
[ad_1]
Coaching massive language fashions (LLMs) has posed a big problem resulting from their memory-intensive nature. The standard method of decreasing reminiscence consumption by compressing mannequin weights usually results in efficiency degradation. Nevertheless, a novel methodology, Gradient Low-Rank Projection (GaLore), by researchers from the California Institute of Expertise, Meta AI, College of Texas at Austin, and Carnegie Mellon College, presents a recent perspective. GaLore focuses on the gradients quite than the mannequin weights, a novel method that guarantees to reinforce reminiscence effectivity with out compromising mannequin efficiency.
This method diverges from the standard strategies by specializing in the gradients quite than the mannequin weights. By projecting gradients right into a lower-dimensional area, GaLore permits for totally exploring the parameter area, successfully balancing reminiscence effectivity with the mannequin’s efficiency. This system has proven promise in sustaining or surpassing the efficiency of full-rank coaching strategies, significantly throughout the pre-training and fine-tuning phases of LLM improvement.
GaLore’s core innovation lies in its distinctive dealing with of the gradient projection, decreasing reminiscence utilization in optimizer states by as much as 65.5% with out sacrificing coaching effectivity. That is achieved by incorporating a compact illustration of gradients, which maintains the integrity of the coaching dynamics and allows substantial reductions in reminiscence consumption. Consequently, GaLore facilitates the coaching of fashions with billions of parameters on customary consumer-grade GPUs, which was beforehand solely possible with complicated mannequin parallelism or in depth computational assets.
The efficacy of GaLore extends to its adaptability with numerous optimization algorithms, making it an integral addition to present coaching pipelines. Its utility in pre-training and fine-tuning eventualities throughout completely different benchmarks has demonstrated GaLore’s functionality to ship aggressive outcomes with considerably decrease reminiscence necessities. As an illustration, GaLore has enabled the pre-training of fashions with as much as 7 billion parameters on shopper GPUs, a milestone in LLM coaching that underscores the strategy’s potential to rework the panorama of mannequin improvement.
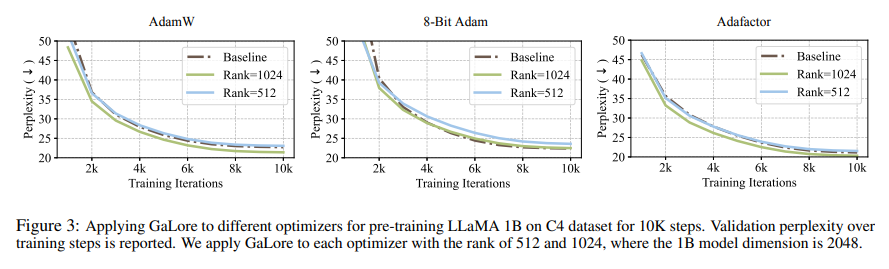
Complete evaluations of GaLore have highlighted its superior efficiency to different low-rank adaptation strategies. GaLore conserves reminiscence and achieves comparable or higher outcomes when utilized to large-scale language fashions, underscoring its effectiveness as a coaching technique. This efficiency is especially evident in pre-training and fine-tuning on established NLP benchmarks, the place GaLore’s memory-efficient method doesn’t compromise the standard of outcomes.
GaLore presents a big breakthrough in LLM coaching, providing a robust answer to the longstanding problem of memory-intensive mannequin improvement. By means of its modern gradient projection method, GaLore demonstrates distinctive reminiscence effectivity whereas preserving and, in some instances, enhancing mannequin efficiency. Its compatibility with numerous optimization algorithms additional solidifies its place as a flexible and impactful software for researchers and practitioners. The appearance of GaLore marks a pivotal second within the democratization of LLM coaching, doubtlessly accelerating developments in pure language processing and associated domains.
In conclusion, key takeaways from the analysis embody:
GaLore considerably reduces reminiscence utilization in coaching massive language fashions with out compromising efficiency.
It makes use of a novel gradient projection methodology to discover the parameter area totally, thus enhancing coaching effectivity.
GaLore is adaptable with numerous optimization algorithms, seamlessly integrating into present mannequin coaching workflows.
Complete evaluations have confirmed GaLore’s functionality to ship aggressive outcomes throughout pre-training and fine-tuning benchmarks, demonstrating its potential to revolutionize the coaching of LLMs.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our Telegram Channel
You might also like our FREE AI Programs….
![]()
Hiya, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m obsessed with expertise and need to create new merchandise that make a distinction.
[ad_2]
Source link


