
[ad_1]
Reinforcement studying (RL) faces challenges on account of pattern inefficiency, hindering real-world adoption. Commonplace RL strategies battle, notably in environments the place exploration is dangerous. Nevertheless, offline RL makes use of pre-collected information to optimize insurance policies with out on-line information assortment. But, a distribution shift between the goal coverage and picked up information presents hurdles, resulting in an out-of-sample subject. This discrepancy leads to overestimation bias, doubtlessly yielding an excessively optimistic goal coverage. This highlights the necessity to deal with distribution shifts for efficient offline RL implementation.
Prior analysis addresses this by explicitly or implicitly regularizing the coverage towards habits distribution. One other strategy includes studying a single-step world mannequin from the offline dataset to generate trajectories for the goal coverage, aiming to mitigate distribution shifts. Nevertheless, this technique might introduce generalization points throughout the world mannequin itself, doubtlessly exacerbating worth overestimation bias in RL insurance policies.
Researchers from Oxford College current policy-guided diffusion (PGD) to deal with the problem of compounding error in offline RL by modeling total trajectories fairly than single-step transitions. PGD trains a diffusion mannequin on the offline dataset to generate artificial trajectories beneath the habits coverage. To align these trajectories with the goal coverage, steerage from the goal coverage is utilized to shift the sampling distribution. This leads to a behavior-regularized goal distribution, lowering divergence from the habits coverage and limiting generalization error.
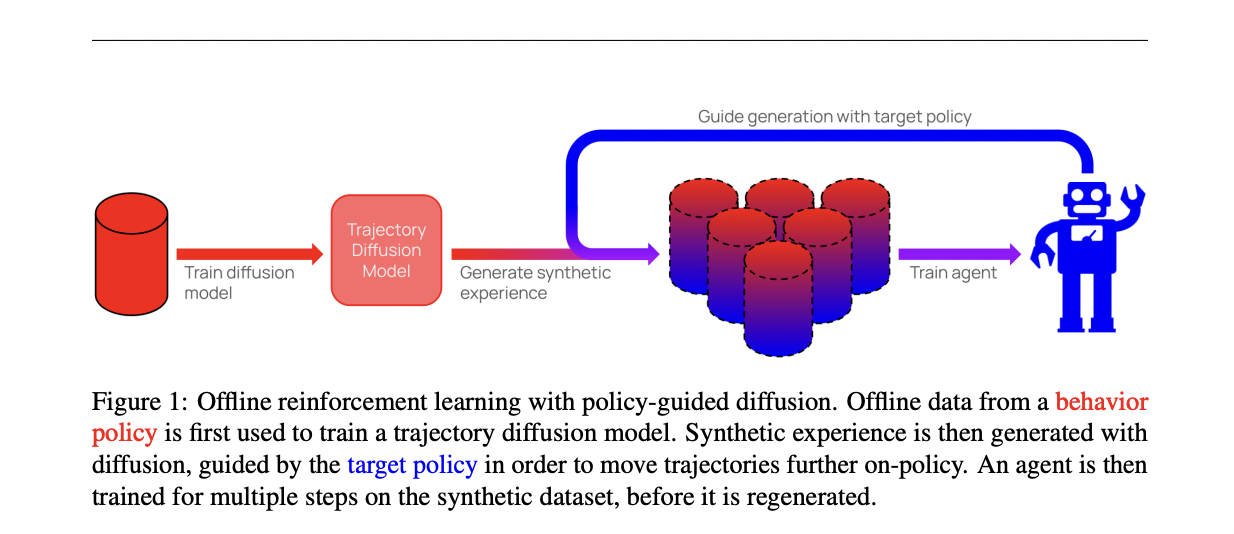
PGD makes use of a trajectory-level diffusion mannequin skilled on an offline dataset to approximate the habits distribution. Impressed by classifier-guided diffusion, PGD incorporates steerage from the goal coverage throughout the denoising course of to steer trajectory sampling towards the goal distribution. This leads to a behavior-regularized goal distribution, balancing motion likelihoods beneath each insurance policies. PGD excludes habits coverage steerage, focusing solely on the right track coverage steerage. To manage steerage energy, PGD introduces steerage coefficients, permitting for fine-tuning of the regularization degree in the direction of the habits distribution. Additionally, PGD applies a cosine steerage schedule and stabilization strategies to boost steerage stability and scale back dynamic error.
The experiments performed exhibit the next key findings:
Effectiveness of PGD: Brokers skilled with artificial expertise from PGD outperform these skilled on unguided artificial information or straight on the offline dataset.
Steering Coefficient Tuning: Tuning the steerage coefficient in PGD allows the sampling of trajectories with excessive motion chance throughout a variety of goal insurance policies. Because the steerage coefficient will increase, trajectory chance beneath every goal coverage will increase monotonically, indicating the power to pattern high-probability trajectories with out-of-distribution (OOD) goal insurance policies.
Low Dynamics Error: Regardless of sampling high-likelihood actions from the coverage, PGD retains low dynamics error. In comparison with an autoregressive world mannequin (PETS), PGD achieves considerably decrease error throughout all goal insurance policies, highlighting its robustness to totally different goal insurance policies.
Coaching Stability: Periodic technology of artificial information outperforms steady technology, attributed to coaching stability, particularly when performing steerage early in coaching. Each approaches constantly outperform coaching on actual and unguided artificial information, demonstrating the potential of PGD as an extension to replay and model-based RL strategies.
To conclude, Oxford researchers launched PGD, providing a controllable technique for artificial trajectory technology in offline RL. By straight modeling trajectories and using coverage steerage, PGD achieves aggressive efficiency in comparison with autoregressive strategies like PETS, with decrease dynamics error. This strategy constantly improves downstream agent efficiency throughout numerous environments and habits insurance policies. PGD addresses out-of-sample points, paving the way in which for much less conservative algorithms in offline RL with the potential for additional enhancements.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 40k+ ML SubReddit
Wish to get in entrance of 1.5 Million AI Viewers? Work with us right here
![]()
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.
[ad_2]
Source link


