
[ad_1]
Deep neural networks like convolutional neural networks (CNNs) have revolutionized numerous pc imaginative and prescient duties, from picture classification to object detection and segmentation. As fashions grew bigger and extra advanced, their accuracy soared. Nonetheless, deploying these resource-hungry giants on units with restricted computing energy, akin to embedded programs or edge platforms, turned more and more difficult.

Information distillation (Fig. 2) emerged as a possible resolution, providing a option to practice compact “scholar” fashions guided by bigger “trainer” fashions. The core thought was to switch the trainer’s information to the scholar throughout coaching, distilling the trainer’s experience. However this course of had its personal set of hurdles – coaching the resource-intensive trainer mannequin being one in every of them.
Researchers have beforehand explored numerous strategies to leverage the facility of soppy labels – likelihood distributions over courses that seize inter-class similarities – for information distillation. Some investigated the affect of extraordinarily massive trainer fashions, whereas others experimented with crowd-sourced mushy labels or decoupled information switch. Just a few even ventured into teacher-free information distillation by manually designing regularization distributions from laborious labels.

However what if we may generate high-quality mushy labels with out counting on a big trainer mannequin or expensive crowd-sourcing? This intriguing query spurred the event of a novel method referred to as ReffAKD (Useful resource-efficient Autoencoder-based Information Distillation) proven in Fig 3. On this research, the researchers harnessed the facility of autoencoders – neural networks that be taught compact information representations by reconstructing it. By leveraging these representations, they may seize important options and calculate class similarities, successfully mimicking a trainer mannequin’s habits with out coaching one.
In contrast to randomly producing mushy labels from laborious labels, ReffAKD’s autoencoder is educated to encode enter photographs right into a hidden illustration that implicitly captures traits defining every class. This discovered illustration turns into delicate to the underlying options that distinguish completely different courses, encapsulating wealthy details about picture options and their corresponding courses, very similar to a educated trainer’s understanding of sophistication relationships.
On the coronary heart of ReffAKD lies a fastidiously crafted convolutional autoencoder (CAE). Its encoder contains three convolutional layers, every with 4×4 kernels, padding of 1, and a stride of two, regularly rising the variety of filters from 12 to 24 and eventually 48. The bottleneck layer produces a compact function vector whose dimensionality varies based mostly on the dataset (e.g., 768 for CIFAR-100, 3072 for Tiny Imagenet, and 48 for Trend MNIST). The decoder mirrors the encoder’s structure, reconstructing the unique enter from this compressed illustration.
However how does this autoencoder allow information distillation? Throughout coaching, the autoencoder learns to encode enter photographs right into a hidden illustration that implicitly captures class-defining traits. In different phrases, this illustration turns into delicate to the underlying options that distinguish completely different courses.
The researchers randomly choose 40 samples from every class to generate mushy labels and calculate the cosine similarity between their encoded representations. This similarity rating populates a matrix, the place every row represents a category, and every column corresponds to its similarity with different courses. After averaging and making use of softmax, they get hold of a mushy likelihood distribution reflecting inter-class relationships.
To coach the scholar mannequin, the researchers make use of a tailor-made loss operate that mixes Cross-Entropy loss with Kullback-Leibler Divergence between the scholar’s outputs and the autoencoder-generated mushy labels. This method encourages the scholar to be taught the bottom fact and the intricate class similarities encapsulated within the mushy labels.
Reference: https://arxiv.org/pdf/2404.09886.pdf
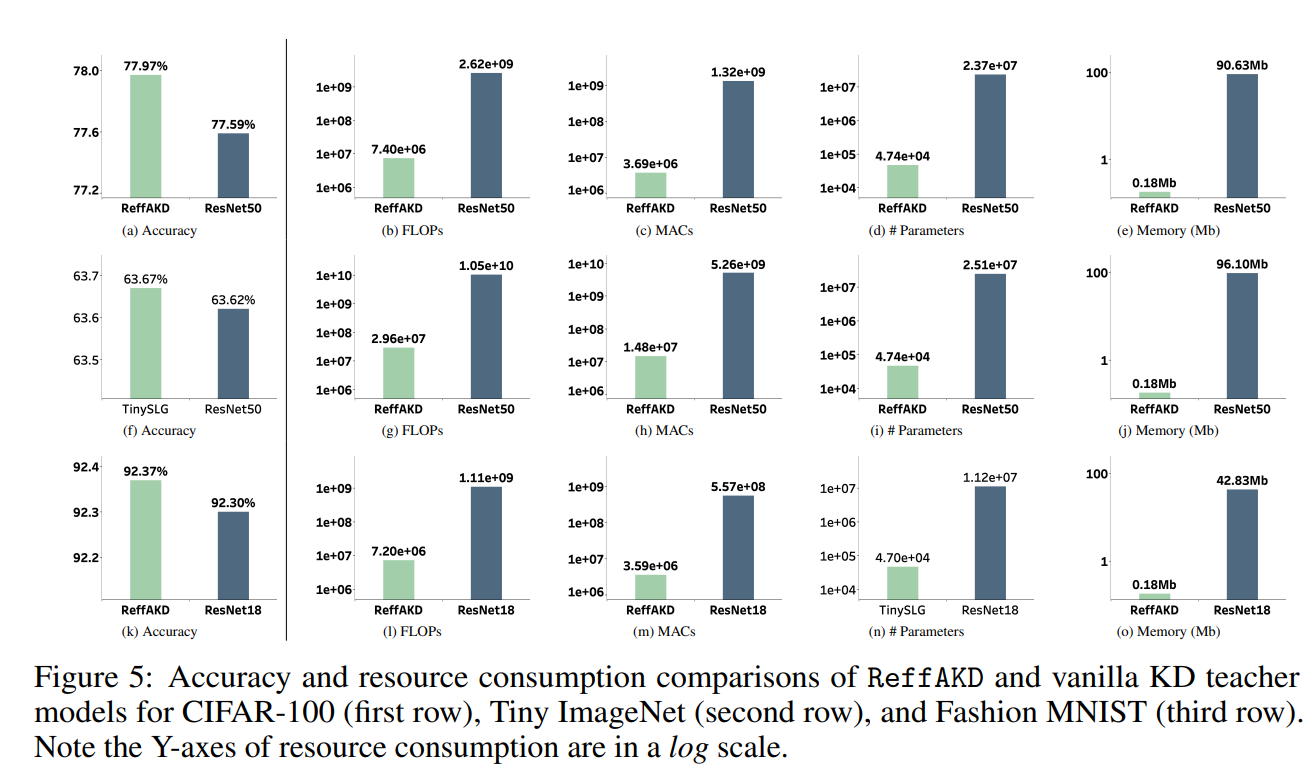
The researchers evaluated ReffAKD on three benchmark datasets: CIFAR-100, Tiny Imagenet, and Trend MNIST. Throughout these numerous duties, their method persistently outperformed vanilla information distillation, attaining top-1 accuracy of 77.97% on CIFAR-100 (vs. 77.57% for vanilla KD), 63.67% on Tiny Imagenet (vs. 63.62%), and spectacular outcomes on the easier Trend MNIST dataset as proven in Determine 5. Furthermore, ReffAKD’s useful resource effectivity shines by means of, particularly on advanced datasets like Tiny Imagenet, the place it consumes considerably fewer sources than vanilla KD whereas delivering superior efficiency. ReffAKD additionally exhibited seamless compatibility with present logit-based information distillation strategies, opening up prospects for additional efficiency positive factors by means of hybridization.
Whereas ReffAKD has demonstrated its potential in pc imaginative and prescient, the researchers envision its applicability extending to different domains, akin to pure language processing. Think about utilizing a small RNN-based autoencoder to derive sentence embeddings and distill compact fashions like TinyBERT or different BERT variants for textual content classification duties. Furthermore, the researchers consider that their method may present direct supervision to bigger fashions, probably unlocking additional efficiency enhancements with out counting on a pre-trained trainer mannequin.
In abstract, ReffAKD provides a useful contribution to the deep studying group by democratizing information distillation. Eliminating the necessity for resource-intensive trainer fashions opens up new prospects for researchers and practitioners working in resource-constrained environments, enabling them to harness the advantages of this highly effective method with larger effectivity and accessibility. The tactic’s potential extends past pc imaginative and prescient, paving the best way for its utility in numerous domains and exploration of hybrid approaches for enhanced efficiency.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 40k+ ML SubReddit
For Content material Partnership, Please Fill Out This Type Right here..
![]()
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the newest developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.
[ad_2]
Source link


