
[ad_1]
Cada vez mais as ferramentas de IA apoiam a tomada de decisão e ajudam na criação modelos que identificam tendências e padrões de comportamentos que, juntamente com regras de negócios, permitem que as empresas tomem decisões mais assertivas, seja qual for sua área de atuação. As análises mais avançadas incluem modelos sofisticados de estatística como Machine Studying, Otimização, Redes Neurais, Análises Comportamentais e outras técnicas sofisticadas de Knowledge Mining.
O ciclo analítico é uma espécie de roteiro para que a análise de dados seja eficaz. Suas etapas de incluem:
definição do problema;
busca e exploração de dados;
criação de modelos de predição;
escolha do melhor modelo e validação da sua capacidade de predição, com eventuais processos de “retreino”, ou mesmo de substituição de um modelo;
gestão destes modelos.
Vamos passar por estes pontos.
Na área da saúde já se aplica um conjunto de técnicas de IA que apoia no planejamento de modelos de gestão em saúde. Os modelos preditivos permitem a identificação de padrões existentes, incluindo variáveis demográficas e comportamentais – especialmente fatores que levam os pacientes a terem um perfil de custo elevado. Isso permite calcular os impactos financeiros nos planos de saúde.
Estas técnicas têm ajudado não só a indústria, mas também na promoção de políticas de saúde e bem-estar para estes pacientes e suas famílias, visando qualidade de vida e longevidade. Por meio de modelos de análise preditiva é possível realizar previsões de taxas de internação, probabilidade de infecções e doenças. Também é possível identificar pacientes para programas de saúde e bem-estar, auxiliando nas iniciativas de medicina preventiva, abordagem elementary na promoção da saúde.
Além disso, é possível, resolver um problema de negócio: identificar na população coberta por um plano de saúde potenciais pacientes com propensão a ter doenças graves, como diabetes e hipertensão, impactando nas margens e nas renegociações de reajustes dos planos. Tal questão pode ser resolvida através da obtenção de bases de dados históricas de pacientes. Utilizando-se modelos de Machine Studying, identificamos padrões para a prevalência de uma determinada doença grave, e, assim, criamos um modelo preditivo para identificação desta doença nos novos participantes dos planos de saúde.
Estas técnicas têm ajudado não só a indústria, mas também na promoção de políticas de saúde e bem-estar para estes pacientes e suas famílias, visando qualidade de vida e longevidade.
Esta visão preditiva de prevalência de doenças graves na carteira gera inúmeros resultados para os negócios das empresas da área, além de ser benéfica à saúde, favorecendo a implantação de programas bem-sucedidos de bem-estar. Entre os benefícios está a melhor acurácia dos valores projetados de despesas com doenças graves e os insumos para renovação dos contratos dos planos de saúde.
Em resumo, os modelos preditivos podem ajudar as seguradoras de saúde a tomar decisões informadas, melhorar a eficiência operacional e reduzir custos, permitindo que a indústria de seguro saúde proceed operando de modo sustentável, oferecendo coberturas e serviços que atendam às demandas da população.
Estudo de caso – predição de doença cardio-vascular e detecção precoce
As doenças cardiovasculares são uma das principais causas de morte no Brasil, com prevalência em 6,1% da população. Quando detectadas precocemente é possível reduzir os infartos em 80%, assim como a mortalidade em 45%. Na busca por fomentar o acesso a base de dados clínicos que possam auxiliar no desenvolvimento de modelos preditivos para essas doenças, foi criado um conjunto de dados de modo a possibilitar o desenvolvimento de modelos preditivos para doenças cardiovasculares. Esta base (criada para fins acadêmicos) com dados sintéticos tem cerca de 425.000 registros, com o seguinte format: 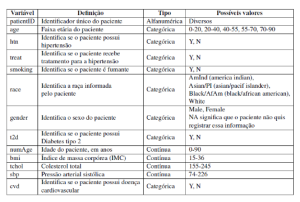
Fonte: https://git.io/fjm0H
Uma vez importada essa base, ela já está disponível para utilização. O SAS® Knowledge Studio permite que façamos uma série de ajustes, aplicação de filtros, união com outras tabelas, enfim, toda atividade de tratamento de dados, criando um framework único e reutilizável. Abaixo temos uma ideia dos dados importados no formato authentic: 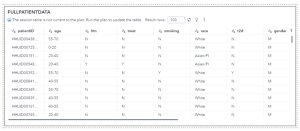
Dentro da solução, foi feita a mudança dos nomes dos campos. Os formatos estavam corretos, por esta razão não houve nenhum ajuste. Outro tratamento foi restringir a base de estudo utilizando apenas os pacientes com 55 anos ou mais. Veja no quadro abaixo como a ferramenta facilita esta tarefa:
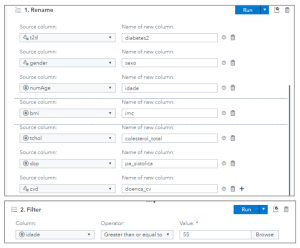
Uma vez que os dados foram tratados, passamos à fase de análise e discovery dos dados. A ferramenta já tem uma série de modelos pré–formatados, e ainda permite a customização e criação de novos relatórios que podem ser facilmente criados. Aqui vemos um exemplo no SAS® Visible Analytics:
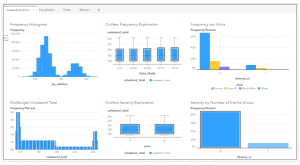
Seguindo nestas análises, a ferramenta permite que sejam criados vários modelos utilizando ferramentas de machine studying que podem dar indícios sobre quais algoritmos são mais apropriados. Neste exemplo, utilizamos uma árvore de decisão para fazer uma análise das relações entre as variáveis preditoras e qual o peso de cada variável na explicação da variável resposta (doenca_cv).
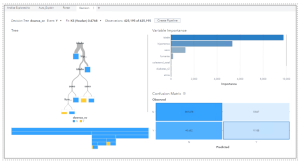
Após esta fase de discovery dos dados, passamos para a modelagem. Para este tipo de problema, um bom início é utilizar um algoritmo que faça a predição de o paciente ter doença cardiovascular ou não.
A regressão logística é uma técnica de análise de dados que usa matemática para encontrar as relações entre dois fatores de dados. Em seguida, essa relação é usada para prever o valor de um desses fatores com base no outro. A previsão geralmente tem um número finito de resultados, como sim ou não. Vamos inicar por aqui.
Dentro da solução, o SAS® Mannequin Studio fornece uma série de possibilidades de modelagem. A partir da disponibilização dos dados, e quais serão as variáveis preditoras e qual será a variável resposta, já conseguimos criar os modelos e saber qual é o poder preditor dos modelos obtidos, sua acurácia, bem como outros indicadores de qualidade:
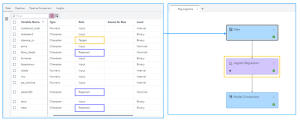
Observamos aqui, na aba de dados, que algumas variáveis não foram consideradas para o modelo. “faixa_idade”, por ter grande correlação com “idade” e assim trazer instabilidade para o modelo, “deal with” (tratamento de diabetes tipo 2), pois também tem correlação com “diabetes2”, e “patient_ID” não tem qualquer utilidade para o modelo.
Uma vez configurada a variável-resposta “doenca_cv” e as demais sendo variáveis enter, a solução permite facilmente que seja construído um modelo de regressão logística, e gerando uma série de relatórios, gráficos e análises sobre o peso de cada variável preditora na explicação da variável-resposta:
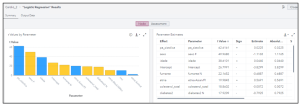
Além disso, temos indicadores da capacidade preditora do modelo, como o KS, acurácia e a área sob a curva ROC:

A plataforma também é capaz de dar a possibilidade de o analista testar e comparar modelos gerados por diferentes algoritmos. A grande vantagem é que ao ter a flexibilidade de comparar modelos de regressão logística com outros modelos de machine studying, como gradient boosting, random forest e outros, o analista poderá usufruir do melhor de cada um deles e aprimorar a qualidade de seus resultados analíticos.
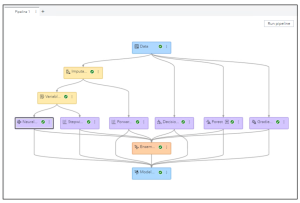
Para cada um destes modelos são gerados vários relatórios de interpretabilidade, que trazem segurança ao analista de dados quanto à explicabilidade dos modelos e como cada variável está sendo tratada e considerada. Além disso, também são calculados os indicadores de efficiency de cada modelo, conforme vemos abaixo:
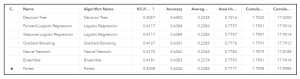
Para este tipo de problema, consideramos o KS como sendo a métrica que indica qual é o melhor modelo, aquele que tem o maior KS. Assim, o modelo “forest” é considerado o modelo campeão, que uma vez registrado será utilizado para tomada de decisões, ou seja, resolver um problema de negócio.

Neste caso, vamos utilizar este modelo para projetar um valor de despesa adicional dentro de uma carteira de seguro saúde em função da predição de um participante do plano ter ou não doença cardiovascular, além de criar uma base com estes participantes para alguma ação preventiva, como fazer parte de um programa de saúde e bem estar, entre outras ações.
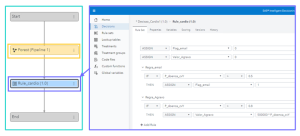
O modelo de forest que foi criado será consumido aqui, e sobre ele aplicamos as seguintes regras de decisão:
Se a probabilidade de o paciente ter doença cardiovascular for maior do que 50%, a base na qual ele está cadastrado vai receber uma flag que o indica ser elegível a participar de um programa de saúde e bem-estar;
Se a probabilidade de o paciente ter doença cardiovascular for maior do que 80%, será considerado um valor adicional de despesas igual a probabilidade de ter a doença vezes R$ 500.000.
Os exemplos aqui serão bastante simples, mas o módulo de tomada de decisão (SAS® Inteligent Decisioning) pode ser utilizado para trazer respostas bastante complexas, combinado regras de decisão, utilização de modelos, criação de funções, grupos de tratamento, consulta de tabelas e bases de dados, and so forth.
[ad_2]
Source link


