
[ad_1]
With the widespread adoption of Massive Language Fashions (LLMs), the search for environment friendly methods to run these fashions on client {hardware} has gained prominence. One promising technique includes utilizing sparse mixture-of-experts (MoE) architectures, the place solely chosen mannequin layers are lively for a given enter. This attribute permits MoE-based language fashions to generate tokens quicker than their denser counterparts. Nevertheless, the downside is an elevated mannequin measurement as a result of presence of a number of “specialists,” making the newest MoE language fashions difficult to execute with out high-end GPUs.
To handle this problem, the authors of this paper delve into the issue of working massive MoE language fashions on client {hardware}. They construct upon parameter offloading algorithms and introduce a novel technique that capitalizes on the inherent properties of MoE LLMs.
The paper explores two major avenues for working these fashions on extra reasonably priced {hardware} setups: compressing mannequin parameters or offloading them to a inexpensive storage medium, equivalent to RAM or SSD. It’s necessary to notice that the proposed optimization primarily targets inference fairly than coaching.
Earlier than delving into the precise methods, let’s grasp the ideas of parameter offloading and the combination of specialists. Parameter offloading includes transferring mannequin parameters to a less expensive reminiscence, equivalent to system RAM or SSD, and loading them simply in time when wanted for computation. This strategy is especially efficient for deep studying fashions that comply with a hard and fast layer order, enabling pre-dispatch of the following layer’s parameters within the background.
The MoE mannequin builds on an older idea of coaching ensembles of specialised fashions (“specialists”) with a gating perform to pick the suitable skilled for a given activity. The examine makes use of standard open-access MoE fashions, Mixtral-8x7B on account of their skill to suit non-experts right into a fraction of accessible GPU reminiscence.
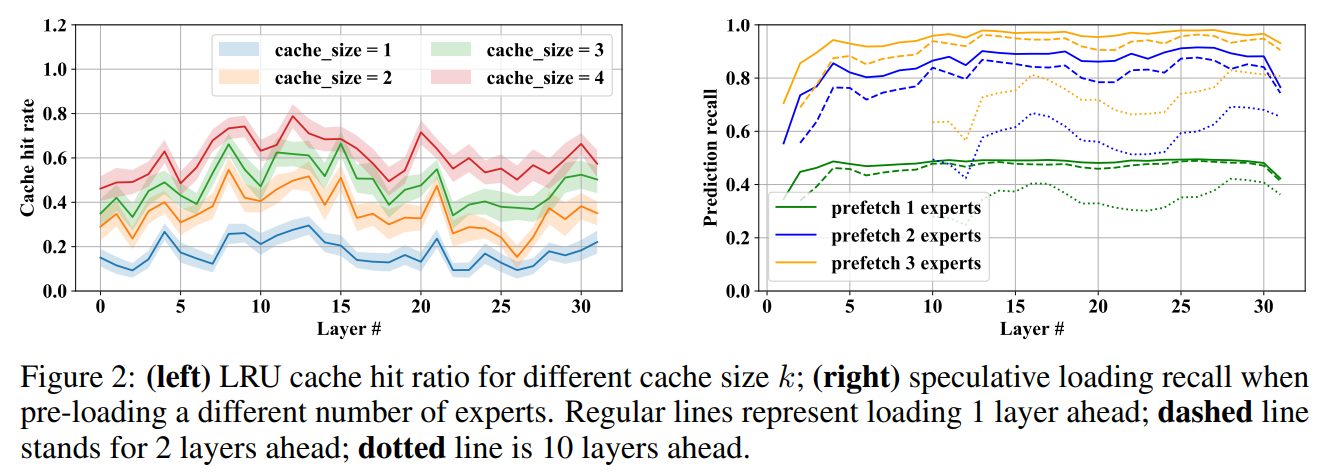
The generative inference workload includes two phases: encoding the enter immediate and producing tokens conditioned on that immediate. Notably, MoE fashions exhibit a sample (proven in Determine 1) the place particular person specialists are assigned to distinct sub-tasks. To leverage this sample, the authors introduce the idea of Knowledgeable Locality and LRU Caching. By conserving lively specialists in GPU reminiscence as a “cache” for future tokens, they observe a major speedup in inference for contemporary MoE fashions.
The paper introduces Speculative Knowledgeable Loading to deal with the problem of skilled loading time. In contrast to dense fashions, MoE offloading can’t successfully overlap skilled loading with computation. The authors suggest guessing the possible subsequent specialists based mostly on the gating perform of the earlier layer’s hidden states to beat this limitation. This speculative loading strategy proves efficient in dashing up the following layer’s inference.
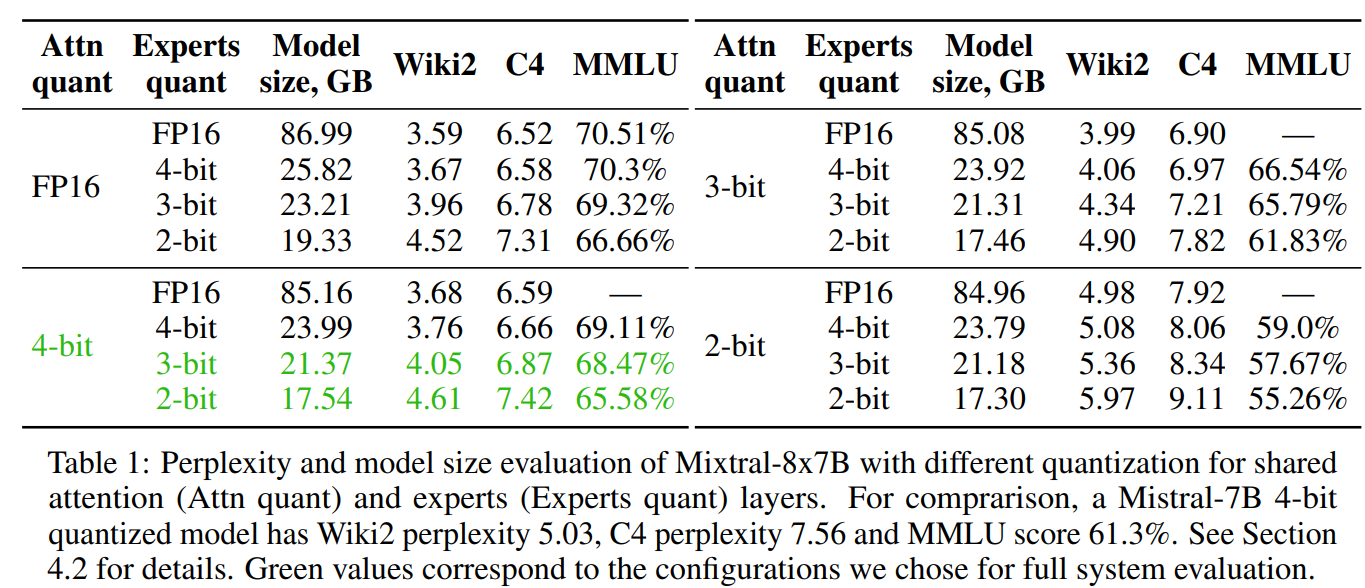
Moreover, the authors discover MoE Quantization, observing that compressed fashions take much less time to load onto the GPU. They use Half Quadratic Quantization (HQQ) for its data-free quantization capabilities, reaching higher quality-size trade-offs when quantizing specialists to a decrease bitwidth.
The paper concludes with an analysis of the proposed methods utilizing Mixtral-8x7B and Mixtral-8x7B-Instruct fashions. Outcomes are supplied for skilled recall (proven in Determine 2), mannequin compression algorithms (proven in Desk 1), and inference latency in varied {hardware} setups (proven in Desk 2). The findings point out a major enhance in technology velocity on consumer-grade {hardware}, making massive MoE fashions extra accessible for analysis and growth.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to affix our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, LinkedIn Group, Twitter, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Should you like our work, you’ll love our publication..
![]()
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.
[ad_2]
Source link


