
[ad_1]
Some of the helpful software patterns for generative AI workloads is Retrieval Augmented Era (RAG). Within the RAG sample, we discover items of reference content material associated to an enter immediate by performing similarity searches on embeddings. Embeddings seize the data content material in our bodies of textual content, permitting pure language processing (NLP) fashions to work with language in a numeric kind. Embeddings are simply vectors of floating level numbers, so we are able to analyze them to assist reply three vital questions: Is our reference knowledge altering over time? Are the questions customers are asking altering over time? And at last, how properly is our reference knowledge overlaying the questions being requested?
On this submit, you’ll study a few of the concerns for embedding vector evaluation and detecting indicators of embedding drift. As a result of embeddings are an vital supply of knowledge for NLP fashions typically and generative AI options particularly, we want a technique to measure whether or not our embeddings are altering over time (drifting). On this submit, you’ll see an instance of performing drift detection on embedding vectors utilizing a clustering method with giant language fashions (LLMS) deployed from Amazon SageMaker JumpStart. You’ll additionally have the ability to discover these ideas via two offered examples, together with an end-to-end pattern software or, optionally, a subset of the applying.
Overview of RAG
The RAG sample enables you to retrieve data from exterior sources, similar to PDF paperwork, wiki articles, or name transcripts, after which use that data to enhance the instruction immediate despatched to the LLM. This permits the LLM to reference extra related data when producing a response. For instance, in case you ask an LLM tips on how to make chocolate chip cookies, it might probably embrace data from your personal recipe library. On this sample, the recipe textual content is transformed into embedding vectors utilizing an embedding mannequin, and saved in a vector database. Incoming questions are transformed to embeddings, after which the vector database runs a similarity search to seek out associated content material. The query and the reference knowledge then go into the immediate for the LLM.
Let’s take a better take a look at the embedding vectors that get created and tips on how to carry out drift evaluation on these vectors.
Evaluation on embedding vectors
Embedding vectors are numeric representations of our knowledge so evaluation of those vectors can present perception into our reference knowledge that may later be used to detect potential indicators of drift. Embedding vectors characterize an merchandise in n-dimensional house, the place n is commonly giant. For instance, the GPT-J 6B mannequin, used on this submit, creates vectors of measurement 4096. To measure drift, assume that our software captures embedding vectors for each reference knowledge and incoming prompts.
We begin by performing dimension discount utilizing Principal Part Evaluation (PCA). PCA tries to cut back the variety of dimensions whereas preserving a lot of the variance within the knowledge. On this case, we attempt to discover the variety of dimensions that preserves 95% of the variance, which ought to seize something inside two normal deviations.
Then we use Okay-Means to determine a set of cluster facilities. Okay-Means tries to group factors collectively into clusters such that every cluster is comparatively compact and the clusters are as distant from one another as potential.
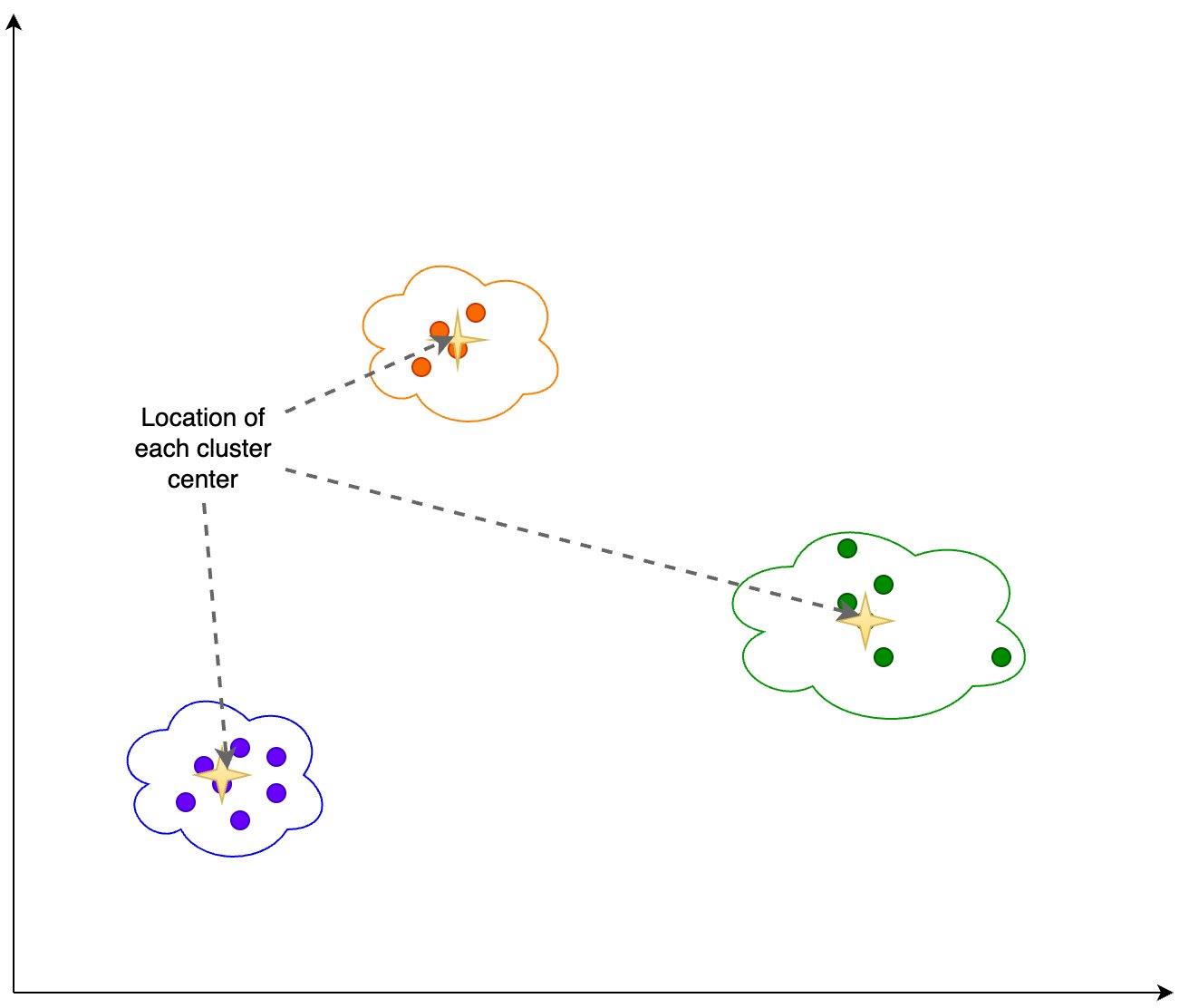
We calculate the next data based mostly on the clustering output proven within the following determine:
The variety of dimensions in PCA that designate 95% of the variance
The placement of every cluster heart, or centroid
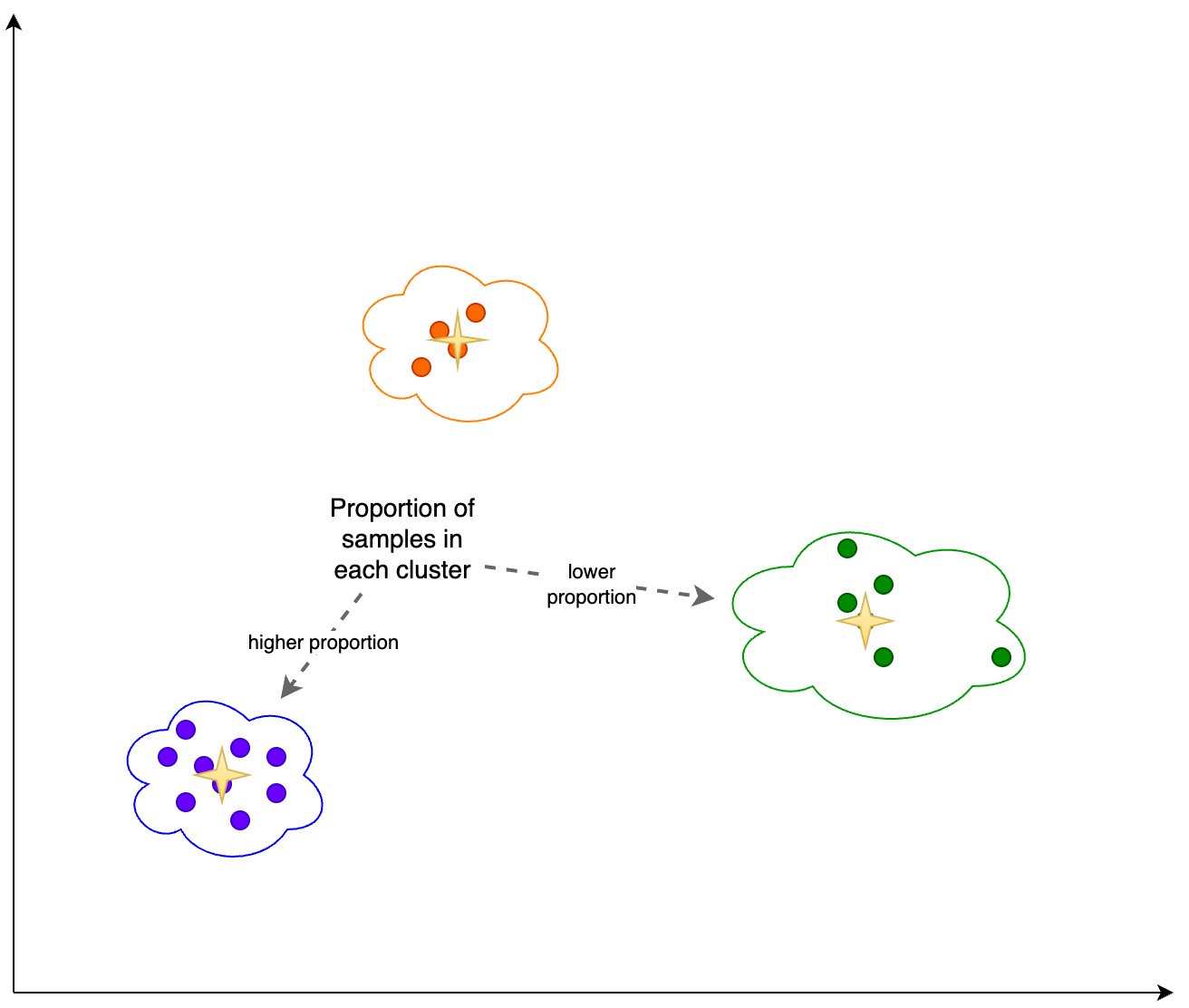
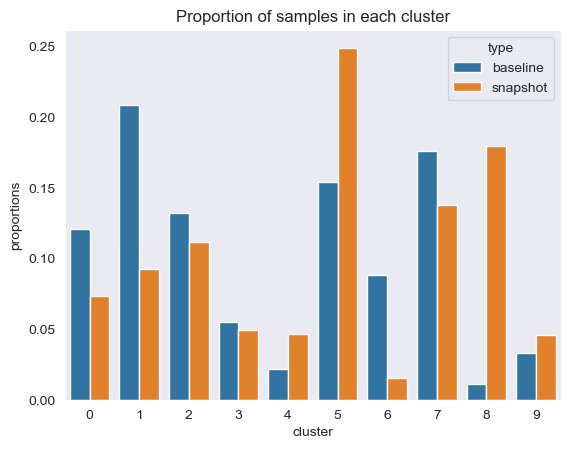
Moreover, we take a look at the proportion (greater or decrease) of samples in every cluster, as proven within the following determine.
Lastly, we use this evaluation to calculate the next:
Inertia – Inertia is the sum of squared distances to cluster centroids, which measures how properly the info was clustered utilizing Okay-Means.
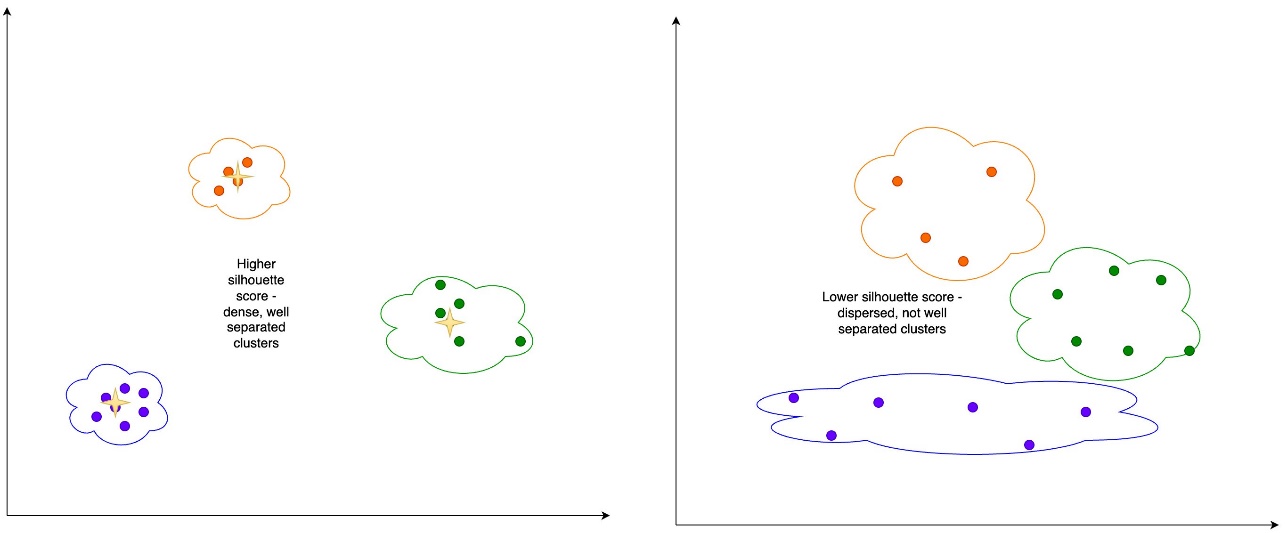
Silhouette rating – The silhouette rating is a measure for the validation of the consistency inside clusters, and ranges from -1 to 1. A price near 1 implies that the factors in a cluster are near the opposite factors in the identical cluster and much from the factors of the opposite clusters. A visible illustration of the silhouette rating might be seen within the following determine.
We will periodically seize this data for snapshots of the embeddings for each the supply reference knowledge and the prompts. Capturing this knowledge permits us to investigate potential indicators of embedding drift.
Detecting embedding drift
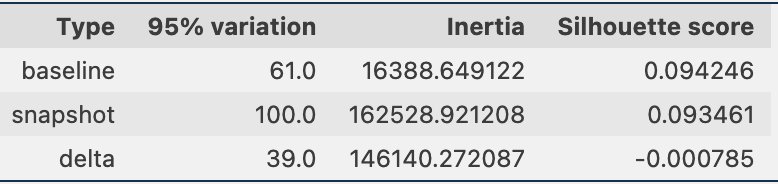
Periodically, we are able to evaluate the clustering data via snapshots of the info, which incorporates the reference knowledge embeddings and the immediate embeddings. First, we are able to evaluate the variety of dimensions wanted to clarify 95% of the variation within the embedding knowledge, the inertia, and the silhouette rating from the clustering job. As you’ll be able to see within the following desk, in comparison with a baseline, the newest snapshot of embeddings requires 39 extra dimensions to clarify the variance, indicating that our knowledge is extra dispersed. The inertia has gone up, indicating that the samples are in mixture farther away from their cluster facilities. Moreover, the silhouette rating has gone down, indicating that the clusters will not be as properly outlined. For immediate knowledge, that may point out that the kinds of questions coming into the system are overlaying extra matters.
Subsequent, within the following determine, we are able to see how the proportion of samples in every cluster has modified over time. This could present us whether or not our newer reference knowledge is broadly much like the earlier set, or covers new areas.
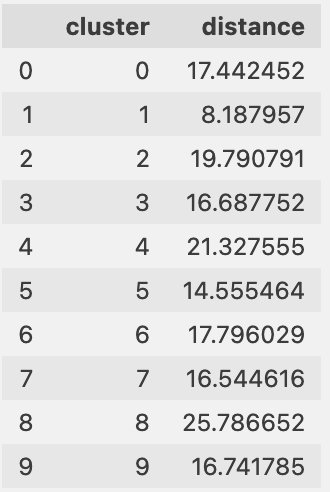
Lastly, we are able to see if the cluster facilities are transferring, which might present drift within the data within the clusters, as proven within the following desk.
Reference knowledge protection for incoming questions
We will additionally consider how properly our reference knowledge aligns to the incoming questions. To do that, we assign every immediate embedding to a reference knowledge cluster. We compute the space from every immediate to its corresponding heart, and take a look at the imply, median, and normal deviation of these distances. We will retailer that data and see the way it adjustments over time.
The next determine exhibits an instance of analyzing the space between the immediate embedding and reference knowledge facilities over time.
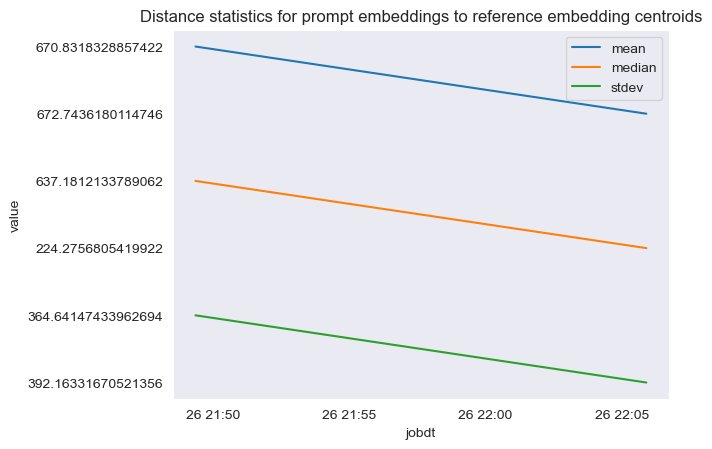
As you’ll be able to see, the imply, median, and normal deviation distance statistics between immediate embeddings and reference knowledge facilities is lowering between the preliminary baseline and the newest snapshot. Though absolutely the worth of the space is troublesome to interpret, we are able to use the tendencies to find out if the semantic overlap between reference knowledge and incoming questions is getting higher or worse over time.
Pattern software
With a purpose to collect the experimental outcomes mentioned within the earlier part, we constructed a pattern software that implements the RAG sample utilizing embedding and technology fashions deployed via SageMaker JumpStart and hosted on Amazon SageMaker real-time endpoints.
The applying has three core parts:
We use an interactive move, which features a person interface for capturing prompts, mixed with a RAG orchestration layer, utilizing LangChain.
The information processing move extracts knowledge from PDF paperwork and creates embeddings that get saved in Amazon OpenSearch Service. We additionally use these within the last embedding drift evaluation element of the applying.
The embeddings are captured in Amazon Easy Storage Service (Amazon S3) through Amazon Kinesis Knowledge Firehose, and we run a mix of AWS Glue extract, remodel, and cargo (ETL) jobs and Jupyter notebooks to carry out the embedding evaluation.
The next diagram illustrates the end-to-end structure.
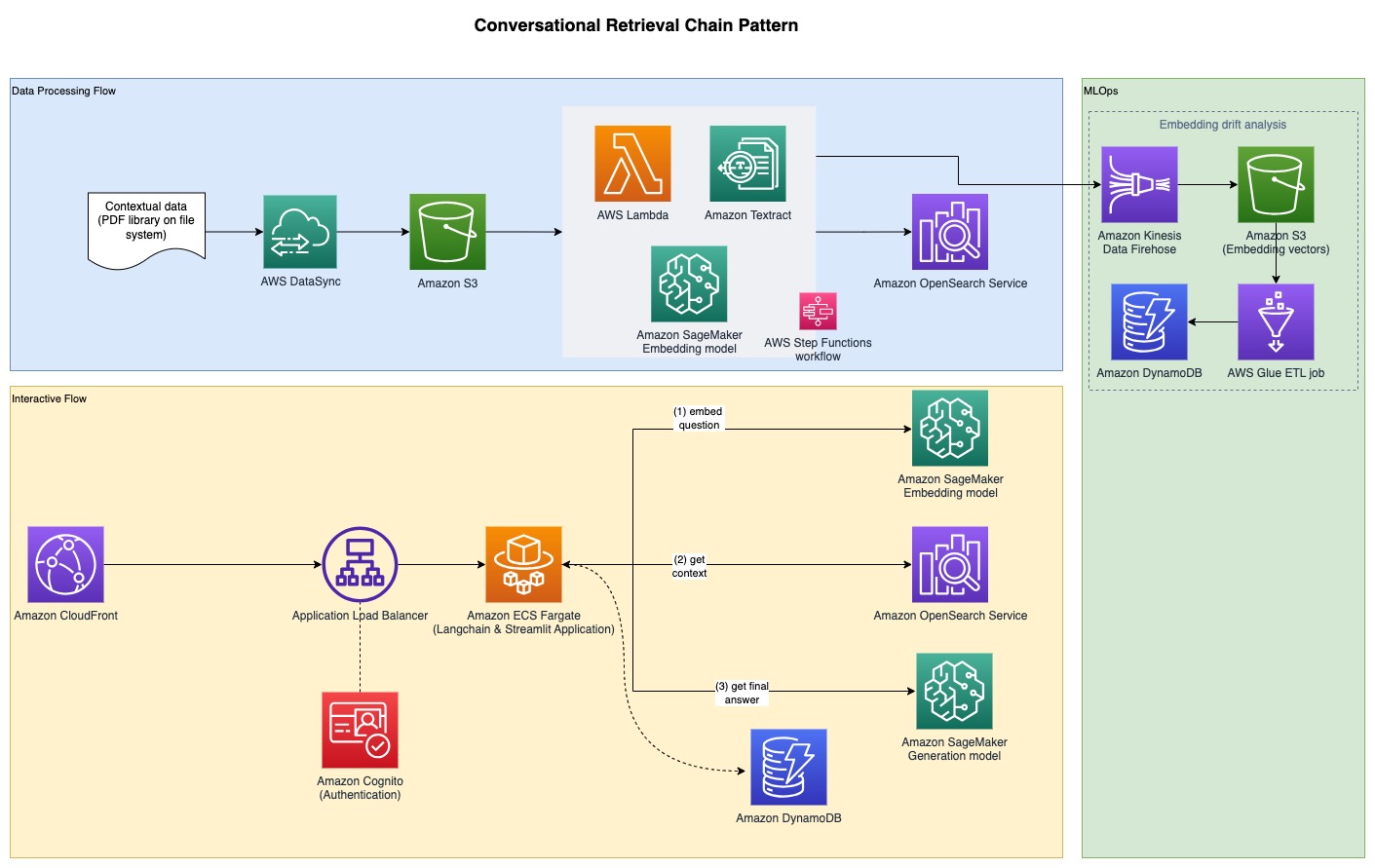
The total pattern code is out there on GitHub. The offered code is out there in two totally different patterns:
Pattern full-stack software with a Streamlit frontend – This offers an end-to-end software, together with a person interface utilizing Streamlit for capturing prompts, mixed with the RAG orchestration layer, utilizing LangChain operating on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate
Backend software – For people who don’t wish to deploy the total software stack, you’ll be able to optionally select to solely deploy the backend AWS Cloud Improvement Package (AWS CDK) stack, after which use the Jupyter pocket book offered to carry out RAG orchestration utilizing LangChain
To create the offered patterns, there are a number of conditions detailed within the following sections, beginning with deploying the generative and textual content embedding fashions then transferring on to the extra conditions.
Deploy fashions via SageMaker JumpStart
Each patterns assume the deployment of an embedding mannequin and generative mannequin. For this, you’ll deploy two fashions from SageMaker JumpStart. The primary mannequin, GPT-J 6B, is used because the embedding mannequin and the second mannequin, Falcon-40b, is used for textual content technology.
You possibly can deploy every of those fashions via SageMaker JumpStart from the AWS Administration Console, Amazon SageMaker Studio, or programmatically. For extra data, seek advice from The best way to use JumpStart basis fashions. To simplify the deployment, you should use the offered pocket book derived from notebooks robotically created by SageMaker JumpStart. This pocket book pulls the fashions from the SageMaker JumpStart ML hub and deploys them to 2 separate SageMaker real-time endpoints.
The pattern pocket book additionally has a cleanup part. Don’t run that part but, as a result of it’s going to delete the endpoints simply deployed. You’ll full the cleanup on the finish of the walkthrough.
After confirming profitable deployment of the endpoints, you’re able to deploy the total pattern software. Nevertheless, in case you’re extra focused on exploring solely the backend and evaluation notebooks, you’ll be able to optionally deploy solely that, which is roofed within the subsequent part.
Possibility 1: Deploy the backend software solely
This sample lets you deploy the backend resolution solely and work together with the answer utilizing a Jupyter pocket book. Use this sample in case you don’t wish to construct out the total frontend interface.
Conditions
You must have the next conditions:
A SageMaker JumpStart mannequin endpoint deployed – Deploy the fashions to SageMaker real-time endpoints utilizing SageMaker JumpStart, as beforehand outlined
Deployment parameters – Report the next:
Textual content mannequin endpoint title – The endpoint title of the textual content technology mannequin deployed with SageMaker JumpStart
Embeddings mannequin endpoint title – The endpoint title of the embedding mannequin deployed with SageMaker JumpStart
Deploy the assets utilizing the AWS CDK
Use the deployment parameters famous within the earlier part to deploy the AWS CDK stack. For extra details about AWS CDK set up, seek advice from Getting began with the AWS CDK.
Ensure that Docker is put in and operating on the workstation that will likely be used for AWS CDK deployment. Consult with Get Docker for extra steering.
Alternatively, you’ll be able to enter the context values in a file referred to as cdk.context.json within the pattern1-rag/cdk listing and run cdk deploy BackendStack –exclusively.
The deployment will print out outputs, a few of which will likely be wanted to run the pocket book. Earlier than you can begin query and answering, embed the reference paperwork, as proven within the subsequent part.
Embed reference paperwork
For this RAG method, reference paperwork are first embedded with a textual content embedding mannequin and saved in a vector database. On this resolution, an ingestion pipeline has been constructed that intakes PDF paperwork.
An Amazon Elastic Compute Cloud (Amazon EC2) occasion has been created for the PDF doc ingestion and an Amazon Elastic File System (Amazon EFS) file system is mounted on the EC2 occasion to save lots of the PDF paperwork. An AWS DataSync job is run each hour to fetch PDF paperwork discovered within the EFS file system path and add them to an S3 bucket to start out the textual content embedding course of. This course of embeds the reference paperwork and saves the embeddings in OpenSearch Service. It additionally saves an embedding archive to an S3 bucket via Kinesis Knowledge Firehose for later evaluation.
To ingest the reference paperwork, full the next steps:
Retrieve the pattern EC2 occasion ID that was created (see the AWS CDK output JumpHostId) and join utilizing Session Supervisor, a functionality of AWS Techniques Supervisor. For directions, seek advice from Hook up with your Linux occasion with AWS Techniques Supervisor Session Supervisor.
Go to the listing /mnt/efs/fs1, which is the place the EFS file system is mounted, and create a folder referred to as ingest:
Add your reference PDF paperwork to the ingest listing.
The DataSync job is configured to add all recordsdata discovered on this listing to Amazon S3 to start out the embedding course of.
The DataSync job runs on an hourly schedule; you’ll be able to optionally begin the duty manually to start out the embedding course of instantly for the PDF paperwork you added.
To start out the duty, find the duty ID from the AWS CDK output DataSyncTaskID and begin the duty with defaults.
After the embeddings are created, you can begin the RAG query and answering via a Jupyter pocket book, as proven within the subsequent part.
Query and answering utilizing a Jupyter pocket book
Full the next steps:
Retrieve the SageMaker pocket book occasion title from the AWS CDK output NotebookInstanceName and connect with JupyterLab from the SageMaker console.
Go to the listing fmops/full-stack/pattern1-rag/notebooks/.
Open and run the pocket book query-llm.ipynb within the pocket book occasion to carry out query and answering utilizing RAG.
Make sure that to make use of the conda_python3 kernel for the pocket book.
This sample is beneficial to discover the backend resolution with no need to provision further conditions which might be required for the full-stack software. The following part covers the implementation of a full-stack software, together with each the frontend and backend parts, to offer a person interface for interacting together with your generative AI software.
Possibility 2: Deploy the full-stack pattern software with a Streamlit frontend
This sample lets you deploy the answer with a person frontend interface for query and answering.
Conditions
To deploy the pattern software, it’s essential to have the next conditions:
SageMaker JumpStart mannequin endpoint deployed – Deploy the fashions to your SageMaker real-time endpoints utilizing SageMaker JumpStart, as outlined within the earlier part, utilizing the offered notebooks.
Amazon Route 53 hosted zone – Create an Amazon Route 53 public hosted zone to make use of for this resolution. You too can use an current Route 53 public hosted zone, similar to instance.com.
AWS Certificates Supervisor certificates – Provision an AWS Certificates Supervisor (ACM) TLS certificates for the Route 53 hosted zone area title and its relevant subdomains, similar to instance.com and *.instance.com for all subdomains. For directions, seek advice from Requesting a public certificates. This certificates is used to configure HTTPS on Amazon CloudFront and the origin load balancer.
Deployment parameters – Report the next:
Frontend software customized area title – A customized area title used to entry the frontend pattern software. The area title offered is used to create a Route 53 DNS file pointing to the frontend CloudFront distribution; for instance, app.instance.com.
Load balancer origin customized area title – A customized area title used for the CloudFront distribution load balancer origin. The area title offered is used to create a Route 53 DNS file pointing to the origin load balancer; for instance, app-lb.instance.com.
Route 53 hosted zone ID – The Route 53 hosted zone ID to host the customized domains offered; for instance, ZXXXXXXXXYYYYYYYYY.
Route 53 hosted zone title – The title of the Route 53 hosted zone to host the customized domains offered; for instance, instance.com.
ACM certificates ARN – The ARN of the ACM certificates for use with the customized area offered.
Textual content mannequin endpoint title – The endpoint title of the textual content technology mannequin deployed with SageMaker JumpStart.
Embeddings mannequin endpoint title – The endpoint title of the embedding mannequin deployed with SageMaker JumpStart.
Deploy the assets utilizing the AWS CDK
Use the deployment parameters you famous within the conditions to deploy the AWS CDK stack. For extra data, seek advice from Getting began with the AWS CDK.
Make sure that Docker is put in and operating on the workstation that will likely be used for the AWS CDK deployment.
Within the previous code, -c represents a context worth, within the type of the required conditions, offered on enter. Alternatively, you’ll be able to enter the context values in a file referred to as cdk.context.json within the pattern1-rag/cdk listing and run cdk deploy –all.
Notice that we specify the Area within the file bin/cdk.ts. Configuring ALB entry logs requires a specified Area. You possibly can change this Area earlier than deployment.
The deployment will print out the URL to entry the Streamlit software. Earlier than you can begin query and answering, it is advisable to embed the reference paperwork, as proven within the subsequent part.
Embed the reference paperwork
For a RAG method, reference paperwork are first embedded with a textual content embedding mannequin and saved in a vector database. On this resolution, an ingestion pipeline has been constructed that intakes PDF paperwork.
As we mentioned within the first deployment choice, an instance EC2 occasion has been created for the PDF doc ingestion and an EFS file system is mounted on the EC2 occasion to save lots of the PDF paperwork. A DataSync job is run each hour to fetch PDF paperwork discovered within the EFS file system path and add them to an S3 bucket to start out the textual content embedding course of. This course of embeds the reference paperwork and saves the embeddings in OpenSearch Service. It additionally saves an embedding archive to an S3 bucket via Kinesis Knowledge Firehose for later evaluation.
To ingest the reference paperwork, full the next steps:
Retrieve the pattern EC2 occasion ID that was created (see the AWS CDK output JumpHostId) and join utilizing Session Supervisor.
Go to the listing /mnt/efs/fs1, which is the place the EFS file system is mounted, and create a folder referred to as ingest:
Add your reference PDF paperwork to the ingest listing.
The DataSync job is configured to add all recordsdata discovered on this listing to Amazon S3 to start out the embedding course of.
The DataSync job runs on an hourly schedule. You possibly can optionally begin the duty manually to start out the embedding course of instantly for the PDF paperwork you added.
To start out the duty, find the duty ID from the AWS CDK output DataSyncTaskID and begin the duty with defaults.
Query and answering
After the reference paperwork have been embedded, you can begin the RAG query and answering by visiting the URL to entry the Streamlit software. An Amazon Cognito authentication layer is used, so it requires making a person account within the Amazon Cognito person pool deployed through the AWS CDK (see the AWS CDK output for the person pool title) for first-time entry to the applying. For directions on creating an Amazon Cognito person, seek advice from Creating a brand new person within the AWS Administration Console.
Embed drift evaluation
On this part, we present you tips on how to carry out drift evaluation by first making a baseline of the reference knowledge embeddings and immediate embeddings, after which making a snapshot of the embeddings over time. This lets you evaluate the baseline embeddings to the snapshot embeddings.
Create an embedding baseline for the reference knowledge and immediate
To create an embedding baseline of the reference knowledge, open the AWS Glue console and choose the ETL job embedding-drift-analysis. Set the parameters for the ETL job as follows and run the job:
Set –job_type to BASELINE.
Set –out_table to the Amazon DynamoDB desk for reference embedding knowledge. (See the AWS CDK output DriftTableReference for the desk title.)
Set –centroid_table to the DynamoDB desk for reference centroid knowledge. (See the AWS CDK output CentroidTableReference for the desk title.)
Set –data_path to the S3 bucket with the prefix; for instance, s3://<REPLACE_WITH_BUCKET_NAME>/embeddingarchive/. (See the AWS CDK output BucketName for the bucket title.)
Equally, utilizing the ETL job embedding-drift-analysis, create an embedding baseline of the prompts. Set the parameters for the ETL job as follows and run the job:
Set –job_type to BASELINE
Set –out_table to the DynamoDB desk for immediate embedding knowledge. (See the AWS CDK output DriftTablePromptsName for the desk title.)
Set –centroid_table to the DynamoDB desk for immediate centroid knowledge. (See the AWS CDK output CentroidTablePrompts for the desk title.)
Set –data_path to the S3 bucket with the prefix; for instance, s3://<REPLACE_WITH_BUCKET_NAME>/promptarchive/. (See the AWS CDK output BucketName for the bucket title.)
Create an embedding snapshot for the reference knowledge and immediate
After you ingest further data into OpenSearch Service, run the ETL job embedding-drift-analysis once more to snapshot the reference knowledge embeddings. The parameters would be the identical because the ETL job that you just ran to create the embedding baseline of the reference knowledge as proven within the earlier part, apart from setting the –job_type parameter to SNAPSHOT.
Equally, to snapshot the immediate embeddings, run the ETL job embedding-drift-analysis once more. The parameters would be the identical because the ETL job that you just ran to create the embedding baseline for the prompts as proven within the earlier part, apart from setting the –job_type parameter to SNAPSHOT.
Examine the baseline to the snapshot
To check the embedding baseline and snapshot for reference knowledge and prompts, use the offered pocket book pattern1-rag/notebooks/drift-analysis.ipynb.
To have a look at embedding comparability for reference knowledge or prompts, change the DynamoDB desk title variables (tbl and c_tbl) within the pocket book to the suitable DynamoDB desk for every run of the pocket book.
The pocket book variable tbl ought to be modified to the suitable drift desk title. The next is an instance of the place to configure the variable within the pocket book.

The desk names might be retrieved as follows:
For the reference embedding knowledge, retrieve the drift desk title from the AWS CDK output DriftTableReference
For the immediate embedding knowledge, retrieve the drift desk title from the AWS CDK output DriftTablePromptsName
As well as, the pocket book variable c_tbl ought to be modified to the suitable centroid desk title. The next is an instance of the place to configure the variable within the pocket book.

The desk names might be retrieved as follows:
For the reference embedding knowledge, retrieve the centroid desk title from the AWS CDK output CentroidTableReference
For the immediate embedding knowledge, retrieve the centroid desk title from the AWS CDK output CentroidTablePrompts
Analyze the immediate distance from the reference knowledge
First, run the AWS Glue job embedding-distance-analysis. This job will discover out which cluster, from the Okay-Means analysis of the reference knowledge embeddings, that every immediate belongs to. It then calculates the imply, median, and normal deviation of the space from every immediate to the middle of the corresponding cluster.
You possibly can run the pocket book pattern1-rag/notebooks/distance-analysis.ipynb to see the tendencies within the distance metrics over time. This gives you a way of the general pattern within the distribution of the immediate embedding distances.
The pocket book pattern1-rag/notebooks/prompt-distance-outliers.ipynb is an AWS Glue pocket book that appears for outliers, which will help you determine whether or not you’re getting extra prompts that aren’t associated to the reference knowledge.
Monitor similarity scores
All similarity scores from OpenSearch Service are logged in Amazon CloudWatch beneath the rag namespace. The dashboard RAG_Scores exhibits the common rating and the whole variety of scores ingested.
Clear up
To keep away from incurring future prices, delete all of the assets that you just created.
Delete the deployed SageMaker fashions
Reference the cleanup up part of the offered instance pocket book to delete the deployed SageMaker JumpStart fashions, or you’ll be able to delete the fashions on the SageMaker console.
Delete the AWS CDK assets
In the event you entered your parameters in a cdk.context.json file, clear up as follows:
In the event you entered your parameters on the command line and solely deployed the backend software (the backend AWS CDK stack), clear up as follows:
In the event you entered your parameters on the command line and deployed the total resolution (the frontend and backend AWS CDK stacks), clear up as follows:
Conclusion
On this submit, we offered a working instance of an software that captures embedding vectors for each reference knowledge and prompts within the RAG sample for generative AI. We confirmed tips on how to carry out clustering evaluation to find out whether or not reference or immediate knowledge is drifting over time, and the way properly the reference knowledge covers the kinds of questions customers are asking. In the event you detect drift, it might probably present a sign that the surroundings has modified and your mannequin is getting new inputs that it is probably not optimized to deal with. This permits for proactive analysis of the present mannequin towards altering inputs.
In regards to the Authors
 Abdullahi Olaoye is a Senior Options Architect at Amazon Net Providers (AWS). Abdullahi holds a MSC in Pc Networking from Wichita State College and is a broadcast creator that has held roles throughout varied expertise domains similar to DevOps, infrastructure modernization and AI. He’s at the moment targeted on Generative AI and performs a key position in helping enterprises to architect and construct cutting-edge options powered by Generative AI. Past the realm of expertise, he finds pleasure within the artwork of exploration. When not crafting AI options, he enjoys touring together with his household to discover new locations.
Abdullahi Olaoye is a Senior Options Architect at Amazon Net Providers (AWS). Abdullahi holds a MSC in Pc Networking from Wichita State College and is a broadcast creator that has held roles throughout varied expertise domains similar to DevOps, infrastructure modernization and AI. He’s at the moment targeted on Generative AI and performs a key position in helping enterprises to architect and construct cutting-edge options powered by Generative AI. Past the realm of expertise, he finds pleasure within the artwork of exploration. When not crafting AI options, he enjoys touring together with his household to discover new locations.
 Randy DeFauw is a Senior Principal Options Architect at AWS. He holds an MSEE from the College of Michigan, the place he labored on pc imaginative and prescient for autonomous autos. He additionally holds an MBA from Colorado State College. Randy has held quite a lot of positions within the expertise house, starting from software program engineering to product administration. In entered the Massive Knowledge house in 2013 and continues to discover that space. He’s actively engaged on initiatives within the ML house and has introduced at quite a few conferences together with Strata and GlueCon.
Randy DeFauw is a Senior Principal Options Architect at AWS. He holds an MSEE from the College of Michigan, the place he labored on pc imaginative and prescient for autonomous autos. He additionally holds an MBA from Colorado State College. Randy has held quite a lot of positions within the expertise house, starting from software program engineering to product administration. In entered the Massive Knowledge house in 2013 and continues to discover that space. He’s actively engaged on initiatives within the ML house and has introduced at quite a few conferences together with Strata and GlueCon.
 Shelbee Eigenbrode is a Principal AI and Machine Studying Specialist Options Architect at Amazon Net Providers (AWS). She has been in expertise for twenty-four years spanning a number of industries, applied sciences, and roles. She is at the moment specializing in combining her DevOps and ML background into the area of MLOps to assist clients ship and handle ML workloads at scale. With over 35 patents granted throughout varied expertise domains, she has a ardour for steady innovation and utilizing knowledge to drive enterprise outcomes. Shelbee is a co-creator and teacher of the Sensible Knowledge Science specialization on Coursera. She can also be the Co-Director of Girls In Massive Knowledge (WiBD), Denver chapter. In her spare time, she likes to spend time along with her household, associates, and overactive canines.
Shelbee Eigenbrode is a Principal AI and Machine Studying Specialist Options Architect at Amazon Net Providers (AWS). She has been in expertise for twenty-four years spanning a number of industries, applied sciences, and roles. She is at the moment specializing in combining her DevOps and ML background into the area of MLOps to assist clients ship and handle ML workloads at scale. With over 35 patents granted throughout varied expertise domains, she has a ardour for steady innovation and utilizing knowledge to drive enterprise outcomes. Shelbee is a co-creator and teacher of the Sensible Knowledge Science specialization on Coursera. She can also be the Co-Director of Girls In Massive Knowledge (WiBD), Denver chapter. In her spare time, she likes to spend time along with her household, associates, and overactive canines.
[ad_2]
Source link


