
[ad_1]
Synthetic intelligence has seen outstanding developments with the event of enormous language fashions (LLMs). Due to methods like reinforcement studying from human suggestions (RLHF), they’ve considerably improved performing varied duties. Nonetheless, the problem lies in synthesizing novel content material solely primarily based on human suggestions.
One of many core challenges in advancing LLMs is optimizing their studying course of from human suggestions. This suggestions is obtained via a course of the place fashions are introduced with prompts and generate responses, with human raters indicating their preferences. The aim is to refine the fashions’ responses to align extra intently with human preferences. Nonetheless, this technique requires many interactions, posing a bottleneck for speedy mannequin enchancment.
Present methodologies for coaching LLMs contain passive exploration, the place fashions generate responses primarily based on predefined prompts with out actively in search of to optimize the educational from suggestions. One such strategy is to make use of Thompson sampling, the place queries are generated primarily based on uncertainty estimates represented by an epistemic neural community (ENN). The selection of exploration scheme is vital, and double Thompson sampling has proven efficient in producing high-performing queries. Others embody Boltzmann Exploration and Infomax. Whereas these strategies have been instrumental within the preliminary phases of LLM growth, they have to be optimized for effectivity, usually requiring an impractical variety of human interactions to realize notable enhancements.
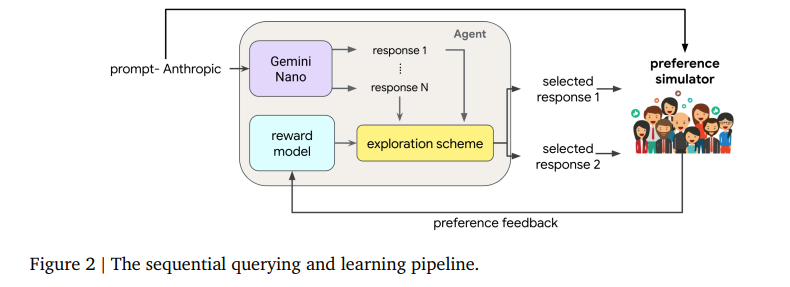
Researchers at Google Deepmind and Stanford College have launched a novel strategy to lively exploration, using double Thompson sampling and ENN for question era. This technique permits the mannequin to actively hunt down suggestions that’s most informative for its studying, considerably lowering the variety of queries wanted to realize high-performance ranges. The ENN offers uncertainty estimates that information the exploration course of, enabling the mannequin to make extra knowledgeable selections on which queries to current for suggestions.
Within the experimental setup, brokers generate responses to 32 prompts, forming queries evaluated by a desire simulator. The suggestions is used to refine their reward fashions on the finish of every epoch. Brokers discover the response area by deciding on essentially the most informative pairs from a pool of 100 candidates, using a multi-layer perceptron (MLP) structure with two hidden layers of 128 models every or an ensemble of 10 MLPs for epistemic neural networks (ENN).

The outcomes spotlight the effectiveness of double Thompson sampling (TS) over different exploration strategies like Boltzmann exploration and infomax, particularly in using uncertainty estimates for improved question choice. Whereas Boltzmann’s exploration reveals promise at decrease temperatures, double TS constantly outperforms others by making higher use of uncertainty estimates from the ENN reward mannequin. This strategy accelerates the educational course of and demonstrates the potential for environment friendly exploration to dramatically scale back the amount of human suggestions required, marking a major advance in coaching giant language fashions.
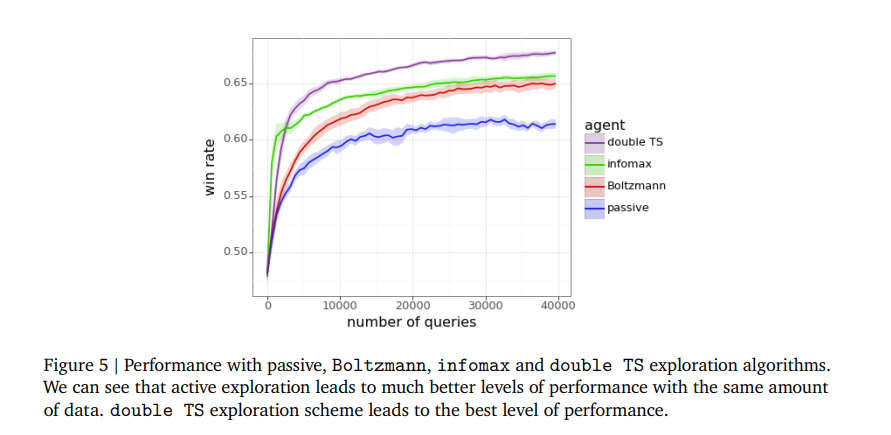
In conclusion, this analysis showcases the potential for environment friendly exploration to beat the constraints of conventional coaching strategies. The staff has opened new avenues for speedy and efficient mannequin enhancement by leveraging superior exploration algorithms and uncertainty estimates. This strategy guarantees to speed up innovation in LLMs and highlights the significance of optimizing the educational course of for the broader development of synthetic intelligence.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
![]()
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link


