
[ad_1]
Massive language fashions (LLMs) have taken a forefront place, significantly within the advanced area of problem-solving and reasoning duties. Improvement on this enviornment is the Chain of Thought (CoT) prompting approach, which mirrors the sequential reasoning of people and reveals exceptional effectiveness in varied difficult eventualities. Nevertheless, regardless of its promising purposes, an in depth understanding of CoT’s mechanics should nonetheless be found. This data hole has led to reliance on experimental approaches for enhancing CoT’s efficacy with out a structured framework to information these enhancements.
The current research delves into the intricacies of CoT prompting, particularly investigating the connection between the size of reasoning steps in prompts and the effectiveness of LLMs in problem-solving. This exploration is especially important within the context of superior prompting methods. The CoT approach has emerged as a key innovation identified for its efficacy in multi-step problem-solving. CoT has efficiently tackled challenges throughout varied domains, together with cross-domain, length-generalization, and cross-lingual duties.
The analysis crew from Northwestern College, College of Liverpool, New Jersey Institute of Expertise, and Rutgers College launched into managed experiments to look at the influence of various the size of reasoning steps inside CoT demonstrations. This concerned increasing and compressing the rationale reasoning steps whereas retaining all different elements fixed. The crew meticulously ensured that no further information was launched when incorporating new reasoning steps. Within the zero-shot experiments, they modified the preliminary immediate from “Let’s assume step-by-step” to “Let’s assume step-by-step, you will need to assume extra steps.” For the few-shot setting, experiments had been designed to increase the rationale reasoning steps inside CoT demonstrations, sustaining consistency in different facets.
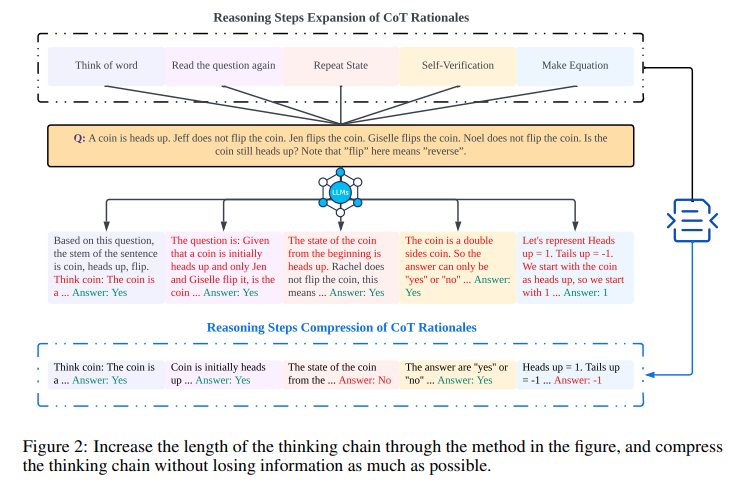
They revealed that lengthening reasoning steps in prompts, with out including new info, considerably enhances LLMs’ reasoning talents throughout a number of datasets. Shortening the reasoning steps whereas preserving key info noticeably diminishes the reasoning talents of fashions. This discovery underscores the significance of the variety of steps in CoT prompts and provides sensible steering for leveraging LLMs’ potential in advanced problem-solving eventualities.
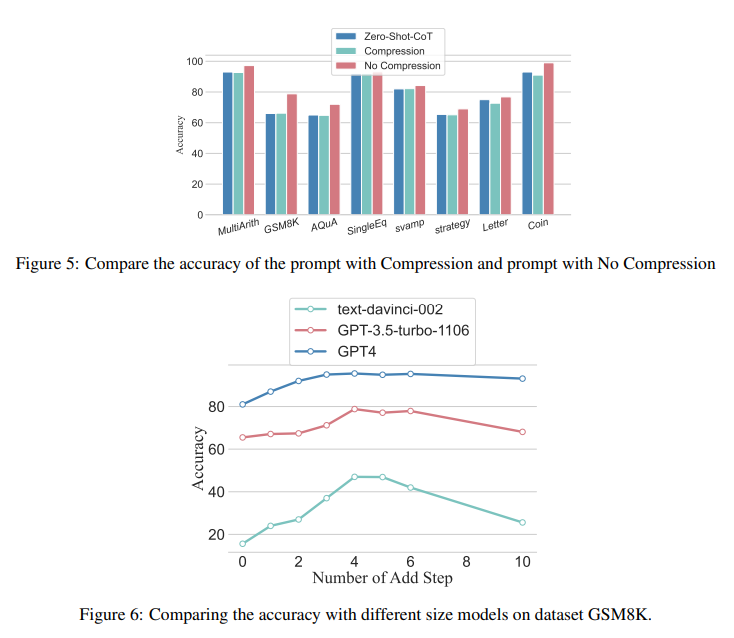
The outcomes confirmed that even incorrect rationales may yield favorable outcomes in the event that they maintained the required size of inference. The research additionally noticed that the advantages of accelerating reasoning steps are task-dependent: less complicated duties require fewer steps, whereas extra advanced duties acquire considerably from longer inference sequences. It was additionally discovered that elevated reasoning steps in zero-shot CoT can considerably enhance LLM accuracy.
The research’s key findings could be summarized as follows:
There’s a direct linear correlation between step depend and accuracy for few-shot CoT, indicating a quantifiable methodology to optimize CoT prompting in advanced reasoning duties.
Lengthening reasoning steps in prompts significantly enhances LLMs’ reasoning talents, whereas shortening them diminishes these talents, even when key info is retained.
Incorrect rationales can nonetheless result in favorable outcomes, offered they preserve the required size of inference, suggesting that the scale of the reasoning chain is extra essential than its factual accuracy for efficient problem-solving.
The effectiveness of accelerating reasoning steps is contingent on the duty’s complexity, with less complicated duties requiring fewer steps and sophisticated duties benefiting extra from prolonged inference sequences.
Enhancing reasoning steps in zero-shot CoT settings results in a notable enchancment in LLM accuracy, significantly in datasets involving mathematical issues.
This analysis supplies a nuanced understanding of how the size of reasoning steps in CoT prompts influences the reasoning capabilities of enormous language fashions. These insights provide invaluable tips for refining CoT methods in varied advanced NLP duties, emphasizing the importance of reasoning size over factual accuracy within the reasoning chain.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
![]()
Good day, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with know-how and need to create new merchandise that make a distinction.
[ad_2]
Source link


