
[ad_1]

Deep neural networks (DNNs) have turn out to be important for fixing a variety of duties, from normal supervised studying (picture classification utilizing ViT) to meta-learning. Essentially the most commonly-used paradigm for studying DNNs is empirical threat minimization (ERM), which goals to determine a community that minimizes the typical loss on coaching knowledge factors. A number of algorithms, together with stochastic gradient descent (SGD), Adam, and Adagrad, have been proposed for fixing ERM. Nevertheless, a disadvantage of ERM is that it weights all of the samples equally, usually ignoring the uncommon and harder samples, and specializing in the better and ample samples. This results in suboptimal efficiency on unseen knowledge, particularly when the coaching knowledge is scarce.
To beat this problem, latest works have developed knowledge re-weighting strategies for enhancing ERM efficiency. Nevertheless, these approaches deal with particular studying duties (corresponding to classification) and/or require studying a further meta mannequin that predicts the weights of every knowledge level. The presence of a further mannequin considerably will increase the complexity of coaching and makes them unwieldy in observe.
In “Stochastic Re-weighted Gradient Descent by way of Distributionally Sturdy Optimization” we introduce a variant of the classical SGD algorithm that re-weights knowledge factors throughout every optimization step primarily based on their problem. Stochastic Re-weighted Gradient Descent (RGD) is a light-weight algorithm that comes with a easy closed-form expression, and will be utilized to unravel any studying process utilizing simply two strains of code. At any stage of the training course of, RGD merely reweights a knowledge level because the exponential of its loss. We empirically exhibit that the RGD reweighting algorithm improves the efficiency of quite a few studying algorithms throughout varied duties, starting from supervised studying to meta studying. Notably, we present enhancements over state-of-the-art strategies on DomainBed and Tabular classification. Furthermore, the RGD algorithm additionally boosts efficiency for BERT utilizing the GLUE benchmarks and ViT on ImageNet-1K.
Distributionally sturdy optimization
Distributionally sturdy optimization (DRO) is an method that assumes a “worst-case” knowledge distribution shift might happen, which might hurt a mannequin’s efficiency. If a mannequin has focussed on figuring out few spurious options for prediction, these “worst-case” knowledge distribution shifts might result in the misclassification of samples and, thus, a efficiency drop. DRO optimizes the loss for samples in that “worst-case” distribution, making the mannequin sturdy to perturbations (e.g., eradicating a small fraction of factors from a dataset, minor up/down weighting of information factors, and many others.) within the knowledge distribution. Within the context of classification, this forces the mannequin to put much less emphasis on noisy options and extra emphasis on helpful and predictive options. Consequently, fashions optimized utilizing DRO are likely to have higher generalization ensures and stronger efficiency on unseen samples.
Impressed by these outcomes, we develop the RGD algorithm as a method for fixing the DRO goal. Particularly, we deal with Kullback–Leibler divergence-based DRO, the place one provides perturbations to create distributions which are near the unique knowledge distribution within the KL divergence metric, enabling a mannequin to carry out nicely over all potential perturbations.
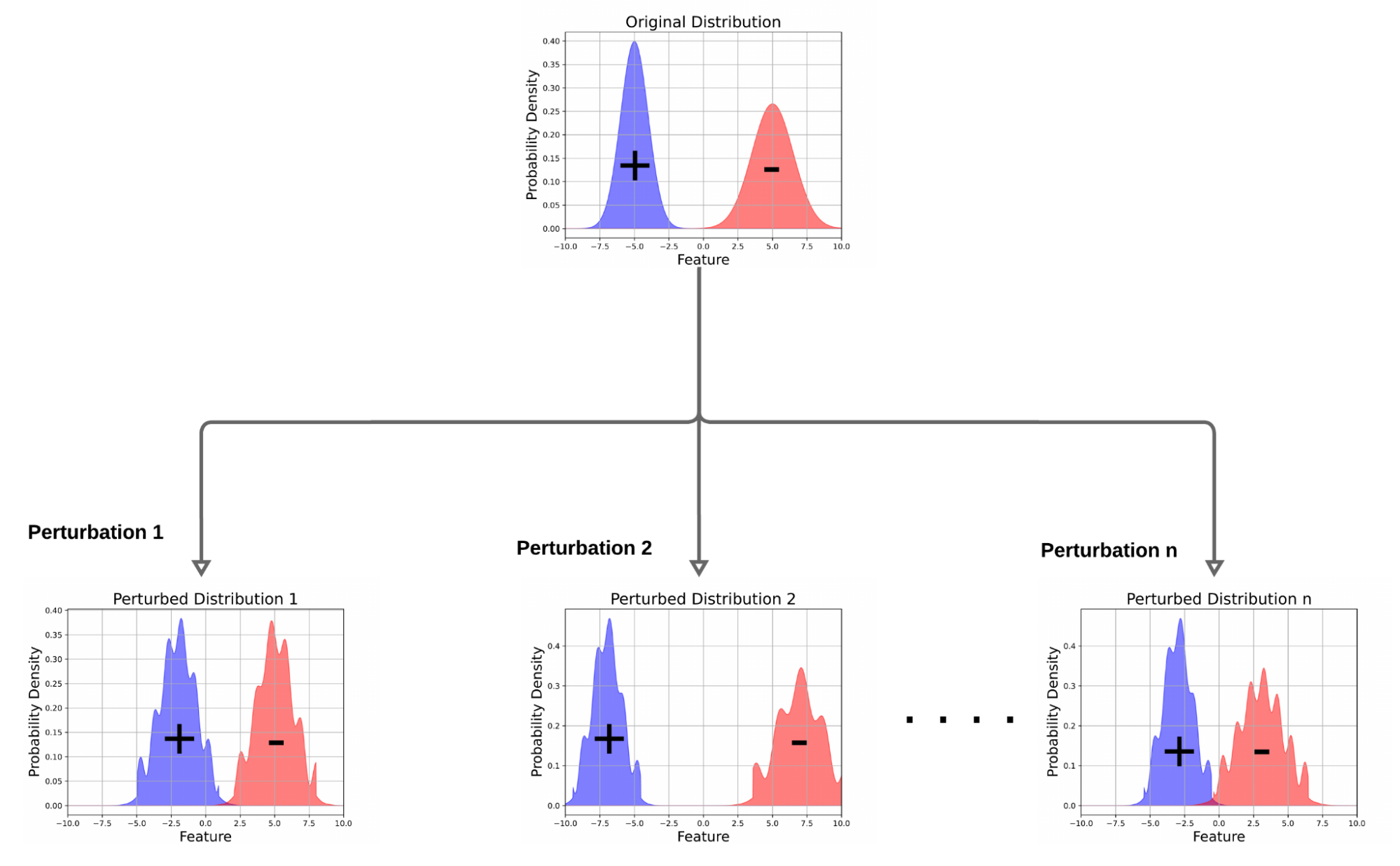 Determine illustrating DRO. In distinction to ERM, which learns a mannequin that minimizes anticipated loss over unique knowledge distribution, DRO learns a mannequin that performs nicely on a number of perturbed variations of the unique knowledge distribution.
Determine illustrating DRO. In distinction to ERM, which learns a mannequin that minimizes anticipated loss over unique knowledge distribution, DRO learns a mannequin that performs nicely on a number of perturbed variations of the unique knowledge distribution.
Stochastic re-weighted gradient descent
Contemplate a random subset of samples (referred to as a mini-batch), the place every knowledge level has an related loss Li. Conventional algorithms like SGD give equal significance to all of the samples within the mini-batch, and replace the parameters of the mannequin by descending alongside the averaged gradients of the lack of these samples. With RGD, we reweight every pattern within the mini-batch and provides extra significance to factors that the mannequin identifies as harder. To be exact, we use the loss as a proxy to calculate the problem of some extent, and reweight it by the exponential of its loss. Lastly, we replace the mannequin parameters by descending alongside the weighted common of the gradients of the samples.
Resulting from stability concerns, in our experiments we clip and scale the loss earlier than computing its exponential. Particularly, we clip the loss at some threshold T, and multiply it with a scalar that’s inversely proportional to the edge. An necessary side of RGD is its simplicity because it doesn’t depend on a meta mannequin to compute the weights of information factors. Moreover, it may be carried out with two strains of code, and mixed with any fashionable optimizers (corresponding to SGD, Adam, and Adagrad.
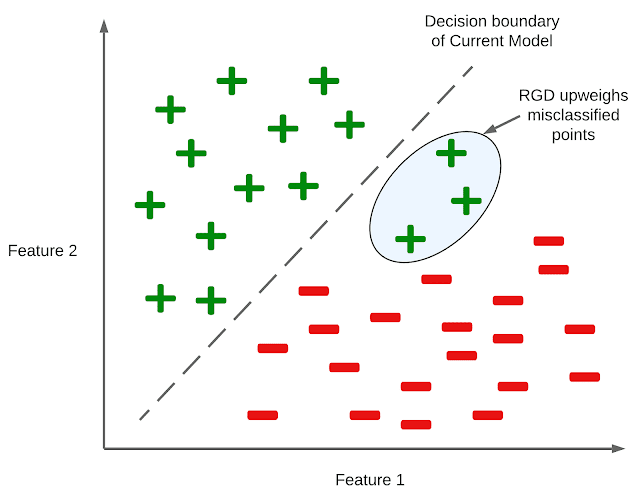 Determine illustrating the intuitive concept behind RGD in a binary classification setting. Characteristic 1 and Characteristic 2 are the options out there to the mannequin for predicting the label of a knowledge level. RGD upweights the information factors with excessive losses which have been misclassified by the mannequin.
Determine illustrating the intuitive concept behind RGD in a binary classification setting. Characteristic 1 and Characteristic 2 are the options out there to the mannequin for predicting the label of a knowledge level. RGD upweights the information factors with excessive losses which have been misclassified by the mannequin.
Outcomes
We current empirical outcomes evaluating RGD with state-of-the-art strategies on normal supervised studying and area adaptation (discuss with the paper for outcomes on meta studying). In all our experiments, we tune the clipping stage and the training charge of the optimizer utilizing a held-out validation set.
Supervised studying
We consider RGD on a number of supervised studying duties, together with language, imaginative and prescient, and tabular classification. For the duty of language classification, we apply RGD to the BERT mannequin skilled on the Basic Language Understanding Analysis (GLUE) benchmark and present that RGD outperforms the BERT baseline by +1.94% with an ordinary deviation of 0.42%. To guage RGD’s efficiency on imaginative and prescient classification, we apply RGD to the ViT-S mannequin skilled on the ImageNet-1K dataset, and present that RGD outperforms the ViT-S baseline by +1.01% with an ordinary deviation of 0.23%. Furthermore, we carry out speculation assessments to substantiate that these outcomes are statistically important with a p-value that’s lower than 0.05.
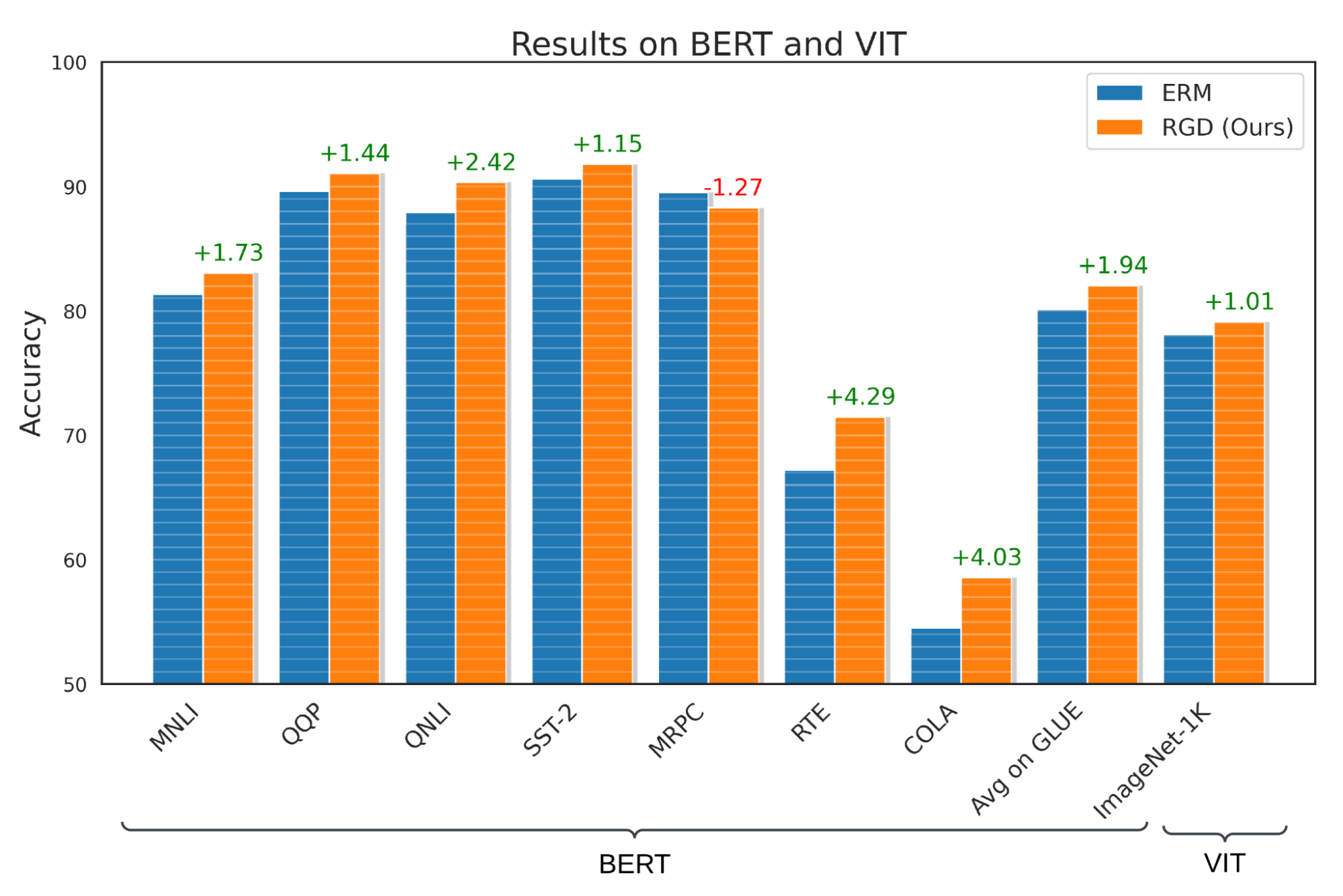 RGD’s efficiency on language and imaginative and prescient classification utilizing GLUE and Imagenet-1K benchmarks. Notice that MNLI, QQP, QNLI, SST-2, MRPC, RTE and COLA are numerous datasets which comprise the GLUE benchmark.
RGD’s efficiency on language and imaginative and prescient classification utilizing GLUE and Imagenet-1K benchmarks. Notice that MNLI, QQP, QNLI, SST-2, MRPC, RTE and COLA are numerous datasets which comprise the GLUE benchmark.
For tabular classification, we use MET as our baseline, and think about varied binary and multi-class datasets from UC Irvine’s machine studying repository. We present that making use of RGD to the MET framework improves its efficiency by 1.51% and 1.27% on binary and multi-class tabular classification, respectively, reaching state-of-the-art efficiency on this area.


Efficiency of RGD for classification of varied tabular datasets.
Area generalization
To guage RGD’s generalization capabilities, we use the usual DomainBed benchmark, which is usually used to check a mannequin’s out-of-domain efficiency. We apply RGD to FRR, a latest method that improved out-of-domain benchmarks, and present that RGD with FRR performs a median of 0.7% higher than the FRR baseline. Moreover, we affirm with speculation assessments that the majority benchmark outcomes (aside from Workplace Residence) are statistically important with a p-value lower than 0.05.
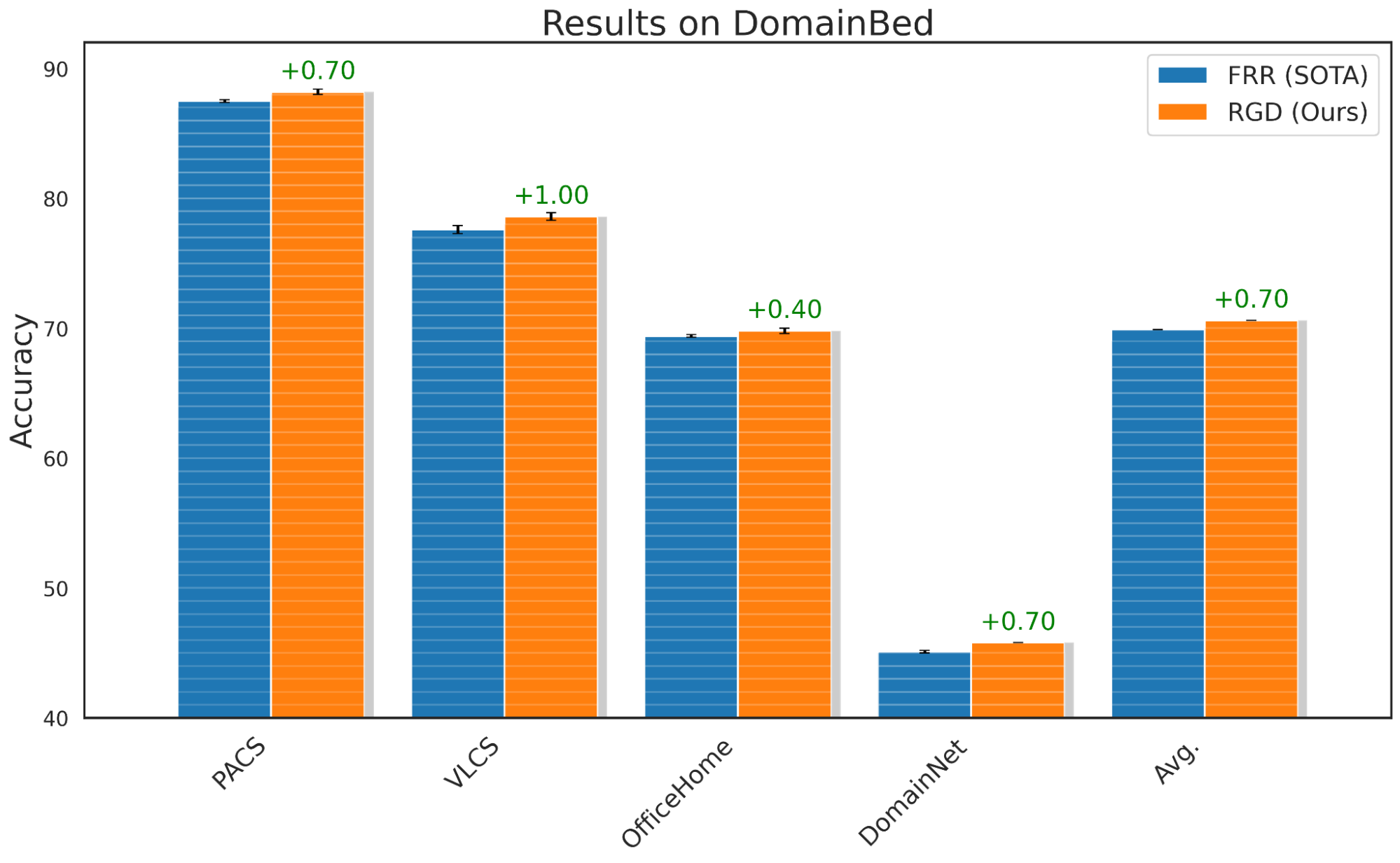 Efficiency of RGD on DomainBed benchmark for distributional shifts.
Efficiency of RGD on DomainBed benchmark for distributional shifts.
Class imbalance and equity
To exhibit that fashions discovered utilizing RGD carry out nicely regardless of class imbalance, the place sure lessons within the dataset are underrepresented, we evaluate RGD’s efficiency with ERM on long-tailed CIFAR-10. We report that RGD improves the accuracy of baseline ERM by a median of two.55% with an ordinary deviation of 0.23%. Moreover, we carry out speculation assessments and ensure that these outcomes are statistically important with a p-value of lower than 0.05.
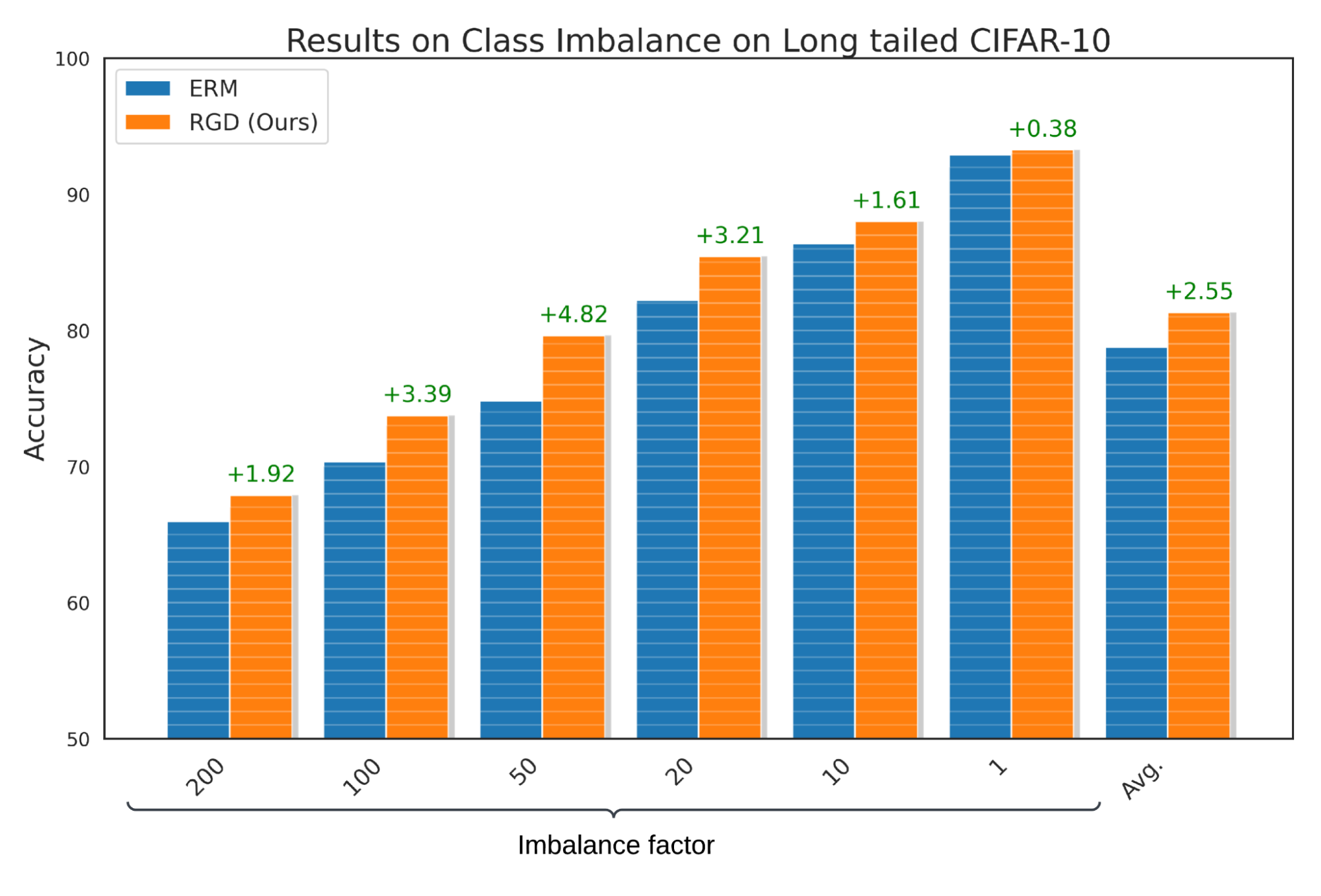 Efficiency of RGD on the long-tailed Cifar-10 benchmark for sophistication imbalance area.
Efficiency of RGD on the long-tailed Cifar-10 benchmark for sophistication imbalance area.
Limitations
The RGD algorithm was developed utilizing fashionable analysis datasets, which have been already curated to take away corruptions (e.g., noise and incorrect labels). Subsequently, RGD might not present efficiency enhancements in situations the place coaching knowledge has a excessive quantity of corruptions. A possible method to deal with such situations is to use an outlier removing method to the RGD algorithm. This outlier removing method needs to be able to filtering out outliers from the mini-batch and sending the remaining factors to our algorithm.
Conclusion
RGD has been proven to be efficient on a wide range of duties, together with out-of-domain generalization, tabular illustration studying, and sophistication imbalance. It’s easy to implement and will be seamlessly built-in into current algorithms with simply two strains of code change. Total, RGD is a promising method for enhancing the efficiency of DNNs, and will assist push the boundaries in varied domains.
Acknowledgements
The paper described on this weblog submit was written by Ramnath Kumar, Arun Sai Suggala, Dheeraj Nagaraj and Kushal Majmundar. We lengthen our honest gratitude to the nameless reviewers, Prateek Jain, Pradeep Shenoy, Anshul Nasery, Lovish Madaan, and the quite a few devoted members of the machine studying and optimization workforce at Google Analysis India for his or her invaluable suggestions and contributions to this work.
[ad_2]
Source link


