
[ad_1]
Pure language processing (NLP) has quickly developed with the event of huge language fashions (LLMs), that are more and more central to numerous tech purposes. These fashions course of and generate textual content in ways in which mimic human understanding, however inefficiencies typically hamper their potential in useful resource use and limitations imposed by proprietary knowledge.
The overarching drawback in LLMs is their useful resource depth and restricted entry attributable to reliance on personal datasets. This will increase the computational price and limits the scope for tutorial analysis and growth in open communities. In response to those challenges, many present options undertake a uniform architectural method, the place every layer of the transformer mannequin is configured identically. Whereas this simplicity aids in mannequin design, it doesn’t optimize the usage of parameters, doubtlessly resulting in wasteful computation and suboptimal efficiency.
OpenELM is a groundbreaking language mannequin launched by Apple researchers. This mannequin revolutionizes the usual design by implementing a layer-wise scaling technique, which allocates parameters extra judiciously throughout the transformer layers. This method permits for the adjustment of layer dimensions all through the mannequin, optimizing efficiency and computational effectivity.
OpenELM is distinct not only for its architectural improvements but additionally for its dedication to open-source growth. The mannequin is pre-trained on numerous public datasets, together with RefinedWeb and PILE, totaling round 1.8 trillion tokens. This mannequin has been proven to enhance accuracy considerably; as an example, with simply 1.1 billion parameters, OpenELM achieves a forty five.93% accuracy price, surpassing the OLMo mannequin’s 43.57% whereas using half the pre-training tokens.
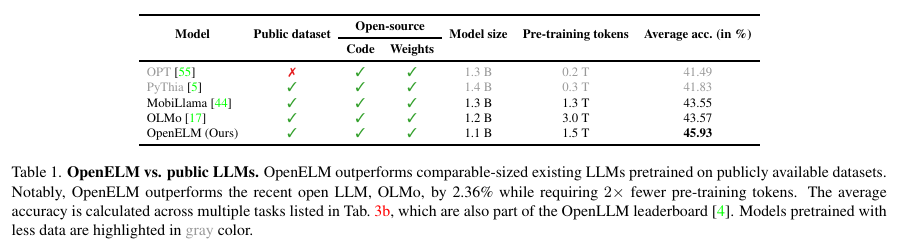
OpenELM’s efficiency excels throughout varied normal metrics and duties. For instance, in zero-shot duties like ARC-e and BoolQ, OpenELM surpasses present fashions with fewer knowledge and fewer computational expense. In direct comparisons, OpenELM demonstrates a 2.36% increased accuracy than OLMo with significantly fewer tokens. This effectivity is achieved by way of strategic parameter allocation, which maximizes the influence of every computational step.
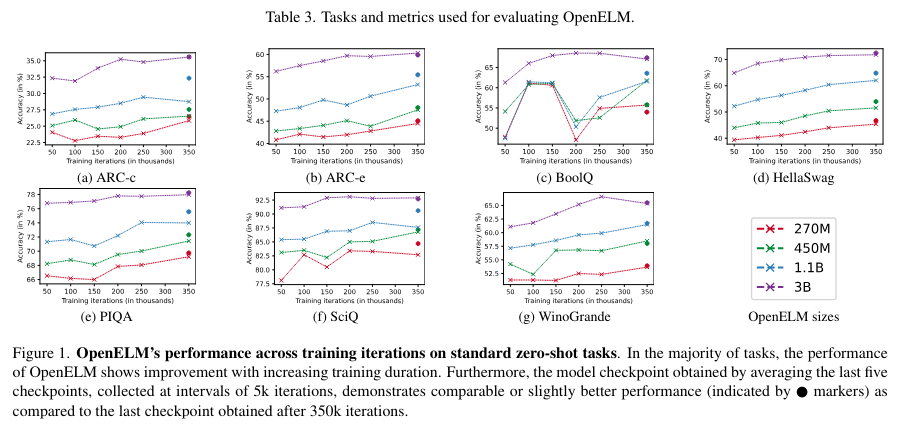
OpenELM marks a step ahead in mannequin effectivity and the democratization of NLP expertise. By publicly releasing the mannequin and its coaching framework, Apple fosters an inclusive surroundings that encourages ongoing analysis and collaboration. This method will probably propel additional NLP improvements, making high-performing language fashions extra accessible and sustainable.

In conclusion, OpenELM addresses the inefficiencies of conventional giant language fashions by way of its progressive layer-wise scaling approach, optimizing parameter distribution successfully. By using publicly obtainable datasets for coaching, OpenELM enhances computational effectivity and fosters open-source collaboration within the pure language processing neighborhood. The mannequin’s spectacular outcomes, together with a 2.36% increased accuracy over comparable fashions like OLMo whereas utilizing half the pre-training tokens, spotlight its potential to set new benchmarks for efficiency and accessibility in language mannequin growth.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 40k+ ML SubReddit
![]()
Whats up, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about expertise and need to create new merchandise that make a distinction.
[ad_2]
Source link


