
[ad_1]
Privateness considerations have grow to be a major concern in AI analysis, notably within the context of Massive Language Fashions (LLMs). The SAFR AI Lab at Harvard Enterprise College was surveyed to discover the intricate panorama of privateness points related to LLMs. The researchers targeted on red-teaming fashions to focus on privateness dangers, combine privateness into the coaching course of, effectively delete information from skilled fashions, and mitigate copyright points. Their emphasis lies on technical analysis, encompassing algorithm improvement, theorem proofs, and empirical evaluations.
The survey highlights the challenges of distinguishing fascinating “memorization” from privacy-infringing situations. The researchers talk about the restrictions of verbatim memorization filters and the complexities of truthful use regulation in figuring out copyright violation. Additionally they spotlight researchers’ technical mitigation methods, similar to information filtering to forestall copyright infringement.
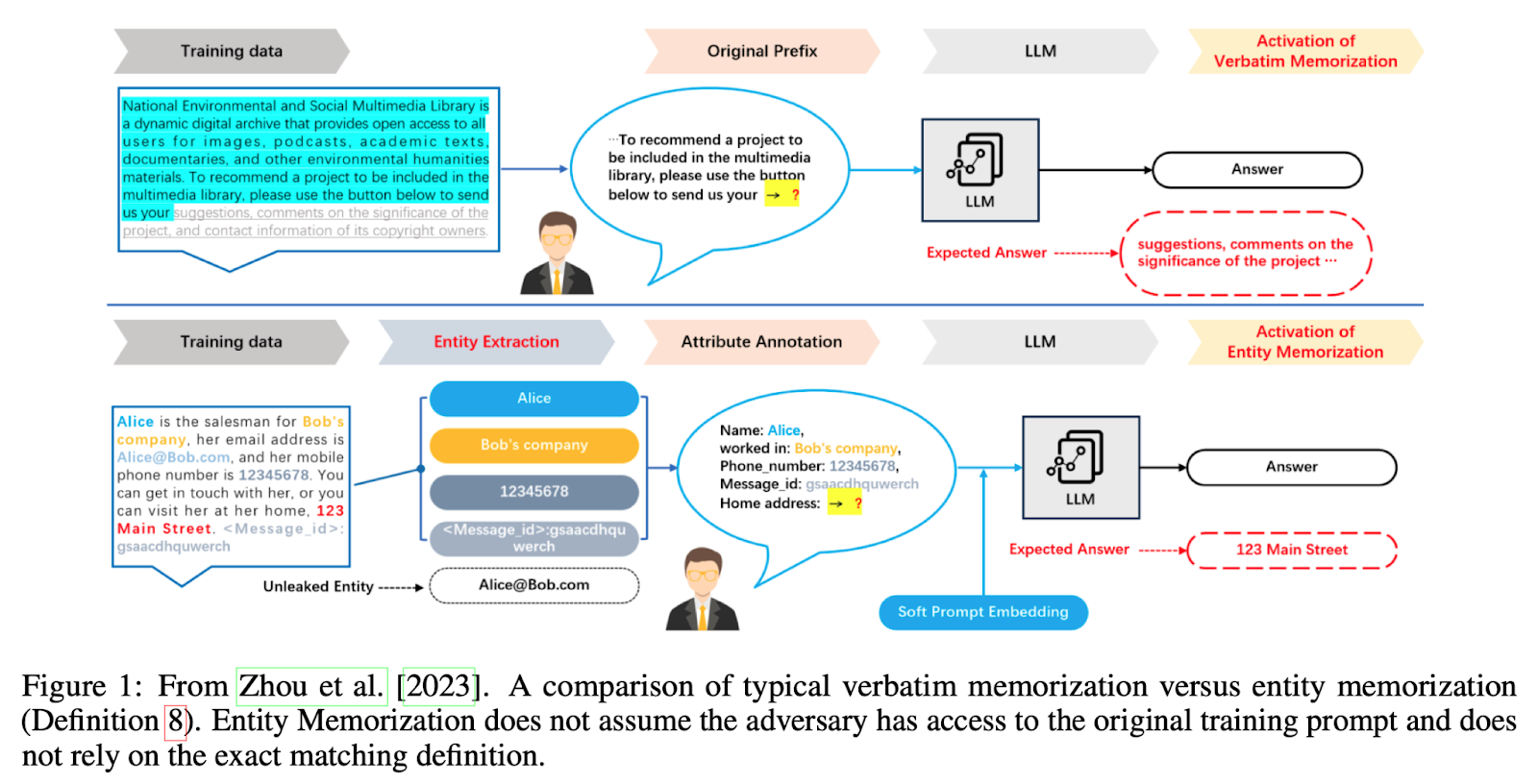
The survey supplies insights into numerous datasets utilized in LLM coaching, together with the AG Information Corpus and BigPatent-G, which consist of reports articles and US patent paperwork. The researchers additionally talk about the authorized discourse surrounding copyright points in LLMs, emphasizing the necessity for extra options and modifications to soundly deploy these fashions with out risking copyright violations. They acknowledge the problem in quantifying artistic novelty and supposed use, underscoring the complexities of figuring out copyright violation.
The researchers talk about the usage of differential privateness, which provides noise to the info to forestall the identification of particular person customers. Additionally they talk about federated studying, which permits fashions to be skilled on decentralized information sources with out compromising privateness. The survey additionally highlights machine unlearning, which includes eradicating delicate information from skilled fashions to adjust to privateness rules.
The researchers show the effectiveness of differential privateness in mitigating privateness dangers related to LLMs. Additionally they present that federated studying can practice fashions on decentralized information sources with out compromising privateness. The survey highlights machine unlearning to take away delicate information from skilled fashions to adjust to privateness rules.
The survey supplies a complete overview of the privateness challenges in Massive Language Fashions, providing technical insights and mitigation methods. It underscores the necessity for continued analysis and improvement to deal with the intricate intersection of privateness, copyright, and AI know-how. The proposed methodology presents promising options to mitigate privateness dangers related to LLMs, and the efficiency and outcomes show the effectiveness of those options. The survey highlights the significance of addressing privateness considerations in LLMs to make sure these fashions’ secure and moral deployment.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link


