
[ad_1]
Within the evolving panorama of synthetic intelligence, the problem of enabling language fashions, particularly transformers, to successfully course of and perceive sequences of various lengths has emerged as a essential space of analysis. The idea of size generalization performs an important function in numerous purposes, akin to pure language processing and algorithmic reasoning. It refers back to the potential of a mannequin to precisely deal with longer take a look at sequences based mostly on its coaching on shorter ones. This ability can considerably enhance the mannequin’s effectiveness and general usefulness.
A breakthrough on this discipline has been achieved by a crew from Google DeepMind, who’ve developed a novel method that considerably advances the state of size generalization in transformers. Their analysis on the decimal addition job—a seemingly easy but profoundly difficult downside for AI—has unveiled a way that mixes the revolutionary use of place encodings with a strategic knowledge format to push the boundaries of what transformers can perceive and course of.
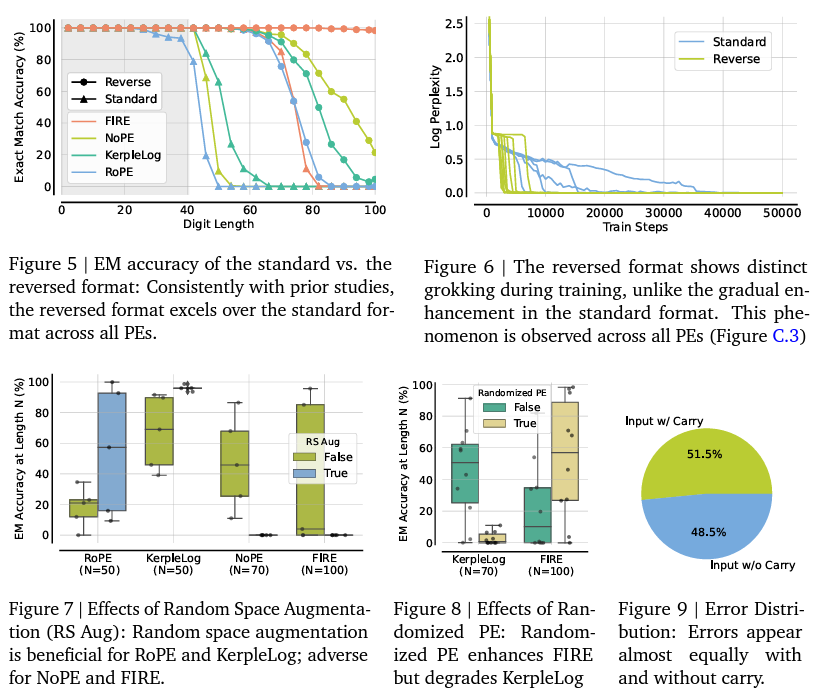
The FIRE place encoding is on the core of their methodology, which, when paired with randomized place encodings in a reversed knowledge format, has demonstrated a exceptional capability for transformers to generalize effectively past the lengths seen throughout their coaching. This mix, a departure from conventional approaches, faucets into the inherent strengths of transformers in understanding positional relationships and sequence dependencies, thereby enabling them to deal with for much longer sequences with a excessive diploma of accuracy.
The impression of this analysis is underscored by the notable outcomes it achieved. The crew’s mannequin, educated on as much as 40 digits, efficiently generalized to sequences of 100 numbers, reaching greater than 98% accuracy. This efficiency, representing a size extension ratio of two.5x—the best recognized to this point for text-based transformers as well as duties—marks a major leap ahead. It demonstrates the potential for transformers to exceed earlier limitations and highlights the essential function of knowledge format and place encoding in attaining optimum size generalization.
Moreover, this research brings to mild the nuanced challenges of size generalization. Regardless of the sturdy efficiency, the researchers noticed that the mannequin’s generalization capabilities have been delicate to random weight initialization and coaching knowledge order. This fragility factors to the complexity of attaining constant size generalization throughout totally different settings and underscores the significance of ongoing analysis to refine and stabilize these good points.
In conclusion, the work of the Google DeepMind crew represents a major milestone within the quest to reinforce the size generalization capabilities of transformers. By reimagining the interaction between place encoding and knowledge formatting, they’ve addressed a longstanding problem and opened new avenues for exploration. Their success lays the groundwork for future developments within the discipline. These promising transformers are extra versatile in dealing with various sequence lengths and extra dependable throughout a wider vary of purposes. This analysis not solely expands the theoretical understanding of transformers but in addition paves the way in which for sensible improvements in AI, driving the capabilities of language fashions to know and work together with the world round them.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and Google Information. Be part of our 37k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Enhancing Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link


