
[ad_1]
Diffusion fashions have turn into the prevailing strategy for producing movies. But, their dependence on large-scale net information, which varies in high quality, regularly results in outcomes missing visible attraction and never aligning effectively with the offered textual prompts. Regardless of developments in latest instances, there’s nonetheless room for enhancing the visible high quality of generated movies. One notable issue contributing to this problem is the varied high quality of the intensive net information utilized in pre-training. This variability may end up in fashions able to producing content material that lacks visible attraction, could also be poisonous, and doesn’t align effectively with the offered prompts.
A crew of researchers from Zhejiang College, Alibaba Group, Tsinghua College, Singapore College of Expertise and Design, S-Lab, Nanyang Technological College, CAML Lab, and the College of Cambridge launched InstructVideo to instruct text-to-video diffusion fashions with human suggestions by reward fine-tuning. Complete experiments, encompassing qualitative and quantitative assessments, verify the practicality and effectiveness of incorporating picture reward fashions in InstructVideo. This strategy considerably improves the visible high quality of generated movies with out compromising the mannequin’s capability to generalize.
Early efforts at video era targeted on GANs and VAEs, however producing movies from texts remained a problem. Diffusion fashions have emerged because the de facto technique for video era, offering range and constancy. VDM prolonged picture diffusion fashions to video era. Efforts had been made to introduce spatiotemporal situations for a extra controllable era. Understanding human choice in visible content material era is difficult, and a few works use annotation and fine-tuning annotated information to mannequin human preferences. Studying from human suggestions in optical content material era is fascinating, and former works targeted on reinforcement studying and agent alignment.
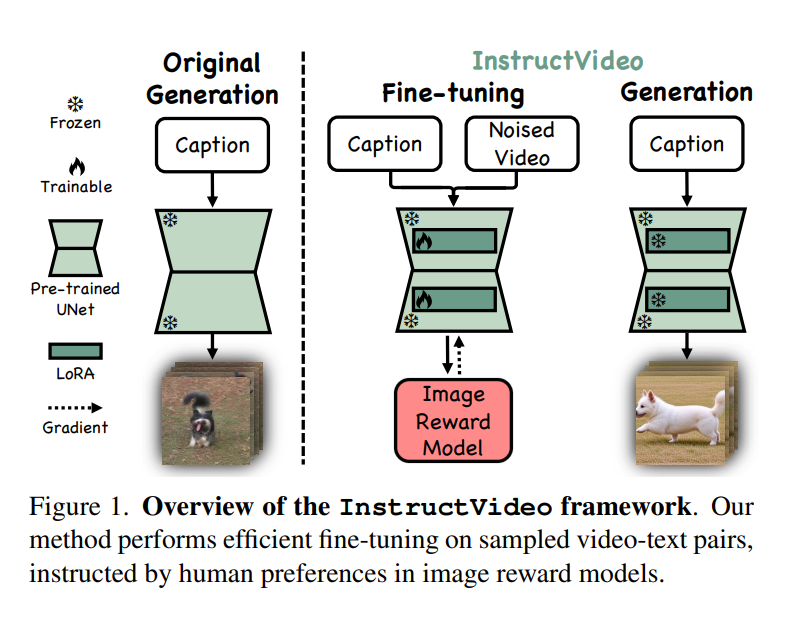
InstructVideo makes use of a reformulation of reward fine-tuning as enhancing, bettering computational effectivity and efficacy. The tactic incorporates Segmental Video Reward (SegVR) and Temporally Attenuated Reward (TAR) to allow environment friendly reward fine-tuning utilizing picture reward fashions. SegVR supplies reward indicators based mostly on segmental sparse sampling, whereas TAR mitigates temporal modeling degradation throughout fine-tuning. The optimization goal is rewritten to incorporate the diploma of the attenuating fee, with a default worth of 1 for the coefficient. InstructVideo leverages the diffusion course of to acquire the place to begin for reward fine-tuning in video era.

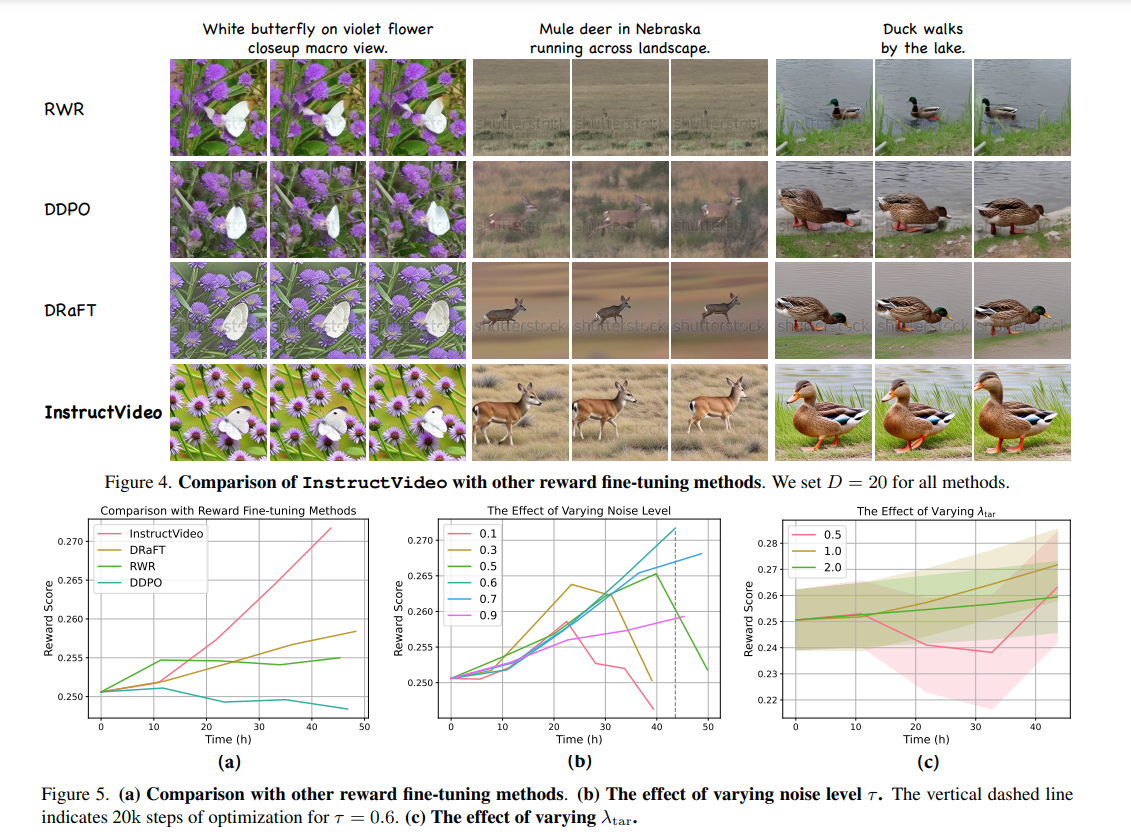
The analysis supplies extra visualization outcomes to exemplify the conclusions drawn, showcasing how the generated movies evolve. The efficacy of InstructVideo is demonstrated via an ablation research on SegVR and TAR, displaying that their removing results in a noticeable discount in temporal modeling capabilities. InstructVideo constantly outperforms different strategies by way of video high quality, with enhancements in video high quality being extra pronounced than enhancements in video-text alignment.
In conclusion, the InstructVideo technique considerably enhances the visible high quality of generated movies with out compromising generalization capabilities, as validated via intensive qualitative and quantitative experiments.InstructVideo outperforms different strategies relating to video high quality, with enhancements in video high quality being extra pronounced than enhancements in video-text alignment. Utilizing picture reward fashions, equivalent to HPSv2, in InstructVideo proves sensible and efficient in enhancing the visible high quality of generated movies. Incorporating SegVR and TAR in InstructVideo improves fine-tuning and mitigates temporal modeling degradation.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to hitch our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E mail Publication, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
In case you like our work, you’ll love our publication..
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]
Source link


