
[ad_1]
Retrieval-augmented language fashions usually retrieve solely brief chunks from a corpus, limiting general doc context. This decreases their capability to adapt to adjustments on the planet state and incorporate long-tail data. Current retrieval-augmented approaches additionally want fixing. The one we deal with is that the majority current strategies retrieve just a few brief, contiguous textual content chunks, which limits their capability to signify and leverage large-scale discourse construction. That is significantly related for thematic questions that require integrating data from a number of textual content elements, akin to understanding a complete guide.
Current developments in Massive Language Fashions (LLMs) reveal their effectiveness as standalone data shops, encoding details inside their parameters. Wonderful-tuning downstream duties additional enhances their efficiency. Nevertheless, challenges come up in updating LLMs with evolving world data. Another method includes indexing textual content in an info retrieval system and presenting retrieved info to LLMs for present domain-specific data. Current retrieval-augmented strategies are restricted to retrieving solely brief, contiguous textual content chunks, hindering the illustration of large-scale discourse construction, which is essential for thematic questions and a complete understanding of texts like within the NarrativeQA dataset.
The researchers from Stanford College suggest RAPTOR, an progressive indexing and retrieval system designed to handle limitations in current strategies. RAPTOR makes use of a tree construction to seize a textual content’s high-level and low-level particulars. It clusters textual content chunks, generates summaries for clusters, and constructs a tree from the underside up. This construction allows loading totally different ranges of textual content chunks into LLMs context, facilitating environment friendly and efficient answering of questions at numerous ranges. The important thing contribution is utilizing textual content summarization for retrieval augmentation, enhancing context illustration throughout totally different scales, as demonstrated in experiments on lengthy doc collections.
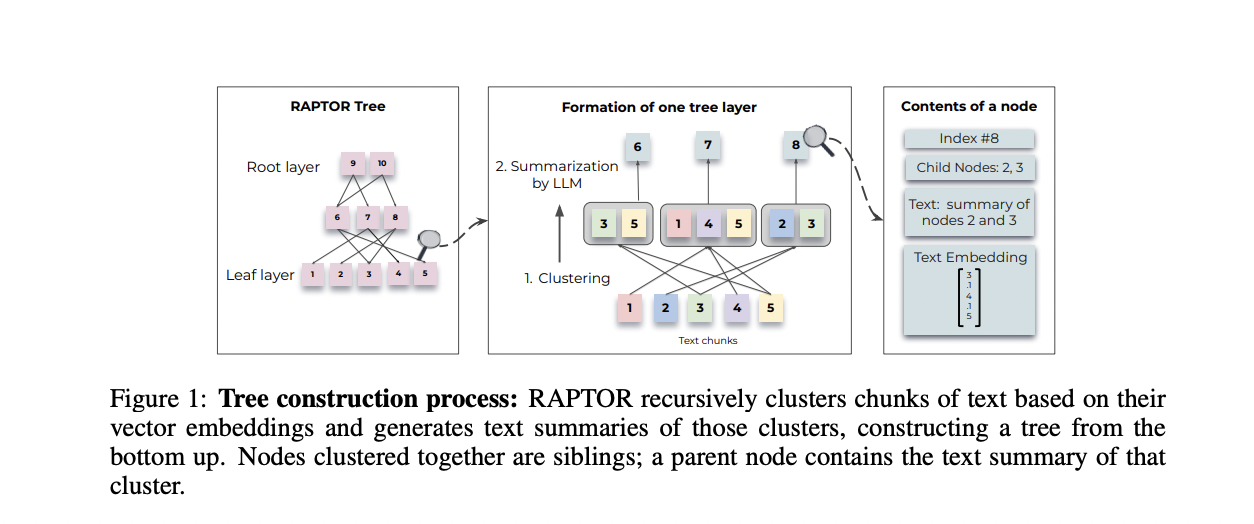
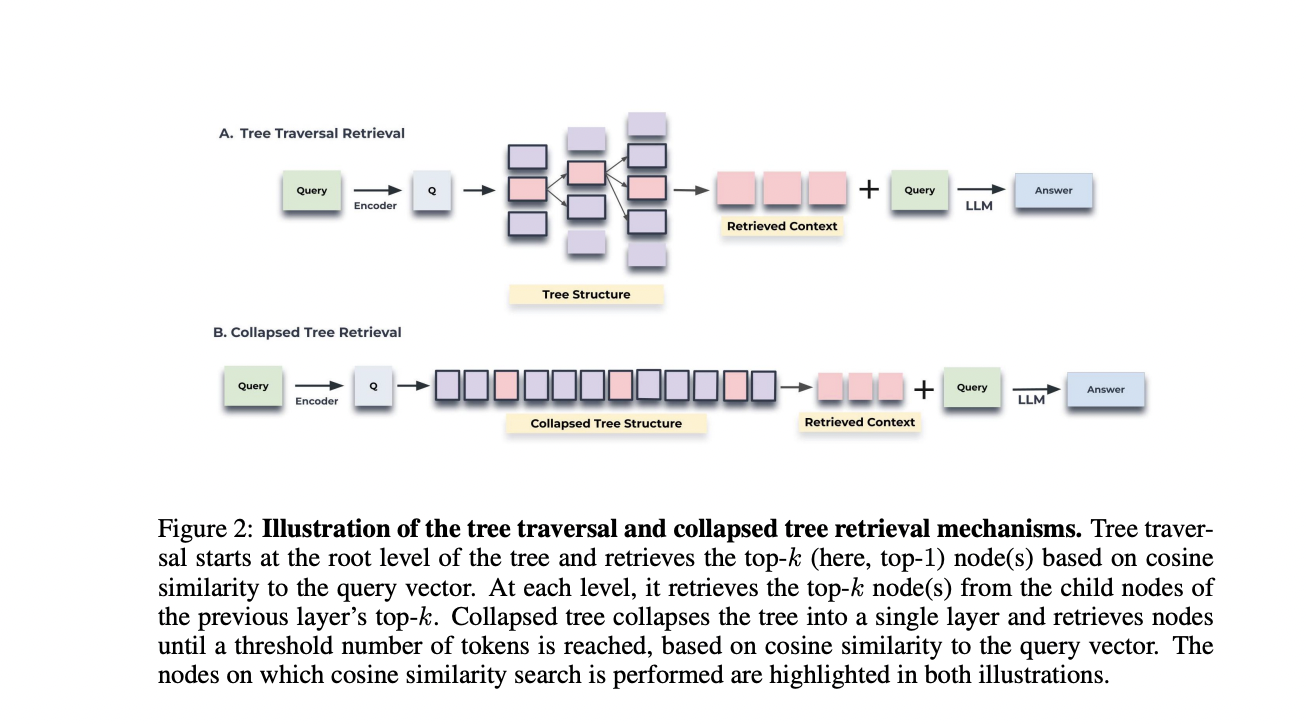
RAPTOR addresses studying semantic depth and connection points by establishing a recursive tree construction that captures each broad thematic comprehension and granular particulars. The method includes segmenting the retrieval corpus into chunks, embedding them utilizing SBERT, and clustering them with a smooth clustering algorithm primarily based on Gaussian Combination Fashions (GMMs) and Uniform Manifold Approximation and Projection (UMAP). The ensuing tree construction permits for environment friendly querying by way of tree traversal or a collapsed tree method, enabling retrieval of related info at totally different ranges of specificity.
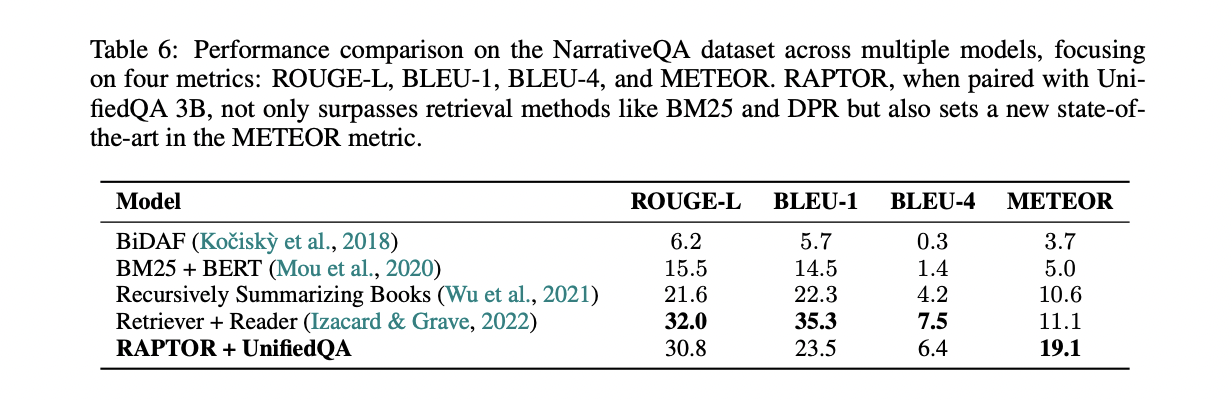
RAPTOR outperforms baseline strategies throughout three question-answering datasets: NarrativeQA, QASPER, and QuALITY. Management comparisons utilizing UnifiedQA 3B because the reader present constant superiority of RAPTOR over BM25 and DPR. Paired with GPT-4, RAPTOR achieves state-of-the-art outcomes on QASPER and QuALITY datasets, showcasing its effectiveness in dealing with thematic and multi-hop queries. The contribution of the tree construction is validated, demonstrating the importance of upper-level nodes in capturing a broader understanding and enhancing retrieval capabilities.

In conclusion, Stanford College researchers introduce RAPTOR, an progressive tree-based retrieval system that enhances the data of huge language fashions with contextual info throughout totally different abstraction ranges. RAPTOR constructs a hierarchical tree construction by way of recursive clustering and summarization, facilitating the efficient synthesis of data from various sections of retrieval corpora. Managed experiments showcase RAPTOR’s superiority over conventional strategies, establishing new benchmarks in numerous question-answering duties. Total, RAPTOR proves to be a promising method for advancing the capabilities of language fashions by way of enhanced contextual retrieval.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
![]()
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]
Source link



Innovate Faster with a 3D Printer
3d printer price [url=http://www.3d-ruyter53.ru/]http://www.3d-ruyter53.ru/[/url] .
Hi there
My name is Diana Rossenga and I represent Musgrave Group, Ireland’s largest wholesaler. We’re always on the lookout for fresh opportunities that can help expand our offerings while promoting quality products from other companies around the globe.
We find your product line quite impressive and believe it aligns perfectly with our business model.
I’ve been trying to locate your export department with no luck yet. Can you pass this message to your CEO or Export dep.
Mrs Diana Rossenga
Musgrave Group
Cork,
Ireland
Email: bookings@musgraveimports.com