
[ad_1]
Creating giant language fashions (LLMs) represents a cutting-edge frontier. These fashions, educated to parse, generate, and interpret human language, are more and more changing into the spine of assorted digital instruments and platforms, enhancing all the things from easy automated writing assistants to advanced conversational brokers. Coaching these refined fashions is an endeavor that calls for substantial computational sources and huge datasets. The hunt for effectivity on this coaching course of is pushed by the necessity to mitigate the environmental influence and handle the escalating computational prices related to the ever-growing datasets.
The standard technique of indiscriminately feeding gargantuan datasets to fashions, hoping to seize the huge expanse of linguistic nuances, is inefficient and unsustainable. This technique’s brute-force method is being reevaluated in gentle of latest methods that search to boost the educational effectivity of LLMs by fastidiously deciding on coaching information. These methods intention to make sure that each bit of knowledge utilized in coaching packs the utmost attainable tutorial worth, thus optimizing the coaching effectivity.
Latest improvements by researchers of Google DeepMind, College of California San Diego, and Texas A&M College have led to the event of refined information choice strategies that intention to raise mannequin efficiency by specializing in the standard and variety of the coaching information. These strategies make use of superior algorithms to evaluate the potential influence of particular person information factors on the mannequin’s studying trajectory. By prioritizing information that provides all kinds of linguistic options and deciding on examples deemed to have a excessive studying worth, these methods search to make the coaching course of more practical and environment friendly.
Two standout methods on this realm are ASK-LLM and DENSITY sampling. ASK-LLM leverages the mannequin’s zero-shot reasoning capabilities to judge the usefulness of every coaching instance. This revolutionary method permits the mannequin to self-select its coaching information based mostly on a predetermined set of high quality standards. In the meantime, DENSITY sampling focuses on guaranteeing a large illustration of linguistic options within the coaching set, aiming to reveal the mannequin to as broad a spectrum of the language as attainable. This technique seeks to optimize the protection side of the info, guaranteeing that the mannequin encounters a various array of linguistic situations throughout its coaching part.
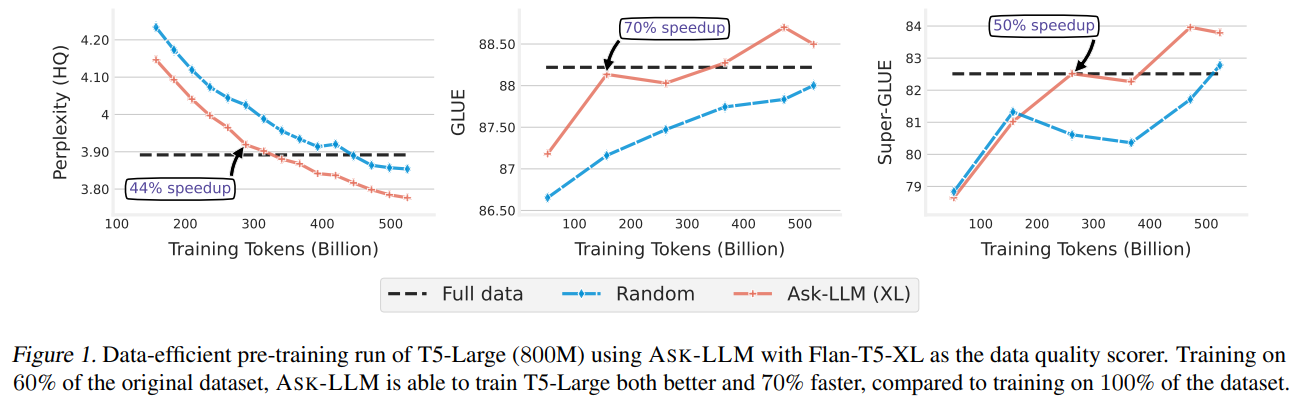
ASK-LLM, for instance, has proven that it could actually considerably enhance mannequin capabilities, even when a big portion of the preliminary dataset is excluded from the coaching course of. This method hastens the coaching timeline and suggests creating high-performing fashions with considerably much less information. The effectivity positive factors from these methods counsel a promising course for the way forward for LLM coaching, doubtlessly decreasing the environmental footprint and computational calls for of growing refined AI fashions.
ASK-LLM’s course of includes evaluating coaching examples by the lens of the mannequin’s present data, successfully permitting the mannequin to prioritize information that it ‘believes’ will improve its studying probably the most. This self-referential information analysis technique marks a major shift from conventional information choice methods, emphasizing the intrinsic high quality of knowledge. Alternatively, DENSITY sampling employs a extra quantitative measure of variety, searching for to fill within the gaps within the mannequin’s publicity to completely different linguistic phenomena by figuring out and together with underrepresented examples within the coaching set.
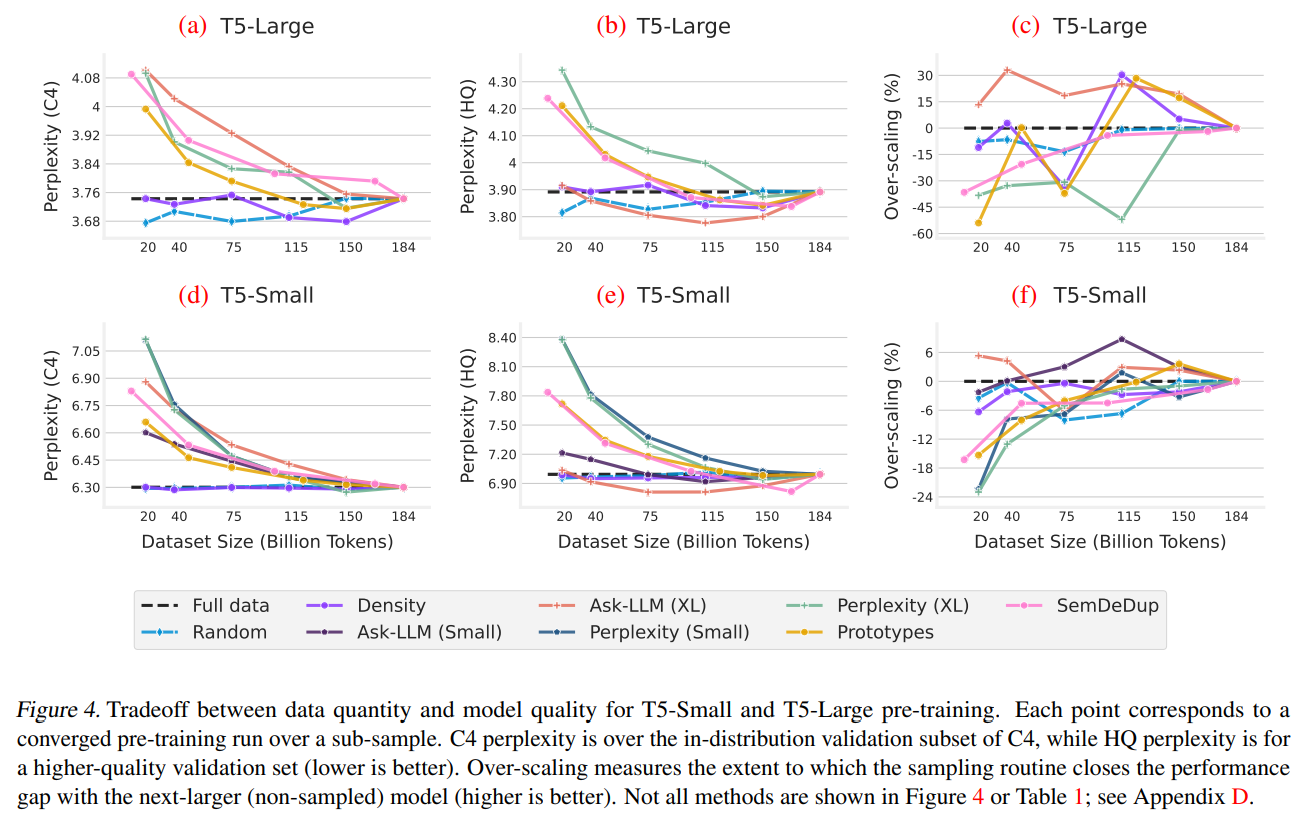
The analysis outcomes underscore the efficacy of those approaches:
Fashions educated with ASK-LLM-selected information constantly outperformed these educated with the total dataset, demonstrating the worth of quality-focused information choice.
DENSITY sampling matched the efficiency of fashions educated on full datasets by guaranteeing numerous linguistic protection, highlighting the significance of selection in coaching information.
The mixture of those strategies presents a compelling case for a extra discerning method to information choice, able to attaining superior mannequin efficiency whereas doubtlessly decreasing the useful resource necessities for LLM coaching.
In conclusion, exploring data-efficient coaching methodologies for LLMs reveals a promising avenue for enhancing AI mannequin growth. The numerous findings from this analysis embody:
The introduction of ASK-LLM and DENSITY sampling as revolutionary methods for optimizing coaching information choice.
Demonstrated enhancements in mannequin efficiency and coaching effectivity by strategic information curation.
Potential for decreasing the computational and environmental prices related to LLM coaching, aligning with broader sustainability and effectivity objectives in AI analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and Google Information. Be part of our 37k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
![]()
Hi there, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at present pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m keen about expertise and need to create new merchandise that make a distinction.
[ad_2]
Source link


