
[ad_1]
In our quickly evolving digital world, the demand for fast gratification has by no means been greater. Whether or not we’re trying to find info, merchandise, or providers, we anticipate our queries to be answered with lightning pace and pinpoint accuracy. Nevertheless, the search for pace and precision usually presents a formidable problem for contemporary search engines like google.
Conventional retrieval fashions face a basic trade-off: the extra correct they’re, the upper the computational value and latency. This latency generally is a deal-breaker, negatively impacting consumer satisfaction, income, and vitality effectivity. Researchers have been grappling with this conundrum, searching for methods to ship each effectiveness and effectivity in a single package deal.
In a groundbreaking examine, a workforce of researchers from the College of Glasgow has unveiled an ingenious answer that harnesses the ability of smaller, extra environment friendly transformer fashions to attain lightning-fast retrieval with out sacrificing accuracy. Meet shallow Cross-Encoders: a novel AI strategy that guarantees to revolutionize the search expertise.
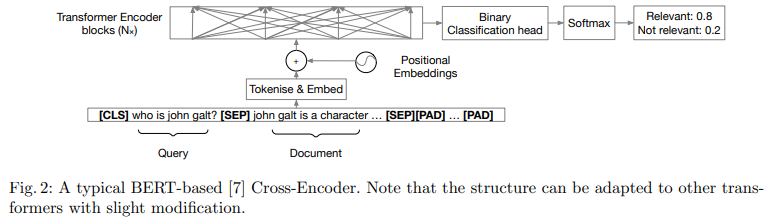
Shallow Cross-Encoders are primarily based on transformer fashions with fewer layers and decreased computational necessities. Not like their bigger counterparts, resembling BERT or T5, these helpful fashions can estimate the relevance of extra paperwork throughout the identical time funds, doubtlessly main to raised total effectiveness in low-latency situations.
However coaching these smaller fashions successfully is not any straightforward feat. Standard strategies usually lead to overconfidence and instability, hampering efficiency. To beat this problem, the researchers launched an ingenious coaching scheme referred to as gBCE (Generalized Binary Cross-Entropy), which mitigates the overconfidence downside and ensures steady, correct outcomes.
The gBCE coaching scheme incorporates two key elements: (1) an elevated variety of detrimental samples per constructive occasion and (2) the gBCE loss operate, which counters the consequences of detrimental sampling. By fastidiously balancing these components, the researchers have been capable of prepare extremely efficient shallow Cross-Encoders that persistently outperformed their bigger counterparts in low-latency situations.
In a sequence of rigorous experiments, the researchers evaluated a spread of shallow Cross-Encoder fashions, together with TinyBERT (2 layers), MiniBERT (4 layers), and SmallBERT (4 layers), towards full-size baselines like MonoBERT-Giant and MonoT5-Base. The result was exceedingly spectacular.
On the TREC DL 2019 dataset, the diminutive TinyBERT-gBCE mannequin achieved an NDCG@10 rating of 0.652 when the latency was restricted to a mere 25 milliseconds – a staggering 51% enchancment over the a lot bigger MonoBERT-Giant mannequin (NDCG@10 of 0.431) underneath the identical latency constraint.
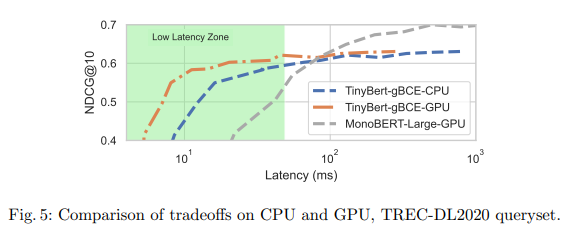
Nevertheless, the benefits of shallow cross-encoders prolong past sheer pace and accuracy. These compact fashions additionally provide important advantages by way of vitality effectivity and cost-effectiveness. With their modest reminiscence footprints, they are often deployed on a variety of units, from highly effective information facilities to resource-constrained edge units, with out the necessity for specialised {hardware} acceleration.
Think about a world the place your search queries are answered with lightning pace and pinpoint accuracy, whether or not you’re utilizing a high-end workstation or a modest cell gadget. That is the promise of shallow Cross-Encoders, a game-changing answer that would redefine the search expertise for billions of customers worldwide.
Because the analysis workforce proceed to refine and optimize this groundbreaking know-how, we will stay up for a future the place the trade-off between pace and accuracy turns into a factor of the previous. With shallow Cross-Encoders on the forefront, the pursuit of instantaneous, correct search outcomes is not a distant dream – it’s a tangible actuality inside our grasp.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 39k+ ML SubReddit
![]()
Vibhanshu Patidar is a consulting intern at MarktechPost. At the moment pursuing B.S. at Indian Institute of Expertise (IIT) Kanpur. He’s a Robotics and Machine Studying fanatic with a knack for unraveling the complexities of algorithms that bridge principle and sensible purposes.
[ad_2]
Source link


