
[ad_1]
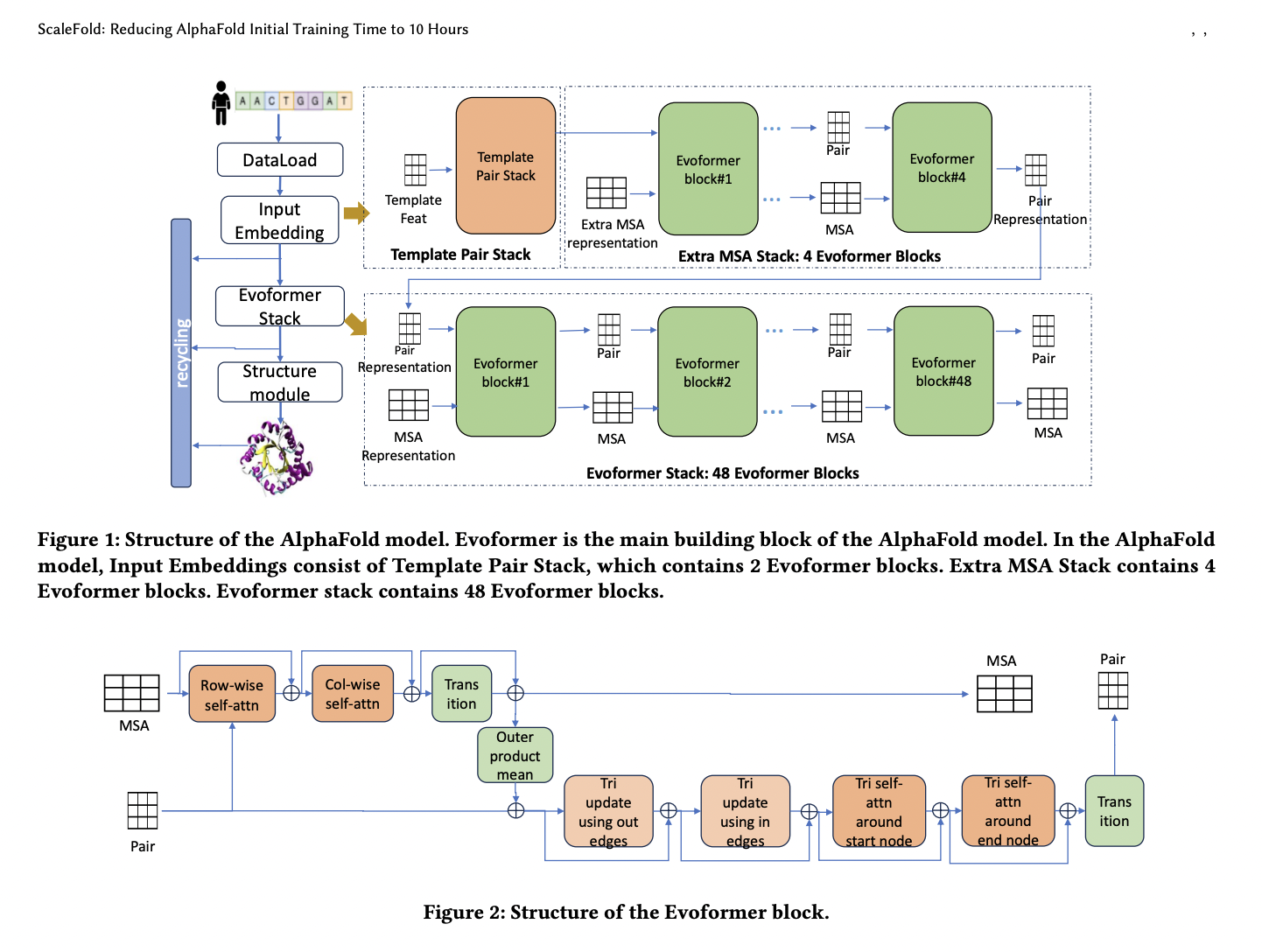
In recent times, deep studying has been efficient in high-performance computing. Surrogate fashions proceed to advance, surpassing physics-based simulations in accuracy and utility. This AI-driven progress is clear in protein folding, exemplified by RoseTTAFold, AlphaFold2, OpenFold, and FastFold, democratizing protein structure-based drug discovery. AlphaFold, a breakthrough by DeepMind, achieved accuracy corresponding to experimental strategies, addressing a longstanding organic problem. Regardless of its success, AlphaFold’s coaching course of, counting on a sequence consideration mechanism, is time and resource-intensive, hindering analysis velocity. Efforts to boost coaching effectivity, reminiscent of these by OpenFold, DeepSpeed4Science, and FastFold, goal scalability, a pivotal problem in accelerating AlphaFold’s coaching.
Incorporating AlphaFold coaching into the MLPerf HPC v3.0 benchmark underscores its significance. Nevertheless, this coaching course of presents important challenges. Firstly, regardless of its comparatively modest parameter depend, the AlphaFold mannequin calls for in depth reminiscence as a consequence of Evoformer’s distinctive consideration mechanism, which scales cubically with enter measurement. OpenFold addressed this with gradient checkpointing however on the expense of coaching velocity. Moreover, AlphaFold’s coaching entails a mess of memory-bound kernels, dominating computation time. Additionally, essential operations like Multi-Head Consideration and Layer Normalization devour substantial time, limiting the effectiveness of knowledge parallelism.
NVIDIA researchers present a research that totally analyzes AlphaFold’s coaching, figuring out key impediments to scalability: inefficient distributed communication and underutilization of compute assets. The researchers suggest a number of optimizations. They introduce a non-blocking information pipeline to alleviate slow-worker points and make use of fine-grained optimizations, reminiscent of using CUDA Graphs to cut back overhead. Additionally, they design specialised Triton kernels for essential computation patterns, fuse fragmented computations, and optimize kernel configurations. This optimized coaching methodology, named ScaleFold, goals to boost total effectivity and scalability.
The researchers extensively look at AlphaFold’s coaching, figuring out limitations to scalability throughout communication and computation. Options embody a non-blocking information pipeline and CUDA Graphs to mitigate communication imbalances, whereas guide and computerized kernel fusions improve computation effectivity. They addressed points like CPU overhead and imbalanced communication, proposing optimizations reminiscent of Triton kernels and low-precision assist. Asynchronous analysis and caching alleviate analysis time bottlenecks. AlphaFold coaching is scaled to 2080 NVIDIA H100 GPUs by way of systematic optimizations, finishing pretraining in 10 hours.
Evaluating ScaleFold to public OpenFold and FastFold reveals superior coaching efficiency. On A100, ScaleFold achieves step occasions of 1.88s for DAP-2, outperforming FastFold’s 2.49s and much surpassing OpenFold’s 6.19s with out DAP assist. On H100, ScaleFold displays step occasions of 0.65s for DAP-8, considerably quicker than OpenFold’s 1.80s with NoDAP. Complete evaluations exhibit ScaleFold’s developments, attaining as much as 6.2X speedup in comparison with reference fashions on NVIDIA H100. MLPerf HPC 3.0 benchmarking on Eos additional confirms ScaleFold’s effectivity, lowering coaching time to eight minutes on 2080 NVIDIA H100 GPUs, a 6X enchancment over reference fashions. Coaching from scratch on ScaleFold completes AlphaFold pretraining in underneath 10 hours, showcasing its accelerated efficiency.
The important thing contributions of this analysis are three-fold:
Researchers recognized the important thing elements that prevented the AlphaFold coaching from scaling to extra compute assets.
They launched ScaleFold, a scalable and systematic coaching methodology for the AlphaFold mannequin.
They empirically demonstrated the scalability of ScaleFold and set new data for the AlphaFold pretraining and the MLPef HPC benchmark.
To conclude, This analysis addressed the scalability challenges of AlphaFold coaching by introducing ScaleFold, a scientific strategy tailor-made to mitigate inefficient communications and overhead-dominated computations. ScaleFold incorporates a number of optimizations, together with FastFold’s DAP for GPU scaling, a Non-Blocking Knowledge Pipeline to handle batch entry inequalities, and a CUDA Graph to get rid of CPU overhead. Additionally, environment friendly Triton kernels for essential patterns, computerized fusion through torch compiler, and bfloat16 coaching are carried out to cut back step time. Asynchronous analysis and an analysis dataset cache alleviate analysis time bottlenecks. These optimizations allow ScaleFold to attain a coaching convergence time of seven.51 minutes on 2080 NVIDIA H100 GPUs in MLPerf HPC V3.0, demonstrating a 6X speedup over reference fashions. Coaching from scratch is lowered from 7 days to 10 hours, setting a brand new report in effectivity in comparison with prior works.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 40k+ ML SubReddit
![]()
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]
Source link


