
[ad_1]
Machine studying depends on knowledge as its constructing block. New datasets are a key consider analysis and the event of progressive fashions since they propel developments within the discipline. The coaching of bigger fashions on bigger datasets has resulted in a big rise within the computing value of AI experiments over time. At present, among the most influential datasets are produced by extracting textual content from the entire publicly accessible web. A few of the greatest databases ever constructed are often launched with no documentation of their contents, solely a proof of how they have been generated.
This can be a essential distinction since fashions are at the moment being skilled on giant textual content corpora with none information of the ideas, topics, toxicity, or non-public info which may be included. In the intervening time, language fashions are actually broadly utilized each day by people all around the globe. Since these AI techniques have a direct affect on individuals’s lives, it’s now important to understand each their benefits and drawbacks. Fashions can solely be taught from the info they have been skilled on, however the monumental amount and lack of public availability of pretraining corpora make it troublesome to investigate them. A handful of serious dimensions are often the main focus of labor assessing the contents of web-scale corpora, and crucially, extra work must be executed analyzing a number of datasets alongside the identical dimensions.
Consequently, earlier than deciding which dataset or datasets to make use of, machine studying practitioners want extra helpful strategies for describing distinctions between them. On this research, researchers from the Allen Institute for AI, the College of Washington and the College of California suggest to make use of a set of instruments referred to as WIMBD: WHAT’S IN MY BIG DATA, which helps practitioners quickly study large language datasets to analysis the content material of enormous textual content corpora. Moreover, they use this expertise to supply among the first immediately comparable measures throughout a number of web-scale datasets.
There are two elements to WIMBD: (1) an Elasticsearch (ES) index-based search software that enables programmatic entry to search for paperwork that include a question. ES is a search engine that makes it attainable to search out strings inside a corpus along with the texts by which they occurred and what number of occasions. (2) A MapReduce-built rely functionality that permits fast iteration throughout a complete dataset and the extraction of pertinent knowledge, such because the distribution of doc character lengths, duplicates, area counts, the identification of personally identifiable info (PII), and extra. The code for WIMBD is open supply and accessible at github.com/allenai/wimbd. It’s extensible and could also be used to index, rely, and analyze completely different corpora at a big scale. They carried out sixteen research on 10 distinct corpora together with C4, The Pile, and RedPajama which might be utilized to coach language fashions utilizing these methods.
They classify their analyses into 4 classes:
Information statistics (e.g., variety of tokens and area distribution).
Information high quality (e.g., measuring duplicate paperwork and most frequent n-grams).
Neighborhood- and society-relevant measurements (e.g., benchmark contamination and personally identifiable info detection).
Cross-corpora evaluation (e.g., verifying doc overlap and evaluating the commonest n-gram).
Determine 1 is a illustration of WIMBD. Quite a few insights on knowledge distribution and anomalies are introduced of their work.
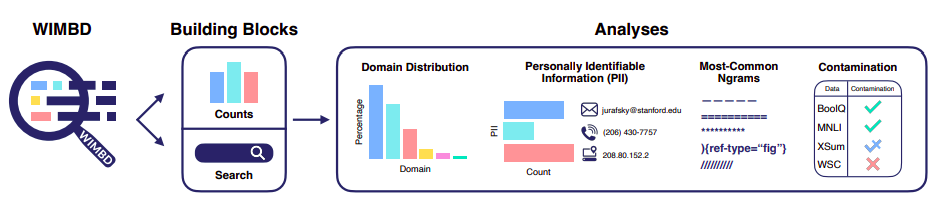
Determine 1: WIMBD overview. They supply two core functionalities, Depend and Search, which facilitate fast processing and supply entry to huge textual content corpora, therefore enabling a large number of research.
Inspecting the distribution of doc lengths, for example, reveals anomalies the place some lengths are overrepresented compared to close by lengths; these abnormalities incessantly relate to textual content that’s created from templates virtually precisely twice or paperwork which were deliberately minimize to a sure character size. One other instance can be punctuation sequences, usually the commonest n-grams. As an illustration, in The Pile, the commonest 10-gram is a splash (‘-‘) repeated ten occasions. WIMBD gives sensible insights for curating higher-quality corpora, in addition to retroactive documentation and anchoring of mannequin behaviour to their coaching knowledge. Wimbd.apps.allenai.org has an interactive demo highlighting a few of their evaluation and is launched together with this publication.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to affix our 32k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E mail E-newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
When you like our work, you’ll love our publication..
We’re additionally on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.
[ad_2]
Source link


