
[ad_1]
Giant language fashions (LLMs) excel in varied problem-solving duties however need assistance with complicated mathematical reasoning, presumably because of the want for multi-step reasoning. Instruction Tuning successfully enhances LLM capabilities. Nevertheless, its effectiveness is hindered by the shortage of datasets for mathematical reasoning. This limitation highlights the necessity for extra intensive datasets to totally leverage Instruction Tuning to enhance LLM efficiency in mathematical problem-solving.
Instruction Tuning is efficient however restricted by small datasets like GSM8K and MATH. ChatGPT-based Instruction Tuning, exemplified by WizardMath and MetaMath, enhances math instruction by using ChatGPT for information synthesis. These strategies make use of bolstered Evol-instruct and bootstrapping methods to evolve questions and increase datasets. Nevertheless, their effectiveness is constrained by manually designed operations.
Researchers from The Chinese language College of Hong Kong, Microsoft Analysis, and Shenzhen Analysis Institute of Huge Knowledge introduce a novel strategy, MathScale, to handle mathematical reasoning datasets’ scalability and high quality points. This progressive technique extracts high-level ideas from present math questions, constructs an idea graph to estimate connections between them, and generates new questions based mostly on randomly sampled ideas. MathScale additionally introduces MWPBENCH, a singular, complete benchmark protecting varied issue ranges, to guage mathematical reasoning capabilities constantly and pretty. The effectiveness of MathScale in scaling dataset measurement and considerably enhancing LLM capabilities is demonstrated by the MathScaleQA dataset and its efficiency on MWPBENCH.
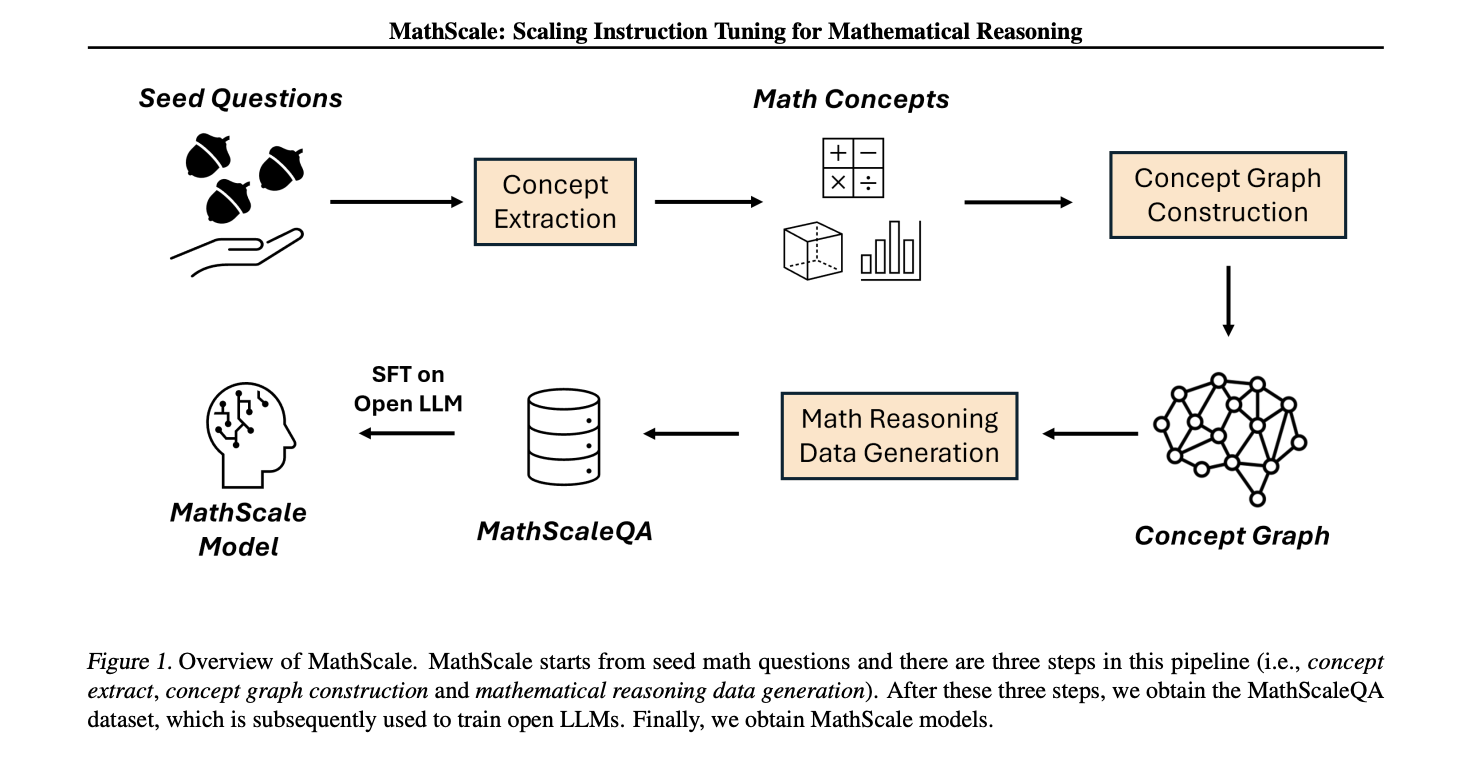
MathScale’s dataset technology course of is a scientific four-step strategy. Firstly, it leverages GPT-3.5 to extract high-level ideas from present math questions, eliminating the necessity for reliance on unique questions. Secondly, it constructs an idea graph based mostly on these extractions, visually representing the connections between totally different ideas. Thirdly, it employs a random stroll algorithm to pattern subjects and information factors from the graph, guaranteeing a various and complete dataset. Lastly, it generates new math questions based mostly on these sampled ideas, strictly adhering to the supplied subjects and information factors.
MathScale units itself other than different fashions, together with LLaMA-2 7B, LLaMA-2 13B, and Mistral 7B, on the MWPBENCH dataset. It not solely achieves a micro common accuracy of 35.0% and a macro common accuracy of 37.5% but additionally surpasses counterparts of equal measurement by 42.9% and 43.7%, respectively. Even on out-of-domain check units like GaokaoBench-Math and AGIEval-SAT-MATH, MathScale-7B considerably outperforms different open-source fashions. MathScale-Mistral demonstrates efficiency parity with GPT-3.5-Turbo on each micro and macro averages, additional underscoring its superiority.
In conclusion, researchers from The Chinese language College of Hong Kong, Microsoft Analysis, and Shenzhen Analysis Institute of Huge Knowledge current MathScale, which introduces an easy and scalable strategy for producing top-notch mathematical reasoning information utilizing cutting-edge LLMs. Additionally, MWPBENCH gives a complete benchmark for math phrase issues throughout varied issue ranges. MathScale-7B reveals state-of-the-art efficiency on MWPBENCH, outperforming equivalent-sized friends by important margins. This contribution advances mathematical reasoning by facilitating truthful and constant mannequin evaluations in tutorial settings.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a concentrate on Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link


