
[ad_1]
Massive language fashions (LLMs) have profoundly remodeled the panorama of synthetic intelligence (AI) in pure language processing (NLP). These fashions can perceive and generate human-like textual content, representing a pinnacle of present AI analysis. But, the computational depth required for his or her operation, significantly throughout inference, presents a formidable problem. This situation is exacerbated as fashions develop in dimension to reinforce efficiency, leading to elevated latency and useful resource calls for.
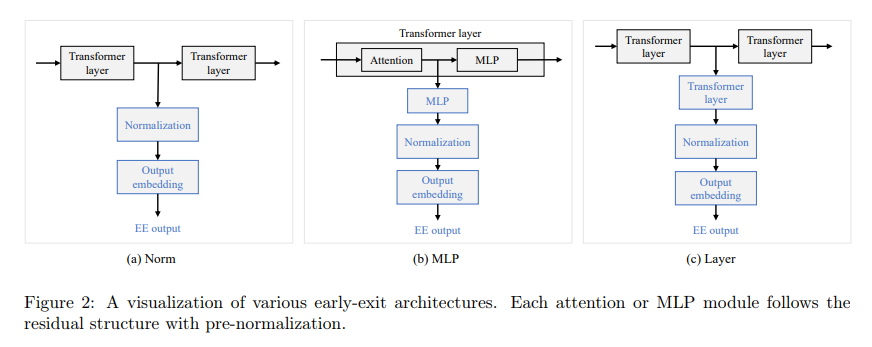
EE-Tuning, the answer proposed by the crew from Alibaba Group, reimagines the strategy to tuning LLMs for enhanced efficiency. Conventional strategies usually contain in depth pre-training throughout all mannequin parameters, which calls for substantial computational sources and information. EE-Tuning departs from this norm by specializing in augmenting pre-trained LLMs with strategically positioned early exit layers. These layers enable the mannequin to provide outputs at intermediate levels, decreasing the necessity for full computation and accelerating inference. The genius of EE-tuning lies in its capacity to fine-tune these extra layers in a computationally economical and parameter-efficient manner, making certain that the improved fashions stay scalable and manageable at the same time as they develop in complexity and dimension.
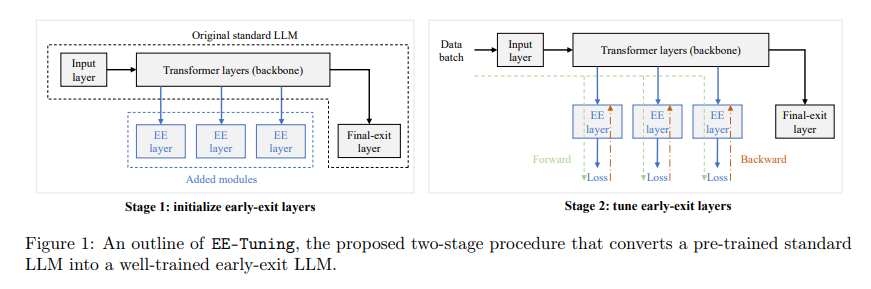
The method entails integrating early-exit layers right into a pre-existing LLM, tuned via a two-stage process. The primary stage consists of initializing these layers, making certain they’re correctly set as much as contribute to the mannequin’s general efficiency with out requiring a whole overhaul. The second stage focuses on fine-tuning and optimizing the layers in opposition to chosen coaching losses whereas retaining the core parameters of the unique mannequin unchanged. This strategy minimizes the computational load and permits for important flexibility and customization, accommodating a variety of configurations and optimizations that cater to completely different operational scales and necessities.
The influence of EE-Tuning has been rigorously examined via a sequence of experiments, demonstrating its efficacy throughout numerous mannequin sizes, together with these with as much as 70 billion parameters. EE-Tuning allows these massive fashions to quickly purchase early-exit capabilities, using a fraction of the GPU hours and coaching information usually required for pre-training. This effectivity doesn’t come at the price of efficiency; the transformed fashions exhibit important speedups on downstream duties whereas sustaining, and in some instances even enhancing, the standard of their output. Such outcomes underscore the potential of EE-Tuning to revolutionize the sector, making superior LLMs extra accessible and manageable for the broader AI group.
In abstract, the analysis on EE-Tuning presents a number of key insights:
It introduces a scalable and environment friendly methodology for enhancing LLMs with early-exit capabilities, considerably decreasing inference latency with out compromising output high quality.
The 2-stage tuning course of is computationally economical and extremely efficient, enabling fast mannequin adaptation with minimal useful resource necessities.
Intensive experiments validate the strategy, showcasing its applicability throughout numerous mannequin sizes and configurations.
By making superior LLM applied sciences extra accessible, EE-Tuning paves the best way for additional improvements in AI and NLP, promising to increase their purposes and influence.
This groundbreaking work by the Alibaba Group analysis crew addresses a important problem within the deployment of LLMs and opens up new avenues for exploration and improvement in AI. By means of EE-tuning, the potential for creating extra environment friendly, highly effective, and accessible language fashions turns into a tangible actuality, marking a major step ahead within the quest to harness synthetic intelligence’s full capabilities.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
![]()
Hiya, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m enthusiastic about know-how and need to create new merchandise that make a distinction.
[ad_2]
Source link


