
[ad_1]
A sparse Combination of Specialists (SMoEs) has gained traction for scaling fashions, particularly helpful in memory-constrained setups. They’re pivotal in Swap Transformer and Common Transformers, providing environment friendly coaching and inference. Nevertheless, implementing SMoEs effectively poses challenges. Naive PyTorch implementations lack GPU parallelism, hindering efficiency. Additionally, preliminary deployments of TPUs need assistance with tensor dimension variability, resulting in reminiscence allocation points as a consequence of imbalanced skilled utilization.
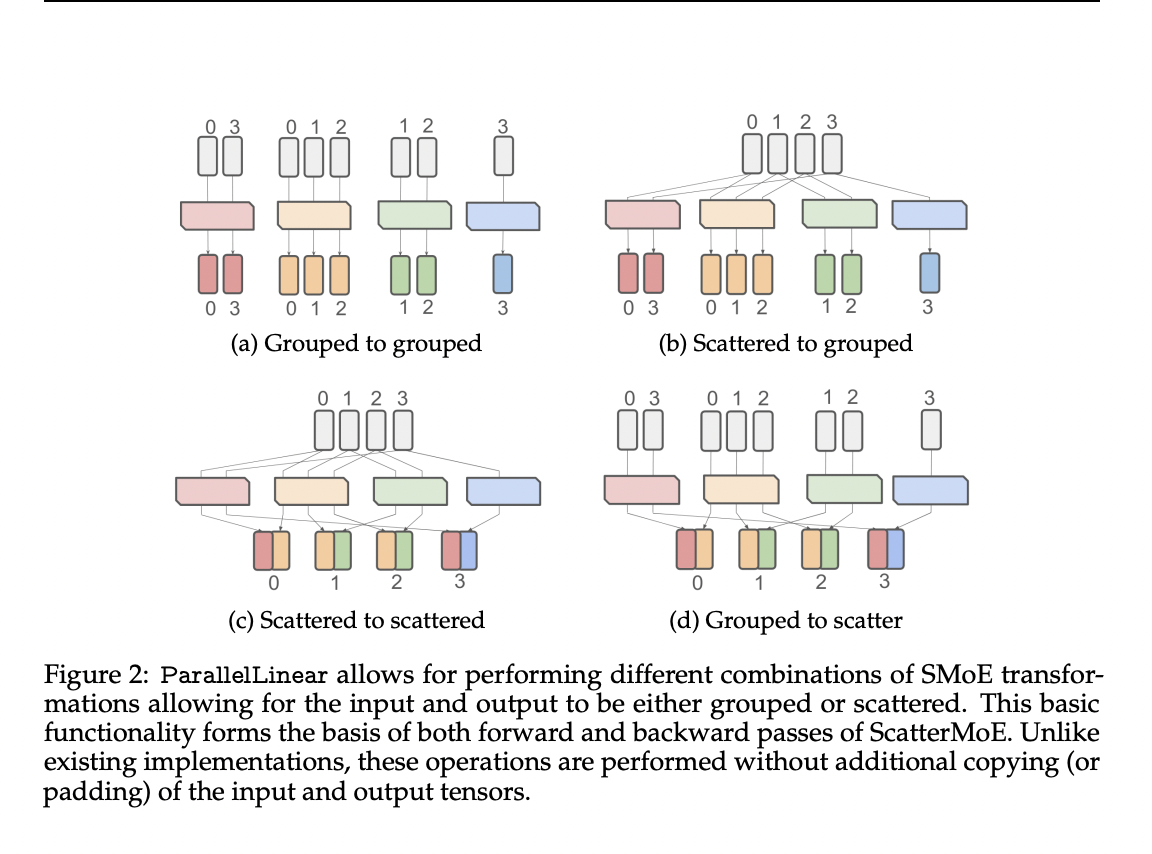
Megablocks and PIT suggest framing SMoE computation as a sparse matrix multiplication drawback to handle these challenges. This permits for extra environment friendly GPU-based implementations. Nevertheless, present approaches nonetheless have drawbacks. They require a scatter-to-group preliminary copy of the enter, resulting in reminiscence overhead throughout coaching. Some implementations additional exacerbate this problem by padding the grouped copy, growing reminiscence utilization. Furthermore, translating the SMoE drawback right into a sparse matrix format introduces computation overhead and opacity, making extension past SMoE MLPs tough.
Researchers from IBM, Mila, and the College of Montreal current ScatterMoE, an environment friendly SMoE implementation that minimizes reminiscence footprint through ParallelLinear, which conducts grouped matrix operations on scattered teams. This method allows intermediate representations to be uncovered as normal PyTorch tensors, facilitating simple extension to different skilled modules. Demonstrated with SMoE Consideration, ScatterMoE is benchmarked towards Megablocks, which is essential for its utilization in Megatron-LM. Megablocks is applied utilizing the STK framework, making it accessible for modification and extension.
ScatterMoE employs ParallelLinear for environment friendly SMoE computation. It streamlines reminiscence utilization by avoiding further copying and padding throughout operations. ParallelLinear facilitates numerous transformations, enhancing extensibility to different skilled modules. For the backward move, ParallelLinear effectively computes gradients for every skilled. ScatterMoE additionally allows seamless implementation of Combination-of-Consideration (MoA) with out further reminiscence prices, supporting functions like SMoE Consideration. The proposed methodology is benchmarked towards Megablocks for validation.
In Mixtral, ScatterMoE outperforms Megablocks Sparse and Reminiscence-efficient implementations by a staggering 38.1% general throughput. Unit benchmarking on SMoE MLP reveals ScatterMoE’s larger throughput throughout coaching and decrease reminiscence consumption. As granularity will increase, ScatterMoE demonstrates higher scalability in comparison with Megablocks, making it the clear alternative for high-granularity settings. Reducing sparsity additionally showcases ScatterMoE’s effectivity, outperforming Megablocks in throughput whereas remaining extra environment friendly than dense MLP fashions. Additionally, in Combination of Consideration implementation, ScatterMoE persistently outperforms Megablocks, significantly in excessive granularity settings.
In conclusion, the researchers have launched ScatterMoE, which boosts SMoE implementations on GPUs by mitigating reminiscence footprint points and boosting inference and coaching velocity. Leveraging ParallelLinear, it outperforms Megablocks, demonstrating superior throughput and diminished reminiscence utilization. ScatterMoE’s design facilitates the extension of Combination-of-Specialists ideas, exemplified by its implementation of Combination of Consideration. This method considerably advances environment friendly deep studying mannequin coaching and inference.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 38k+ ML SubReddit
![]()
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]
Source link

