
[ad_1]
The analysis is rooted within the discipline of visible language fashions (VLMs), significantly specializing in their software in graphical person interfaces (GUIs). This space has change into more and more related as folks spend extra time on digital gadgets, necessitating superior instruments for environment friendly GUI interplay. The research addresses the intersection of LLMs and their integration with GUIs, which provides huge potential for enhancing digital job automation.
The core problem recognized is the necessity for extra effectiveness of huge language fashions like ChatGPT in understanding and interacting with GUI parts. This limitation is a big bottleneck, contemplating most functions contain GUIs for human interplay. The present fashions’ reliance on textual inputs must be extra correct in capturing the visible elements of GUIs, that are crucial for seamless and intuitive human-computer interplay.
Current strategies primarily leverage text-based inputs, similar to HTML content material or OCR (Optical Character Recognition) outcomes, to interpret GUIs. Nonetheless, these approaches must be revised to comprehensively perceive GUI parts, that are visually wealthy and sometimes require a nuanced interpretation past textual evaluation. Conventional fashions need assistance understanding icons, photos, diagrams, and spatial relationships inherent in GUI interfaces.
In response to those challenges, the researchers from Tsinghua College, Zhipu AI, launched CogAgent, an 18-billion-parameter visible language mannequin particularly designed for GUI understanding and navigation. CogAgent differentiates itself by using each low-resolution and high-resolution picture encoders. This dual-encoder system permits the mannequin to course of and perceive intricate GUI parts and textual content material inside these interfaces, a crucial requirement for efficient GUI interplay.
CogAgent’s structure incorporates a distinctive high-resolution cross-module, which is vital to its efficiency. This module allows the mannequin to effectively deal with high-resolution inputs (1120 x 1120 pixels), which is essential for recognizing small GUI parts and textual content. This strategy addresses the frequent problem of managing high-resolution photos in VLMs, which usually lead to prohibitive computational calls for. The mannequin thus strikes a steadiness between high-resolution processing and computational effectivity, paving the best way for extra superior GUI interpretation.
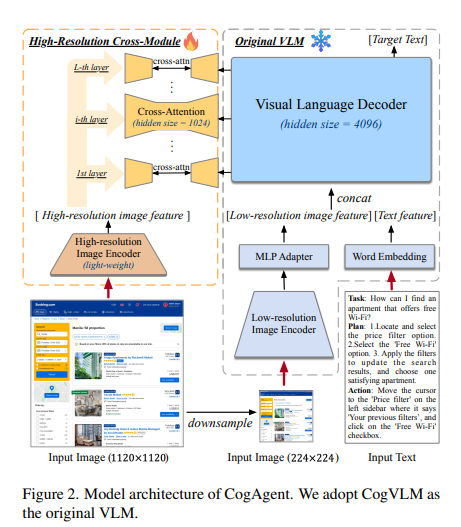
CogAgent units a brand new customary within the discipline by outperforming present LLM-based strategies in numerous duties, significantly in GUI navigation for each PC and Android platforms. The mannequin performs superior on a number of text-rich and common visible question-answering benchmarks, indicating its robustness and flexibility. Its means to surpass conventional fashions in these duties highlights its potential in automating complicated duties that contain GUI manipulation and interpretation.
The analysis could be summarised in a nutshell as follows:
CogAgent represents a big leap ahead in VLMs, particularly in contexts involving GUIs.
Its progressive strategy to processing high-resolution photos inside a manageable computational framework units it aside from present strategies.
The mannequin’s spectacular efficiency throughout numerous benchmarks underscores its applicability and effectiveness in automating and simplifying GUI-related duties.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to affix our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E mail E-newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Should you like our work, you’ll love our publication..
![]()
Hey, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m obsessed with know-how and wish to create new merchandise that make a distinction.
[ad_2]
Source link


