
[ad_1]
Introduction
Welcome into the world of Transformers, the deep studying mannequin that has remodeled Pure Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines perceive language, from translating texts to analyzing sentiments. On this journey, we’ll uncover the core ideas behind Transformers: consideration mechanisms, encoder-decoder structure, multi-head consideration, and extra. With Python code snippets, you’ll dive into sensible implementation, gaining a hands-on understanding of Transformers.
Studying Goals
Understanding transformers and their significance in pure language processing.
Study consideration mechanism, its variants, and the way it permits transformers to seize contextual data successfully.
Study basic elements of the transformer mannequin, together with encoder-decoder structure, positional encoding, multi-head consideration, and feed-forward networks.
Implement transformer elements utilizing Python code snippets, permitting for sensible experimentation and understanding.
Discover and perceive superior ideas equivalent to BERT and GPT with their purposes in numerous NLP duties.
This text was printed as part of the Information Science Blogathon.
Understanding Consideration Mechanism
Consideration mechanism is an interesting idea in neural networks, particularly on the subject of duties like NLP. It’s like giving the mannequin a highlight, permitting it to deal with sure elements of the enter sequence whereas ignoring others, very similar to how we people take note of particular phrases or phrases when understanding a sentence.
Now, let’s dive deeper into a specific kind of consideration mechanism known as self-attention, also called intra-attention. Think about you’re studying a sentence, and your mind routinely highlights the vital phrases or phrases to understand the that means. That’s primarily what self-attention does in neural networks. It permits every phrase within the sequence to “listen” to different phrases, together with itself, to grasp the context higher.
How Self-attention Works?
Right here’s how self-attention works with a easy instance:
Contemplate the sentence: “The cat sat on the mat.
Embedding
First, the mannequin embeds every phrase within the enter sequence right into a high-dimensional vector illustration. This embedding course of permits the mannequin to seize semantic similarities between phrases.
Question, Key, and Worth Vectors
Subsequent, the mannequin computes three vectors for every phrase within the sequence: the Question vector, the Key vector, and the Worth vector. Throughout coaching, the mannequin learns these vectors, and every serves a definite objective. Question Vector represents the phrase’s question, i.e., what the mannequin is in search of within the sequence. Key Vector represents the phrase’s key, i.e., what different phrases within the sequence ought to take note of and Worth Vector represents the phrase’s worth, i.e., the knowledge that the phrase contributes to the output.
Consideration Scores
As soon as the mannequin computes the Question, Key, and Worth vectors for every phrase, it calculates consideration scores for each pair of phrases within the sequence. That is sometimes achieved by taking the dot product of the Question and Key vectors, which assesses the similarity between the phrases.
SoftMax Normalization
The eye scores are then normalized utilizing the softmax perform to acquire consideration weights. These weights symbolize how a lot consideration every phrase ought to pay to different phrases within the sequence. Phrases with larger consideration weights are deemed extra essential for the duty being carried out.
Weighted Sum
Lastly, the weighted sum of the Worth vectors is computed utilizing the eye weights. This produces the output of the self-attention mechanism for every phrase within the sequence, capturing the contextual data from different phrases.
Right here’s a easy rationalization to calculate consideration scores:
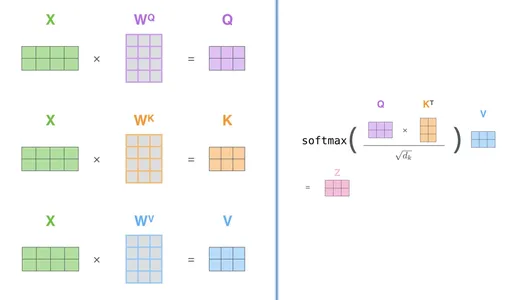
Now, let’s see how this works in code:
#set up pytorch
!pip set up torch==2.2.1+cu121
#import libraries
import torch
import torch.nn.purposeful as F
# Instance enter sequence
input_sequence = torch.tensor([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]])
# Generate random weights for Key, Question, and Worth matrices
random_weights_key = torch.randn(input_sequence.measurement(-1), input_sequence.measurement(-1))
random_weights_query = torch.randn(input_sequence.measurement(-1), input_sequence.measurement(-1))
random_weights_value = torch.randn(input_sequence.measurement(-1), input_sequence.measurement(-1))
# Compute Key, Question, and Worth matrices
key = torch.matmul(input_sequence, random_weights_key)
question = torch.matmul(input_sequence, random_weights_query)
worth = torch.matmul(input_sequence, random_weights_value)
# Compute consideration scores
attention_scores = torch.matmul(question, key.T) / torch.sqrt(torch.tensor(question.measurement(-1),
dtype=torch.float32))
# Apply softmax to acquire consideration weights
attention_weights = F.softmax(attention_scores, dim=-1)
# Compute weighted sum of Worth vectors
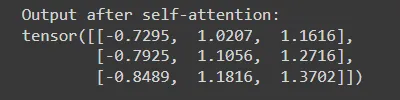
output = torch.matmul(attention_weights, worth)
print(“Output after self-attention:”)
print(output)
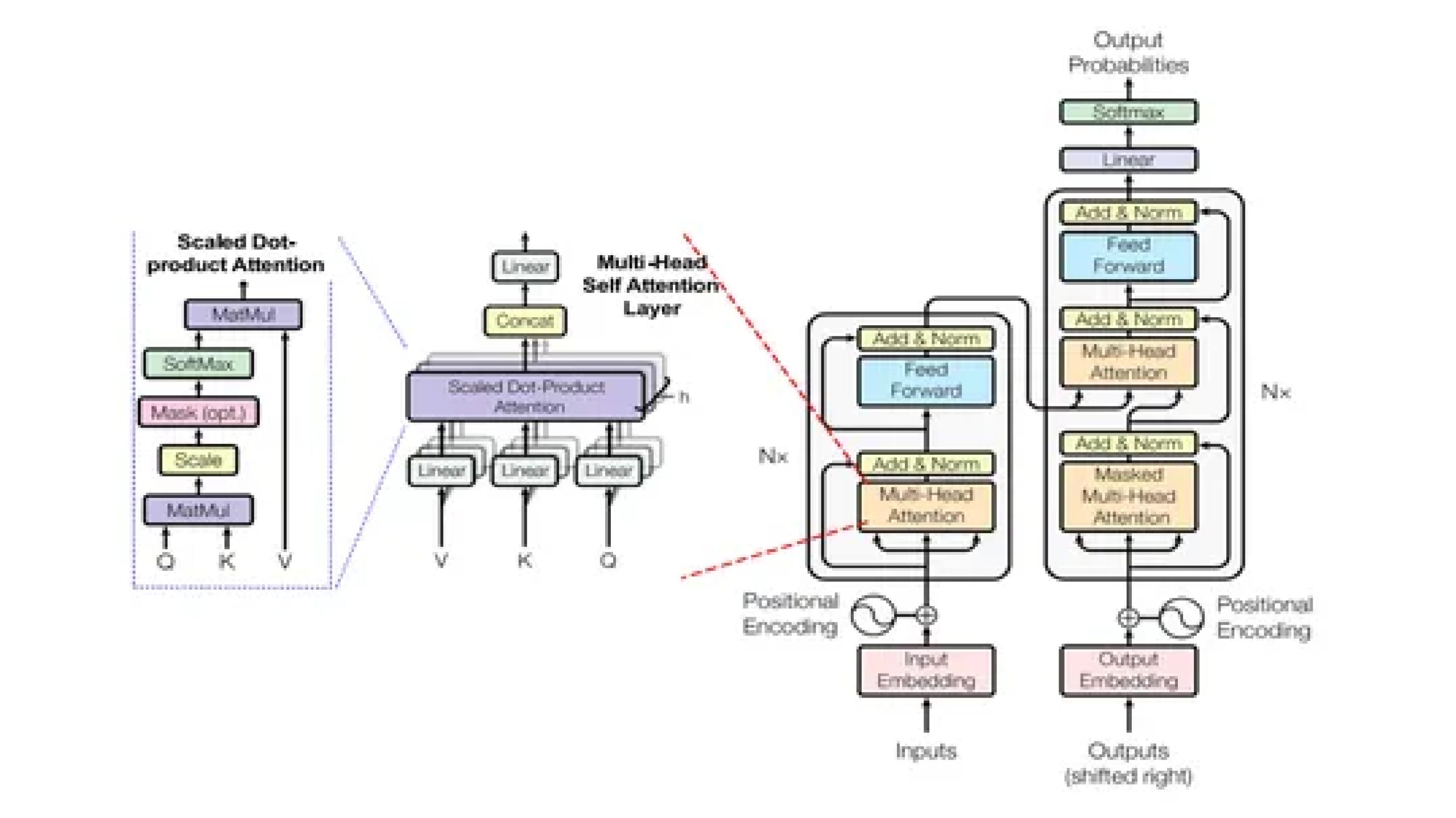
Fundamentals of Transformer Mannequin
Earlier than we dive into the intricate workings of the Transformer mannequin, let’s take a second to understand its groundbreaking structure. As we’ve mentioned earlier, the Transformer mannequin has reshaped the panorama of pure language processing (NLP) by introducing a novel method that revolves round self-attention mechanisms. Within the following sections, we’ll unravel the core elements of the Transformer mannequin, shedding gentle on its encoder-decoder structure, positional encoding, multi-head consideration, and feed-forward networks.
Encoder-Decoder Structure
On the coronary heart of the Transformer lies its encoder-decoder structure—a symbiotic relationship between two key elements tasked with processing enter sequences and producing output sequences, respectively. Every layer inside each the encoder and decoder homes equivalent sub-layers, comprising self-attention mechanisms and feed-forward networks. This structure not solely facilitates complete understanding of enter sequences but additionally permits the technology of contextually wealthy output sequences.
Positional Encoding
Regardless of its prowess, the Transformer mannequin lacks an inherent understanding of the sequential order of components—a shortcoming addressed by positional encoding. By imbuing enter embeddings with positional data, positional encoding permits the mannequin to discern the relative positions of components inside a sequence. This nuanced understanding is important for capturing the temporal dynamics of language and facilitating correct comprehension.
Multi-Head Consideration
One of many defining options of the Transformer mannequin is its potential to collectively attend to completely different elements of an enter sequence—a feat made doable by multi-head consideration. By splitting Question, Key, and Worth vectors into a number of heads and performing unbiased self-attention computations, the mannequin features a nuanced perspective of the enter sequence, enriching its illustration with various contextual data.
Feed-Ahead Networks
Akin to the human mind’s potential to course of data in parallel, every layer throughout the Transformer mannequin homes a feed-forward community—a flexible part able to capturing intricate relationships between components in a sequence. By using linear transformations and non-linear activation features, feed-forward networks empower the mannequin to navigate the advanced semantic panorama of language, facilitating strong comprehension and technology of textual content.
Detailed Clarification of Transformer Elements
For implementation, first run codes of Positional Encoding, Multi-Head Consideration Mechanism and Feed-Ahead Networks, then Encoder, Decoder and Transformer Structure.
#import libraries
import math
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.purposeful as F
Positional Encoding
Within the Transformer mannequin, positional encoding is an important part that injects details about the place of tokens into the enter embeddings. Not like recurrent neural networks (RNNs) or convolutional neural networks (CNNs), Transformers lack inherent information of token positions as a consequence of their permutation-invariant property. Positional encoding addresses this limitation by offering the mannequin with positional data, enabling it to course of sequences of their right order.
Idea of Positional Encoding:
Positional encoding is usually added to the enter embeddings earlier than they’re fed into the Transformer mannequin. It consists of a set of sinusoidal features with completely different frequencies and phases, permitting the mannequin to distinguish between tokens based mostly on their positions within the sequence.
The method for positional encoding is as follows:
Suppose you’ve got an enter sequence of size L and require the place of the ktℎ object inside this sequence. The positional encoding is given by sine and cosine features of various frequencies:
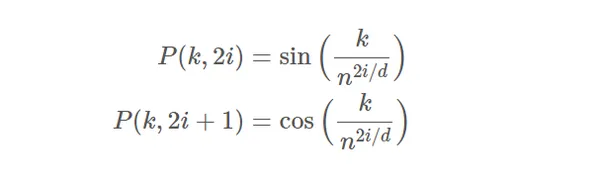
The place:
ok: Place of an object within the enter sequence, 0≤ok<L/2
d: Dimension of the output embedding area
P(ok,j): Place perform for mapping a place ok within the enter sequence to index (ok,j) of the positional matrix
n: Person-defined scalar, set to 10,000 by the authors of Consideration Is All You Want.
i: Used for mapping to column indices 0≤i<d/2, with a single worth of i maps to each sine and cosine features
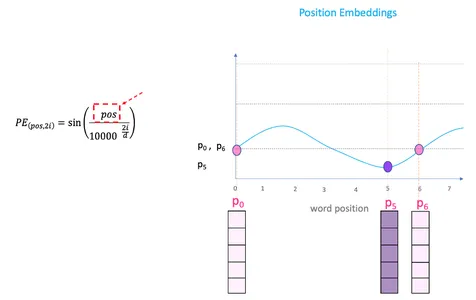
Totally different Positional Encoding Schemes
There are numerous positional encoding schemes utilized in Transformers, every with its benefits and drawbacks:
Mounted Positional Encoding: On this scheme, the positional encodings are pre-defined and glued for all sequences. Whereas easy and environment friendly, fastened positional encodings could not seize advanced patterns in sequences.
Discovered Positional Encoding: Alternatively, positional encodings may be realized throughout coaching, permitting the mannequin to adaptively seize positional data from the information. Discovered positional encodings supply higher flexibility however require extra parameters and computational assets.
Implementation of Positional Encoding
Let’s implement positional encoding in Python:
# implementation of PositionalEncoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
tremendous(PositionalEncoding, self).__init__()
# Compute positional encodings
pe = torch.zeros(max_len, d_model)
place = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(
torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(place * div_term)
pe[:, 1::2] = torch.cos(place * div_term)
pe = pe.unsqueeze(0)
self.register_buffer(‘pe’, pe)
def ahead(self, x):
x = x + x + self.pe[:, :x.size(1)]
return x
# Instance utilization
d_model = 512
max_len = 100
num_heads = 8
# Positional encoding
pos_encoder = PositionalEncoding(d_model, max_len)
# Instance enter sequence
input_sequence = torch.randn(5, max_len, d_model)
# Apply positional encoding
input_sequence = pos_encoder(input_sequence)
print(“Positional Encoding of enter sequence:”)
print(input_sequence.form)

Multi-Head Consideration Mechanism
Within the Transformer structure, the multi-head consideration mechanism is a key part that allows the mannequin to take care of completely different elements of the enter sequence concurrently. It permits the mannequin to seize advanced dependencies and relationships throughout the sequence, resulting in improved efficiency in duties equivalent to language translation, textual content technology, and sentiment evaluation.
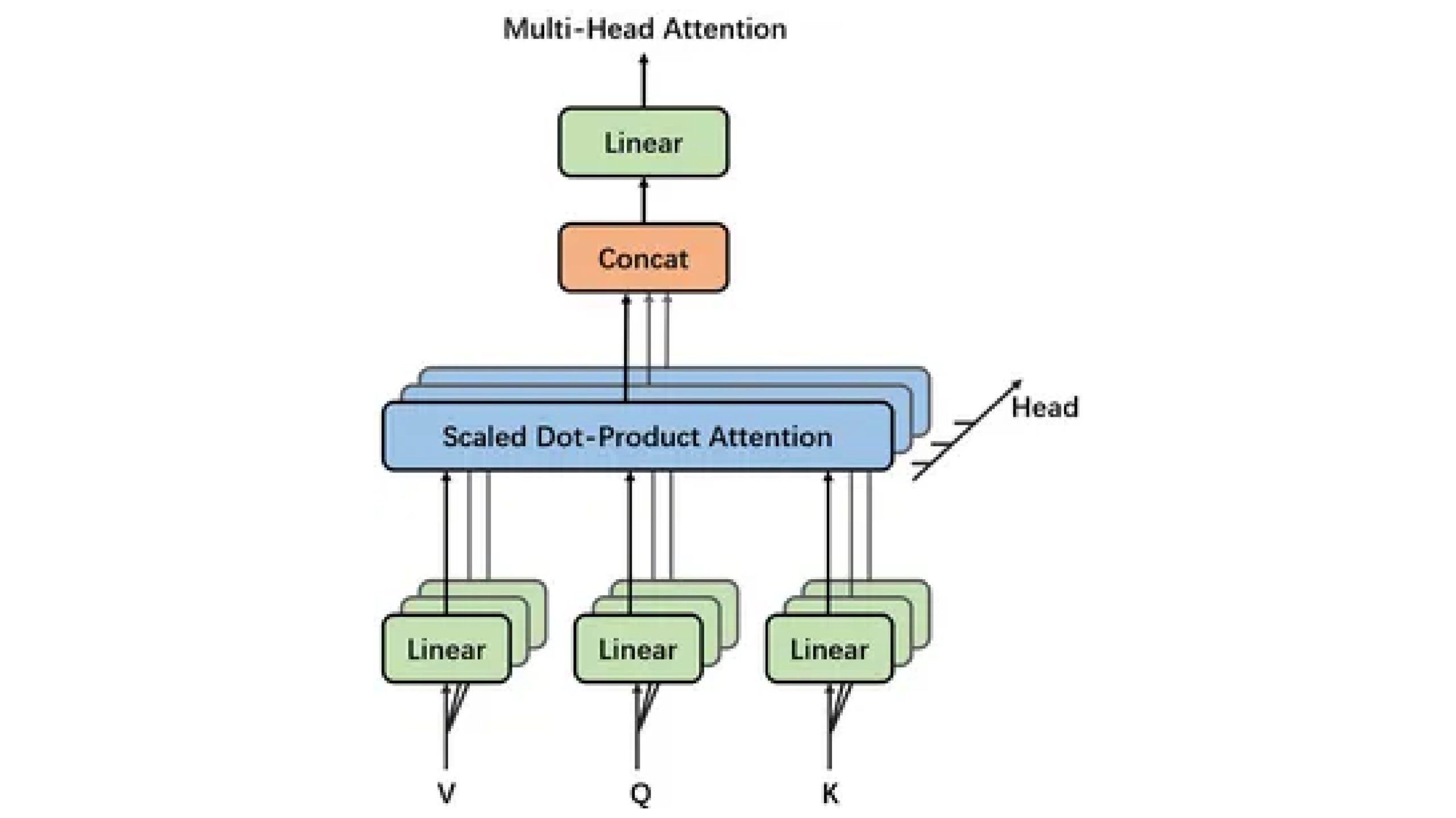
Significance of Multi-Head Consideration
The multi-head consideration mechanism gives a number of benefits:
Parallelization: By attending to completely different elements of the enter sequence in parallel, multi-head consideration considerably hastens computation, making it extra environment friendly than conventional consideration mechanisms.
Enhanced Representations: Every consideration head focuses on completely different elements of the enter sequence, permitting the mannequin to seize various patterns and relationships. This results in richer and extra strong representations of the enter, enhancing the mannequin’s potential to grasp and generate textual content.
Improved Generalization: Multi-head consideration permits the mannequin to take care of each native and international dependencies throughout the sequence, resulting in improved generalization throughout numerous duties and domains.
Computation of Multi-Head Consideration:
Let’s break down the steps concerned in computing multi-head consideration:
Linear Transformation: The enter sequence undergoes learnable linear transformations to challenge it into a number of lower-dimensional representations, referred to as “heads.” Every head focuses on completely different elements of the enter, permitting the mannequin to seize various patterns.
Scaled Dot-Product Consideration: Every head independently computes consideration scores between the question, key, and worth representations of the enter sequence. This step entails calculating the similarity between tokens and their context, scaled by the sq. root of the depth of the mannequin. The ensuing consideration weights spotlight the significance of every token relative to others.
Concatenation and Linear Projection: The eye outputs from all heads are concatenated and linearly projected again to the unique dimensionality. This course of combines the insights from a number of heads, enhancing the mannequin’s potential to grasp advanced relationships throughout the sequence.
Implementation with Code
Let’s translate the idea into code:
# Code implementation of Multi-Head Consideration
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
tremendous(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
# Linear projections for question, key, and worth
self.query_linear = nn.Linear(d_model, d_model)
self.key_linear = nn.Linear(d_model, d_model)
self.value_linear = nn.Linear(d_model, d_model)
# Output linear projection
self.output_linear = nn.Linear(d_model, d_model)
def split_heads(self, x):
batch_size, seq_length, d_model = x.measurement()
return x.view(batch_size, seq_length, self.num_heads, self.depth).transpose(1, 2)
def ahead(self, question, key, worth, masks=None):
# Linear projections
question = self.query_linear(question)
key = self.key_linear(key)
worth = self.value_linear(worth)
# Break up heads
question = self.split_heads(question)
key = self.split_heads(key)
worth = self.split_heads(worth)
# Scaled dot-product consideration
scores = torch.matmul(question, key.transpose(-2, -1)) / math.sqrt(self.depth)
# Apply masks if supplied
if masks just isn’t None:
scores += scores.masked_fill(masks == 0, -1e9)
# Compute consideration weights and apply softmax
attention_weights = torch.softmax(scores, dim=-1)
# Apply consideration to values
attention_output = torch.matmul(attention_weights, worth)
# Merge heads
batch_size, _, seq_length, d_k = attention_output.measurement()
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size,
seq_length, self.d_model)
# Linear projection
attention_output = self.output_linear(attention_output)
return attention_output
# Instance utilization
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048
# Multi-head consideration
multihead_attn = MultiHeadAttention(d_model, num_heads)
# Instance enter sequence
input_sequence = torch.randn(5, max_len, d_model)
# Multi-head consideration
attention_output= multihead_attn(input_sequence, input_sequence, input_sequence)
print(“attention_output form:”, attention_output.form)

Feed-Ahead Networks
Within the context of Transformers, feed-forward networks play an important function in processing data and extracting options from the enter sequence. They function the spine of the mannequin, facilitating the transformation of representations between completely different layers.
Function of Feed-Ahead Networks
The feed-forward community inside every Transformer layer is chargeable for making use of non-linear transformations to the enter representations. It permits the mannequin to seize advanced patterns and relationships throughout the knowledge, facilitating the educational of higher-level options.
Construction and Functioning of the Feed-Ahead Layer
The feed-forward layer consists of two linear transformations separated by a non-linear activation perform, sometimes ReLU (Rectified Linear Unit). Let’s break down the construction and functioning:
Linear Transformation 1: The enter representations are projected right into a higher-dimensional area utilizing a learnable weight matrix
Non-Linear Activation: The output of the primary linear transformation is handed by a non-linear activation perform, equivalent to ReLU. This introduces non-linearity into the mannequin, enabling it to seize advanced patterns and relationships throughout the knowledge.
Linear Transformation 2: The output of the activation perform is then projected again into the unique dimensional area utilizing one other learnable weight matrix
Implementation with Code
Let’s implement the feed-forward community in Python:
# code implementation of Feed Ahead
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
tremendous(FeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def ahead(self, x):
x = self.relu(self.linear1(x))
x = self.linear2(x)
return x
# Instance utilization
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048
# Multi-head consideration
multihead_attn = MultiHeadAttention(d_model, num_heads)
# Feed-forward community
ff_network = FeedForward(d_model, d_ff)
# Instance enter sequence
input_sequence = torch.randn(5, max_len, d_model)
# Multi-head consideration
attention_output= multihead_attn(input_sequence, input_sequence, input_sequence)
# Feed-forward community
output_ff = ff_network(attention_output)
print(‘input_sequence’,input_sequence.form)
print(“output_ff”, output_ff.form)

Encoder
The encoder performs an important function in processing enter sequences within the Transformer mannequin. Its major activity is to transform enter sequences into significant representations that seize important details about the enter.
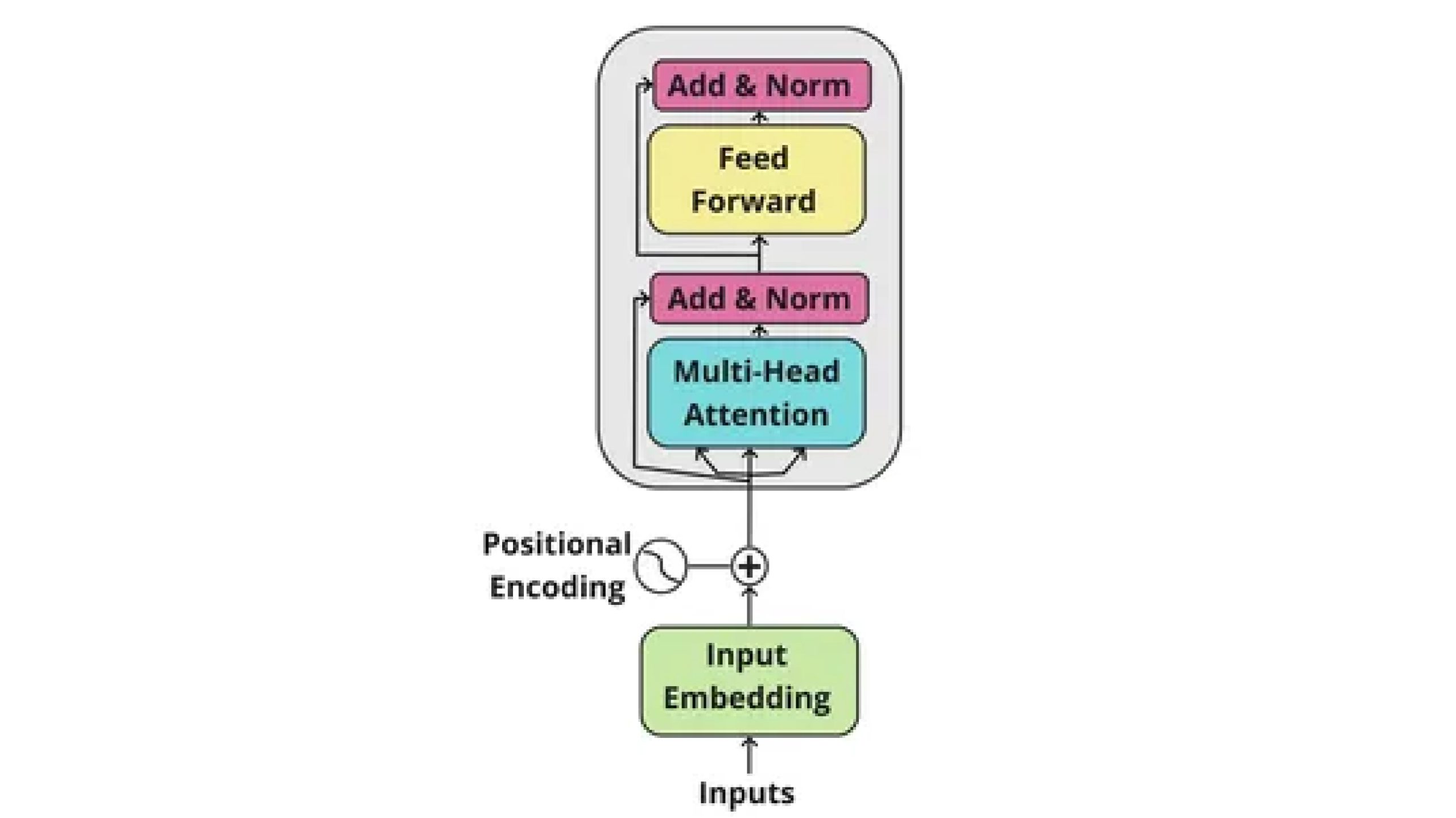
Construction and Functioning of Every Encoder Layer
The encoder consists of a number of layers, every containing the next elements in sequential order: enter embeddings, positional encoding, multi-head self-attention mechanism, and a position-wise feed-forward community.
Enter Embeddings: We first convert the enter sequence into dense vector representations referred to as enter embeddings. We map every phrase within the enter sequence to a high-dimensional vector area utilizing pre-trained phrase embeddings or realized embeddings throughout coaching.
Positional Encoding: We add positional encoding to the enter embeddings to include the sequential order data of the enter sequence. This permits the mannequin to tell apart between the positions of phrases within the sequence, overcoming the dearth of sequential data in conventional neural networks.
Multi-Head Self-Consideration Mechanism: After positional encoding, the enter embeddings cross by a multi-head self-attention mechanism. This mechanism permits the encoder to weigh the significance of various phrases within the enter sequence based mostly on their relationships with different phrases. By attending to related elements of the enter sequence, the encoder can seize long-range dependencies and semantic relationships.
Place-Smart Feed-Ahead Community: Following the self-attention mechanism, the encoder applies a position-wise feed-forward community to every place independently. This community consists of two linear transformations separated by a non-linear activation perform, sometimes a ReLU. It helps seize advanced patterns and relationships throughout the enter sequence.
Implementation with Code
Let’s dive into the Python code for implementing the encoder layers with enter embeddings and positional encoding:
# code implementation of ENCODER
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
tremendous(EncoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def ahead(self, x, masks):
# Self-attention layer
attention_output= self.self_attention(x, x,
x, masks)
attention_output = self.dropout(attention_output)
x = x + attention_output
x = self.norm1(x)
# Feed-forward layer
feed_forward_output = self.feed_forward(x)
feed_forward_output = self.dropout(feed_forward_output)
x = x + feed_forward_output
x = self.norm2(x)
return x
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048
# Multi-head consideration
encoder_layer = EncoderLayer(d_model, num_heads, d_ff, 0.1)
# Instance enter sequence
input_sequence = torch.randn(1, max_len, d_model)
# Multi-head consideration
encoder_output= encoder_layer(input_sequence, None)
print(“encoder output form:”, encoder_output.form)

Decoder
Within the Transformer mannequin, the decoder performs an important function in producing output sequences based mostly on the encoded representations of enter sequences. It receives the encoded enter sequence from the encoder and makes use of it to provide the ultimate output sequence.
Operate of the Decoder
The decoder’s major perform is to generate output sequences whereas attending to related elements of the enter sequence and beforehand generated tokens. It makes use of the encoded representations of the enter sequence to grasp the context and make knowledgeable choices concerning the subsequent token to generate.
Decoder Layer and Its Elements
The decoder layer consists of the next elements:
Output Embedding Shifted Proper: Earlier than processing the enter sequence, the mannequin shifts the output embeddings proper by one place. This ensures that every token within the decoder receives the right context from beforehand generated tokens throughout coaching.
Positional Encoding: Just like the encoder, the mannequin provides positional encoding to the output embeddings to include the sequential order of tokens. This encoding helps the decoder differentiate between tokens based mostly on their place within the sequence.
Masked Multi-Head Self-Consideration Mechanism: The decoder employs a masked multi-head self-attention mechanism to take care of related elements of the enter sequence and beforehand generated tokens. Throughout coaching, the mannequin applies a masks to forestall attending to future tokens, making certain that every token can solely attend to previous tokens.
Encoder-Decoder Consideration Mechanism: Along with the masked self-attention mechanism, the decoder additionally incorporates an encoder-decoder consideration mechanism. This mechanism permits the decoder to take care of related elements of the enter sequence, aiding within the technology of output tokens knowledgeable by the enter context.
Place-Smart Feed-Ahead Community: Following the eye mechanisms, the decoder applies a position-wise feed-forward community to every token independently. This community captures advanced patterns and relationships throughout the enter and beforehand generated tokens, contributing to the technology of correct output sequences.
Implementation with Code
# code implementation of DECODER
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
tremendous(DecoderLayer, self).__init__()
self.masked_self_attention = MultiHeadAttention(d_model, num_heads)
self.enc_dec_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def ahead(self, x, encoder_output, src_mask, tgt_mask):
# Masked self-attention layer
self_attention_output= self.masked_self_attention(x, x, x, tgt_mask)
self_attention_output = self.dropout(self_attention_output)
x = x + self_attention_output
x = self.norm1(x)
# Encoder-decoder consideration layer
enc_dec_attention_output= self.enc_dec_attention(x, encoder_output,
encoder_output, src_mask)
enc_dec_attention_output = self.dropout(enc_dec_attention_output)
x = x + enc_dec_attention_output
x = self.norm2(x)
# Feed-forward layer
feed_forward_output = self.feed_forward(x)
feed_forward_output = self.dropout(feed_forward_output)
x = x + feed_forward_output
x = self.norm3(x)
return x
# Outline the DecoderLayer parameters
d_model = 512 # Dimensionality of the mannequin
num_heads = 8 # Variety of consideration heads
d_ff = 2048 # Dimensionality of the feed-forward community
dropout = 0.1 # Dropout chance
batch_size = 1 # Batch Measurement
max_len = 100 # Max size of Sequence
# Outline the DecoderLayer occasion
decoder_layer = DecoderLayer(d_model, num_heads, d_ff, dropout)
src_mask = torch.rand(batch_size, max_len, max_len) > 0.5
tgt_mask = torch.tril(torch.ones(max_len, max_len)).unsqueeze(0) == 0
# Cross the enter tensors by the DecoderLayer
output = decoder_layer(input_sequence, encoder_output, src_mask, tgt_mask)
# Output form
print(“Output form:”, output.form)

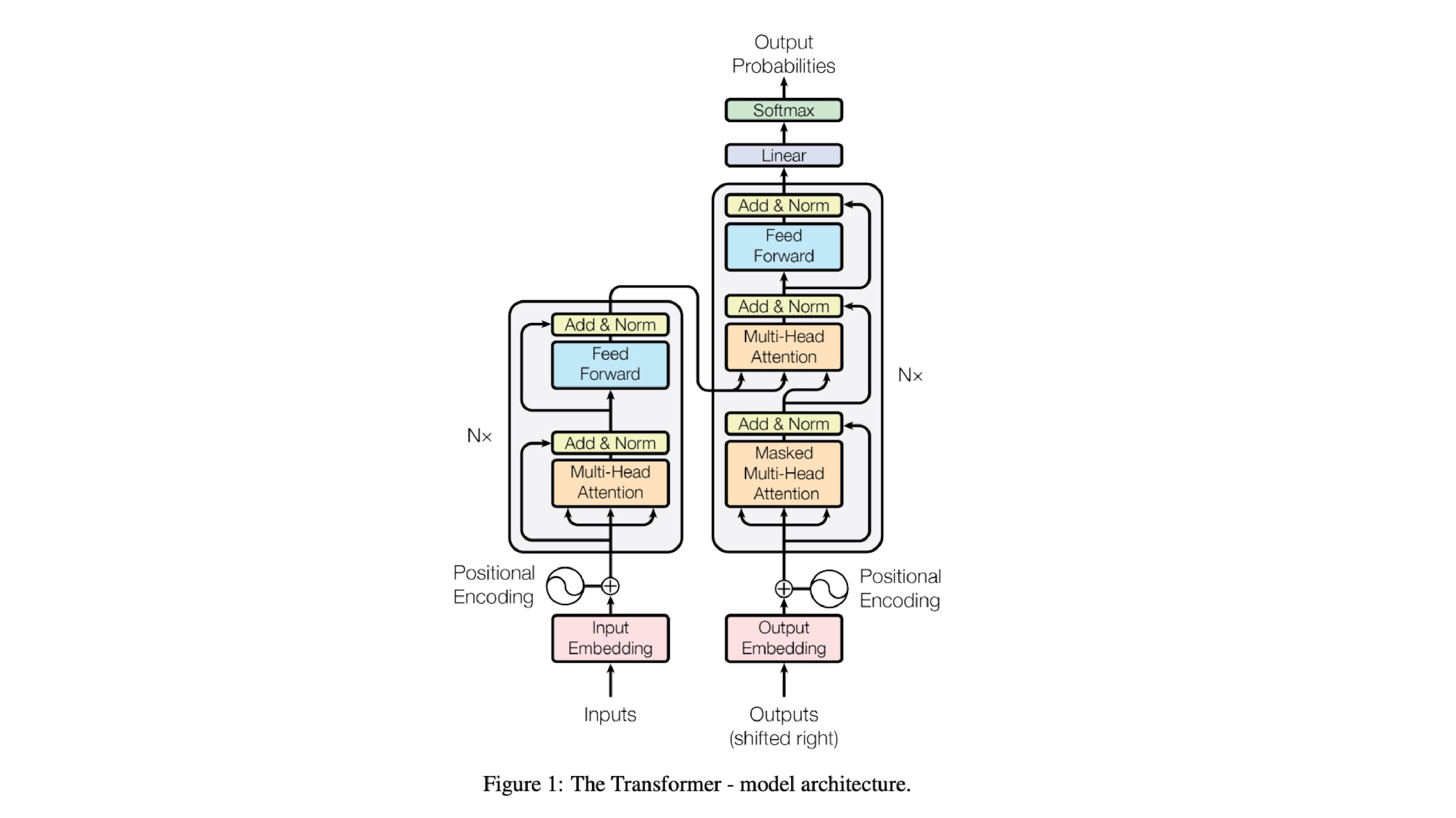
Transformer Mannequin Structure
The Transformer mannequin structure is the end result of varied elements mentioned in earlier sections. Let’s carry collectively the information of encoders, decoders, consideration mechanisms, positional encoding, and feed-forward networks to grasp how the entire Transformer mannequin is structured and features.
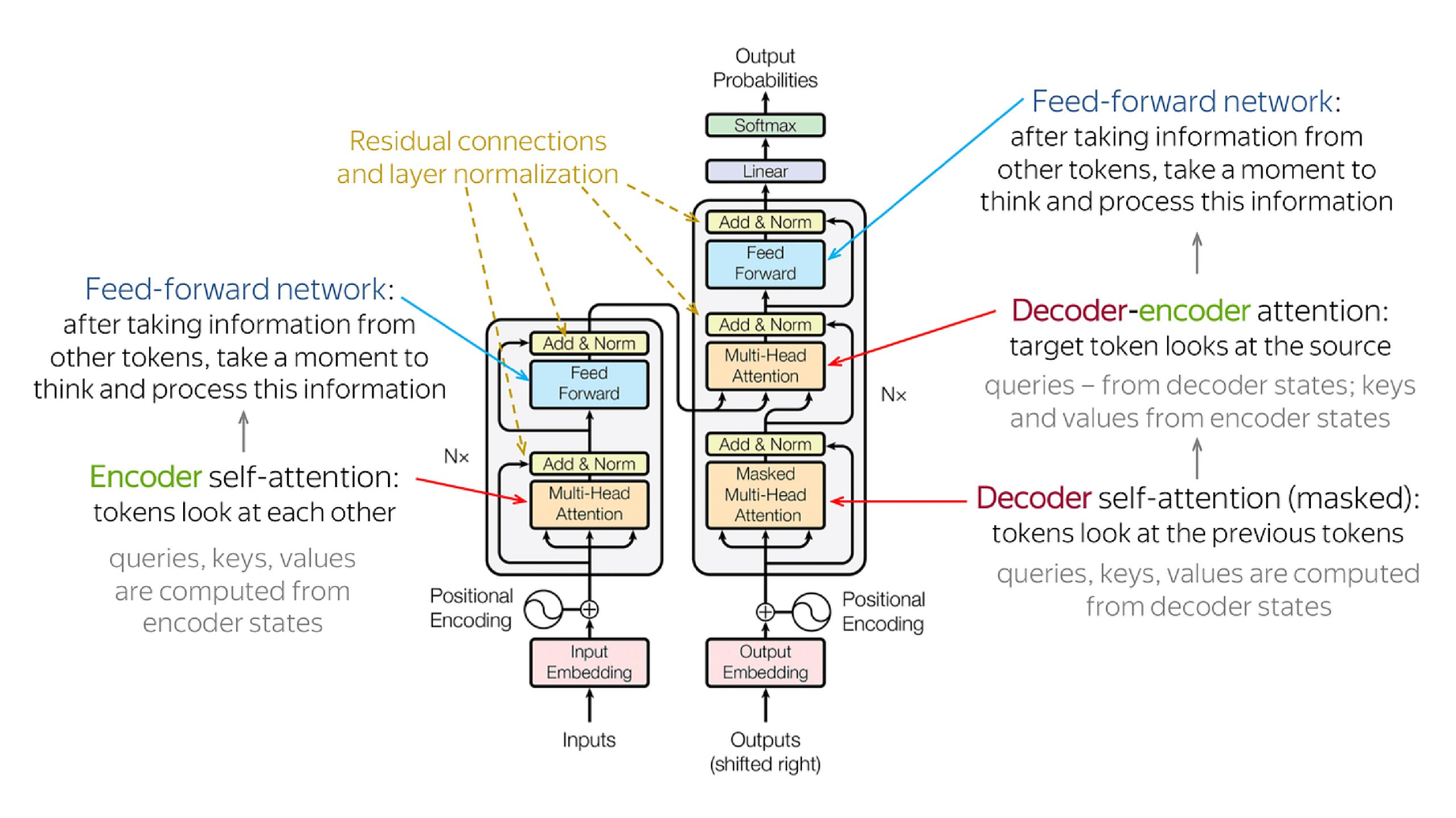
Overview of Transformer Mannequin
At its core, the Transformer mannequin consists of encoder and decoder modules stacked collectively to course of enter sequences and generate output sequences. Right here’s a high-level overview of the structure:
Encoder
The encoder module processes the enter sequence, extracting options and making a wealthy illustration of the enter.
It includes a number of encoder layers, every containing self-attention mechanisms and feed-forward networks.
The self-attention mechanism permits the mannequin to take care of completely different elements of the enter sequence concurrently, capturing dependencies and relationships.
We add positional encoding to the enter embeddings to supply details about the place of tokens within the sequence.
Decoder
The decoder module takes the output of the encoder as enter and generates the output sequence.
Just like the encoder, it consists of a number of decoder layers, every containing self-attention, encoder-decoder consideration, and feed-forward networks.
Along with self-attention, the decoder incorporates encoder-decoder consideration to take care of the enter sequence whereas producing the output.
Just like the encoder, we add positional encoding to the enter embeddings to supply positional data.
Connection and Normalization
Between every layer in each the encoder and decoder modules, residual connections are adopted by layer normalization.
These mechanisms facilitate the circulate of gradients by the community and assist stabilize coaching.
The entire Transformer mannequin is constructed by stacking a number of encoder and decoder layers on high of one another. Every layer independently processes the enter sequence, permitting the mannequin to be taught hierarchical representations and seize intricate patterns within the knowledge. The encoder passes its output to the decoder, which generates the ultimate output sequence based mostly on the enter.
Implementation of Transformer Mannequin
Let’s implement the entire Transformer mannequin in Python:
# implementation of TRANSFORMER
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff,
max_len, dropout):
tremendous(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.linear = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.measurement(1)
nopeak_mask = (1 – torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def ahead(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
encoder_embedding = self.encoder_embedding(src)
en_positional_encoding = self.positional_encoding(encoder_embedding)
src_embedded = self.dropout(en_positional_encoding)
decoder_embedding = self.decoder_embedding(tgt)
de_positional_encoding = self.positional_encoding(decoder_embedding)
tgt_embedded = self.dropout(de_positional_encoding)
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.linear(dec_output)
return output
# Instance usecase
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_len = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers,
d_ff, max_len, dropout)
# Generate random pattern knowledge
src_data = torch.randint(1, src_vocab_size, (5, max_len)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (5, max_len)) # (batch_size, seq_length)
transformer(src_data, tgt_data[:, :-1]).form

Coaching and Analysis of Mannequin
Coaching a Transformer mannequin entails optimizing its parameters to attenuate a loss perform, sometimes utilizing gradient descent and backpropagation. As soon as educated, the mannequin’s efficiency is evaluated utilizing numerous metrics to evaluate its effectiveness in fixing the goal activity.
Coaching Course of
Gradient Descent and Backpropagation:
Throughout coaching, enter sequences are fed into the mannequin, and output sequences are generated.
Evaluating the mannequin’s predictions with the bottom fact entails utilizing a loss perform, equivalent to cross-entropy loss, to measure the disparity between predicted and precise values.
Gradient descent is used to replace the mannequin’s parameters within the path that minimizes the loss.
The optimizer adjusts the parameters based mostly on these gradients, updating them iteratively to enhance mannequin efficiency.
Studying Charge Scheduling:
Studying fee scheduling strategies could also be utilized to regulate the educational fee throughout coaching dynamically.
Widespread methods embody warmup schedules, the place the educational fee begins low and steadily will increase, and decay schedules, the place the educational fee decreases over time.
Analysis Metrics
Perplexity:
Perplexity is a typical metric used to judge the efficiency of language fashions, together with Transformers.
It measures how nicely the mannequin predicts a given sequence of tokens.
Decrease perplexity values point out higher efficiency, with the perfect worth being near the vocabulary measurement.
BLEU Rating:
The BLEU (Bilingual Analysis Understudy) rating is usually used to judge the standard of machine-translated textual content.
It compares the generated translation to a number of reference translations supplied by human translators.
BLEU scores vary from 0 to 1, with larger scores indicating higher translation high quality.
Implementation of Coaching and Analysis
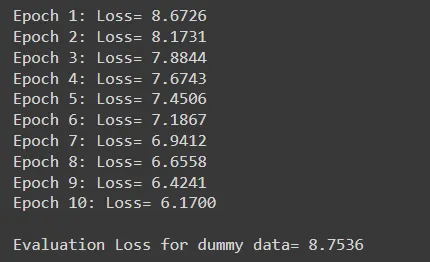
Let’s do a primary code implementation for coaching and evaluating a Transformer mannequin utilizing PyTorch:
# coaching and analysis of transformer mannequin
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# Coaching loop
transformer.practice()
for epoch in vary(10):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:]
.contiguous().view(-1))
loss.backward()
optimizer.step()
print(f”Epoch {epoch+1}: Loss= {loss.merchandise():.4f}”)
#Dummy Information
src_data = torch.randint(1, src_vocab_size, (5, max_len)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (5, max_len)) # (batch_size, seq_length)
# Analysis loop
transformer.eval()
with torch.no_grad():
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:]
.contiguous().view(-1))
print(f”nEvaluation Loss for dummy knowledge= {loss.merchandise():.4f}”)
Superior Matters and Purposes
Transformers have sparked a plethora of superior ideas and purposes in pure language processing (NLP). Let’s delve into a few of these subjects, together with completely different consideration variants, BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and their sensible purposes.
Totally different Consideration Variants
Consideration mechanisms are on the coronary heart of transformer fashions, permitting them to deal with related elements of the enter sequence. Proposals for numerous consideration variants goal to reinforce the capabilities of transformers.
Scaled Dot-Product Consideration: The usual consideration mechanism used within the unique Transformer mannequin. It computes consideration scores because the dot product of question and key vectors, scaled by the sq. root of the dimensionality.
Multi-Head Consideration: A robust extension of consideration that employs a number of consideration heads to seize completely different elements of the enter sequence concurrently. Every head learns completely different consideration patterns, enabling the mannequin to attend to varied elements of the enter in parallel.
Relative Positional Encoding: Introduces relative positional encoding to seize the relative positions of tokens extra successfully. This variant enhances the mannequin’s potential to grasp the sequential relationships between tokens.
BERT (Bidirectional Encoder Representations from Transformers)
BERT, a landmark transformer-based mannequin, has had a profound impression on NLP. It undergoes pre-training on giant corpora of textual content knowledge utilizing masked language modeling and subsequent sentence prediction goals. BERT learns deep contextualized representations of phrases, capturing bidirectional context and enabling it to carry out nicely on a variety of downstream NLP duties.
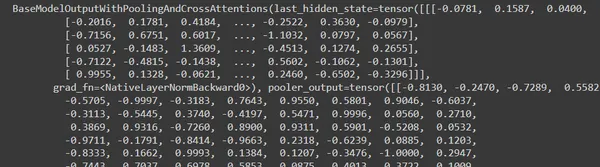
Code Snippet – BERT Mannequin:
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)
mannequin = BertModel.from_pretrained(‘bert-base-uncased’)
inputs = tokenizer(“Good day, world!”, return_tensors=”pt”)
outputs = mannequin(**inputs)
print(outputs)
GPT (Generative Pre-trained Transformer)
GPT, a transformer-based mannequin, is famend for its generative capabilities. Not like BERT, which is bidirectional, GPT makes use of a decoder-only structure and autoregressive coaching to generate coherent and contextually related textual content. Researchers and builders have efficiently utilized GPT in numerous duties equivalent to textual content completion, summarization, dialogue technology, and extra.
Code Snippet – GPT Mannequin:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained(‘gpt2’)
mannequin = GPT2LMHeadModel.from_pretrained(‘gpt2’)
input_text = “As soon as upon a time, ”
inputs=tokenizer(input_text,return_tensors=”pt”)
output=tokenizer.decode(
mannequin.generate(
**inputs,
max_new_tokens=100,
)[0],
skip_special_tokens=True
)
input_ids = tokenizer(input_text, return_tensors=”pt”)
print(output)

Conclusion
Transformers have revolutionized Pure Language Processing (NLP) with their potential to seize context and perceive language intricacies. By means of consideration mechanisms, encoder-decoder structure, and multi-head consideration, they’ve enabled duties like machine translation and sentiment evaluation on a scale by no means seen earlier than. As we proceed to discover fashions like BERT and GPT, it’s clear that Transformers are on the forefront of language understanding and technology. Their impression on NLP is profound, and the journey of discovery with Transformers guarantees to unveil much more outstanding developments within the discipline.
Key Takeaways
Central to Transformers, self-attention permits fashions to deal with vital elements of the enter sequence, enhancing understanding.
Transformers make the most of this structure to course of enter and generate output, with every layer containing self-attention and feed-forward networks.
By means of Python code snippets, we gained a hands-on understanding of implementing transformer elements.
Transformers excel in machine translation, textual content summarization, sentiment evaluation, and extra, dealing with large-scale datasets effectively.
Extra Sources
For these taken with additional studying and studying, listed below are some beneficial assets:
Analysis Papers:
Tutorials:
GitHub Repository:
Incessantly Requested Questions
A. Transformers are a deep studying mannequin in Pure Language Processing (NLP) that effectively seize long-range dependencies in sequential knowledge by processing enter sequences in parallel, not like conventional fashions.
A. Transformers use an consideration mechanism to deal with related enter sequence elements for correct predictions. It computes consideration scores between tokens, calculating weighted sums by a number of layers, successfully capturing contextual data.
A. Transformer-based fashions equivalent to BERT, GPT, and T5 discover widespread use in Pure Language Processing (NLP) duties equivalent to sentiment evaluation, machine translation, textual content summarization, and query answering.
A. A transformer mannequin consists of encoder-decoder structure, positional encoding, multi-head consideration mechanism, and feed-forward networks. It processes enter sequences, understands token order, and enhances representational capability and efficiency with nonlinear transformations.
A. Implement transformers utilizing deep studying libraries like PyTorch and TensorFlow, which supply pre-trained fashions and APIs for customized fashions. Study transformer fundamentals by tutorials, documentation assets, and on-line programs, gaining hands-on expertise in NLP duties.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
[ad_2]
Source link


