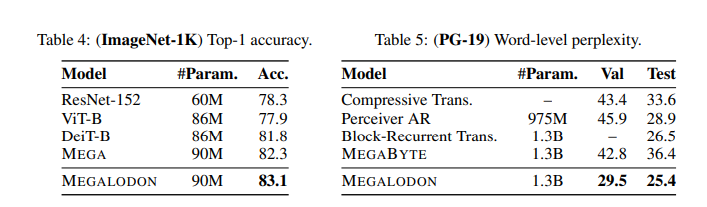
MEGALODON demonstrated quantifiable enhancements in efficiency metrics. It recorded a coaching lack of 1.70, positioned between LLAMA2-7B, which registered a lack of 1.75, and LLAMA2-13B at 1.67. Concerning particular benchmarks, MEGALODON outperformed a regular Transformer mannequin by reaching a decrease perplexity price on the Scrolls dataset, measuring at 23, in comparison with the Transformer’s 30. These outcomes affirm MEGALODON‘s superior processing capabilities for prolonged sequential information, substantiating its effectivity and effectiveness throughout different linguistic duties.
To conclude, the MEGALODON mannequin marks a big development in sequence modeling, addressing the inefficiencies of conventional Transformer architectures with modern approaches like CEMA and timestep normalization. By reaching a coaching lack of 1.70 and demonstrating improved efficiency on difficult benchmarks such because the Scrolls dataset, MEGALODON proves its functionality to deal with intensive sequences successfully. This analysis enhances the processing of lengthy information sequences and units a brand new commonplace for future developments in pure language processing and associated fields.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 40k+ ML SubReddit
For Content material Partnership, Please Fill Out This Type Right here..
![]()
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link


